You might also like
- GR E Trabajo Grupal 8 PDFDocument5 pagesGR E Trabajo Grupal 8 PDFDavid SuquilloNo ratings yet
- Sample Midterm SolutionsDocument12 pagesSample Midterm SolutionsAnyone SomeoneNo ratings yet
- Tutorial 4 (Hypothesis Testing)Document22 pagesTutorial 4 (Hypothesis Testing)Anonymous WUQ60t100% (1)
- Glossary How Science Works Alevel Biology EdexcelDocument1 pageGlossary How Science Works Alevel Biology EdexcelMinko Saeed100% (1)
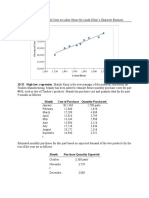
- Regression Line of Overhead Costs On LaborDocument3 pagesRegression Line of Overhead Costs On LaborElliot Richard100% (1)
- 7 EstimationDocument85 pages7 EstimationHê lô Thanh hà Tạ :DNo ratings yet
- Sampling DistDocument40 pagesSampling DistSanket SharmaNo ratings yet
- Statistical Estimation Techniques for Means, Proportions, and Sample SizesDocument41 pagesStatistical Estimation Techniques for Means, Proportions, and Sample Sizeskumlachew GebeyehuNo ratings yet
- 12 EstimatesDocument28 pages12 EstimatesAj SegumpanNo ratings yet
- Statistical InferenceDocument33 pagesStatistical Inferencedeneke100% (1)
- Interval EstimationDocument30 pagesInterval Estimationsai revanthNo ratings yet
- Estimation MethodsDocument60 pagesEstimation MethodsBehar AbdurahemanNo ratings yet
- Business Statistics CH 2Document49 pagesBusiness Statistics CH 2assenmiftahNo ratings yet
- Ch08 - Large-Sample EstimationDocument28 pagesCh08 - Large-Sample EstimationislamNo ratings yet
- Business Statistics 4Document32 pagesBusiness Statistics 4NOOR UL AIN SHAHNo ratings yet
- STAT - Day 2-2Document108 pagesSTAT - Day 2-2Anand UmarjiNo ratings yet
- 4estimation and Hypothesis Testing (DB) (Compatibility Mode)Document170 pages4estimation and Hypothesis Testing (DB) (Compatibility Mode)Mekonnen BatiNo ratings yet
- One Sample Inference: (Estimation)Document14 pagesOne Sample Inference: (Estimation)Adinaan ShaafiiNo ratings yet
- Estimation 1Document70 pagesEstimation 1Mohammed AbdelaNo ratings yet
- Making Confident DecisionsDocument37 pagesMaking Confident DecisionsSium Adnan Khan 1511153030No ratings yet
- Chap5 Estimation UploadDocument50 pagesChap5 Estimation UploadQuangtue NguyenNo ratings yet
- Interval EstimationDocument19 pagesInterval EstimationvijayrajumNo ratings yet
- Estimation NewDocument37 pagesEstimation Newmubasher akramNo ratings yet
- Chapter TwoDocument28 pagesChapter TwoDawit MekonnenNo ratings yet
- Critical Z Values and Confidence Intervals ExplainedDocument15 pagesCritical Z Values and Confidence Intervals Explainedikki123123No ratings yet
- Lecture (Chapter 7) : Estimation Procedures: Ernesto F. L. AmaralDocument33 pagesLecture (Chapter 7) : Estimation Procedures: Ernesto F. L. AmaralMarvin Yebes ArceNo ratings yet
- 03 Chapter 3 - Statistical EstimationDocument17 pages03 Chapter 3 - Statistical EstimationYohanna SisayNo ratings yet
- Statistical Inference: EstimationDocument24 pagesStatistical Inference: EstimationAdel KaadanNo ratings yet
- The Design of Research: Mcgraw-Hill/IrwinDocument33 pagesThe Design of Research: Mcgraw-Hill/IrwinnehaarunagarwalNo ratings yet
- APPLIED ENVIRONMENTAL STATISTICSDocument35 pagesAPPLIED ENVIRONMENTAL STATISTICSMawuliNo ratings yet
- Estimation of ParametersDocument35 pagesEstimation of ParameterstiffanyNo ratings yet
- Statistics and Probability Module 4 MoodleDocument6 pagesStatistics and Probability Module 4 MoodleDonnalyn Mae EscrupoloNo ratings yet
- Binomial Distributions For Sample CountsDocument38 pagesBinomial Distributions For Sample CountsVishnu VenugopalNo ratings yet
- Chapter 8 Confidence IntervalDocument14 pagesChapter 8 Confidence IntervalFadli Bakhtiar AjiNo ratings yet
- Inferential Statistics: Population vs SampleDocument9 pagesInferential Statistics: Population vs SampleLuis MolinaNo ratings yet
- Session: 27: TopicDocument62 pagesSession: 27: TopicMikias BekeleNo ratings yet
- Estimation Statistics - Point Interval Confidence Intervals Margin ErrorDocument31 pagesEstimation Statistics - Point Interval Confidence Intervals Margin ErrorAgung Nuza DwiputraNo ratings yet
- Lecture21 PracticeSheetDocument9 pagesLecture21 PracticeSheetChaudhuriSartazAllahwalaNo ratings yet
- 5.1 Lesson 5 T-Distribution - A LectureDocument5 pages5.1 Lesson 5 T-Distribution - A LectureEdrian Ranjo Guerrero100% (1)
- Estimating Population ParametersDocument52 pagesEstimating Population ParametersIsmadth2918388No ratings yet
- Sampling and EstimationDocument15 pagesSampling and EstimationPRIYADARSHI GOURAVNo ratings yet
- Chapter 6Document7 pagesChapter 6storkyddNo ratings yet
- Inferential Statistics: Estimation and Confidence IntervalsDocument19 pagesInferential Statistics: Estimation and Confidence IntervalsHasan HubailNo ratings yet
- Estimation 1Document35 pagesEstimation 1Fun Toosh345No ratings yet
- Week 6.8a With NotesDocument35 pagesWeek 6.8a With NotesL RNo ratings yet
- Distribution of Sample MeansDocument32 pagesDistribution of Sample MeansEva Elžbieta SventickaitėNo ratings yet
- ESTIMATION OF PARAMETERSDocument32 pagesESTIMATION OF PARAMETERSJade Berlyn AgcaoiliNo ratings yet
- Audit SamplingDocument18 pagesAudit SamplingAnonymous Ul3litqNo ratings yet
- Sampling Distributions and Confidence Intervals For ProportionsDocument31 pagesSampling Distributions and Confidence Intervals For ProportionsJosh PotashNo ratings yet
- Estimating Sample SizeDocument6 pagesEstimating Sample SizeAleesha MontenegroNo ratings yet
- Estimating Sample SizeDocument24 pagesEstimating Sample SizeShaira CaballesNo ratings yet
- PHPS30020 Week1 (2) - 29nov2023 (Combined Sampling Variation - SEM SEP CIs)Document24 pagesPHPS30020 Week1 (2) - 29nov2023 (Combined Sampling Variation - SEM SEP CIs)Katie NolanNo ratings yet
- Margin of ErrorDocument6 pagesMargin of ErrorFaith Febe AustriaNo ratings yet
- Module 22 Confidence Interval Estimation of The Population MeanDocument5 pagesModule 22 Confidence Interval Estimation of The Population MeanAlayka Mae Bandales LorzanoNo ratings yet
- Estimating Means and Proportions: Math Courseware SpecialistsDocument28 pagesEstimating Means and Proportions: Math Courseware SpecialistsVictoria LiendoNo ratings yet
- Bus 173 - 1Document28 pagesBus 173 - 1Mirza Asir IntesarNo ratings yet
- Interval EstimateDocument20 pagesInterval EstimateMariam Ah.No ratings yet
- L5 Sample Size CalculationDocument23 pagesL5 Sample Size CalculationMarshet SetegnNo ratings yet
- Confidence IntervalsDocument41 pagesConfidence Intervalszuber2111No ratings yet
- Statistics Chapter2Document102 pagesStatistics Chapter2Zhiye TangNo ratings yet
- 4 5 Chapter 4 ESTIMATION and 5 Hyp TestingDocument180 pages4 5 Chapter 4 ESTIMATION and 5 Hyp Testinghildamezmur9No ratings yet
- L7 EstimationDocument5 pagesL7 EstimationSaif UzZolNo ratings yet
- Chapter 5 - General EquilibrumDocument23 pagesChapter 5 - General EquilibrumbashatigabuNo ratings yet
- Dvielopmetal Economics Chap 1 & 2 StudentsDocument95 pagesDvielopmetal Economics Chap 1 & 2 StudentsEthio P100% (1)
- 4.1.1 HRs Approach To Development - 2021 - 2022 SDTDocument24 pages4.1.1 HRs Approach To Development - 2021 - 2022 SDTZenebe GezuNo ratings yet
- Joint and Conditional Probability DistributionsDocument52 pagesJoint and Conditional Probability DistributionsbashatigabuNo ratings yet
- Special Probability Distributions and DensitiesDocument43 pagesSpecial Probability Distributions and DensitiesNatai TamiruNo ratings yet
- 1 Legal ProstitDocument5 pages1 Legal ProstitbashatigabuNo ratings yet
- Chapter 5Document47 pagesChapter 5bashatigabuNo ratings yet
- ChapFour PPT TradeDocument32 pagesChapFour PPT Tradebashatigabu100% (1)
- 1 Basic Writing Note Edited GooodDocument32 pages1 Basic Writing Note Edited GooodbashatigabuNo ratings yet
- Course Syllabus-International Economics IDocument6 pagesCourse Syllabus-International Economics IbashatigabuNo ratings yet
- Assignment of Introduction To StatisticsDocument3 pagesAssignment of Introduction To StatisticsbashatigabuNo ratings yet
- College of College of Business and EconomicsDocument2 pagesCollege of College of Business and EconomicsbashatigabuNo ratings yet
- Chapter 5 - Macroeconomic Policy DebatesDocument37 pagesChapter 5 - Macroeconomic Policy DebatesbashatigabuNo ratings yet
- Chapter 5 - Macroeconomic Policy DebatesDocument37 pagesChapter 5 - Macroeconomic Policy DebatesbashatigabuNo ratings yet
- Chapter 5 - Macroeconomic Policy DebatesDocument37 pagesChapter 5 - Macroeconomic Policy DebatesbashatigabuNo ratings yet
- Chapter 5 - Global Financial InstitutionsDocument19 pagesChapter 5 - Global Financial InstitutionsbashatigabuNo ratings yet
- Standard Deviation Is A Widely Used Measurement of Variability or Diversity Used inDocument17 pagesStandard Deviation Is A Widely Used Measurement of Variability or Diversity Used inVietrah STaranoateNo ratings yet
- Discovery of Inert Gas StatsDocument9 pagesDiscovery of Inert Gas StatsDayanna GraztNo ratings yet
- Ridge Regression Techniques Improve Ordinary Least SquaresDocument12 pagesRidge Regression Techniques Improve Ordinary Least SquaresGHULAM MURTAZANo ratings yet
- Nama: Yane Suciana Herman NIM: 2105140012 Tugas: Uji Normalitas DataDocument1 pageNama: Yane Suciana Herman NIM: 2105140012 Tugas: Uji Normalitas DatarizkyNo ratings yet
- Logistic NotaDocument87 pagesLogistic NotaMathsCatch Cg RohainulNo ratings yet
- Vote Buying, Government Accountability, and Political Corruption: The Case of The PhilippinesDocument7 pagesVote Buying, Government Accountability, and Political Corruption: The Case of The PhilippinesAJHSSR JournalNo ratings yet
- Key Factors Promoting Customer Satisfaction in HR Analytics (HRM7640Document8 pagesKey Factors Promoting Customer Satisfaction in HR Analytics (HRM7640Osho Ademola JoelNo ratings yet
- Improving Your Data Transformations Applying The Box-Cox TransfDocument10 pagesImproving Your Data Transformations Applying The Box-Cox Transfznyaphotmail.comNo ratings yet
- Functional Forms of Regression Models ExplainedDocument10 pagesFunctional Forms of Regression Models ExplainedHadi Riyan PangestuNo ratings yet
- MTH302 MCQsDocument19 pagesMTH302 MCQsTaimoor SultanNo ratings yet
- Shaft Clearance FitsDocument5 pagesShaft Clearance FitssjnicholsonNo ratings yet
- Enthought Python Machine Learning SciKit Learn Cheat Sheets 1 3 v1.0Document3 pagesEnthought Python Machine Learning SciKit Learn Cheat Sheets 1 3 v1.0Hrishabh VashishtNo ratings yet
- This Study Resource Was: CH 10 TestDocument7 pagesThis Study Resource Was: CH 10 TestIlham SaputraNo ratings yet
- Data Mining Notes C3Document11 pagesData Mining Notes C3wuziqiNo ratings yet
- Exercise Probability Distribution QADocument3 pagesExercise Probability Distribution QAHafiz khalidNo ratings yet
- Factor Analysis SPSSDocument3 pagesFactor Analysis SPSSpaewoonNo ratings yet
- Statistical Analysis of Domestic Violence Against Married Women in Ivaniva District, South Gonder, EthiopiaDocument24 pagesStatistical Analysis of Domestic Violence Against Married Women in Ivaniva District, South Gonder, EthiopiamuralidharanNo ratings yet
- Measures of Dispersion or VariabilityDocument15 pagesMeasures of Dispersion or VariabilityCabudol Angel BaldivisoNo ratings yet
- What Is The Rationale Behind The Magic Number 30 in StatisticsDocument20 pagesWhat Is The Rationale Behind The Magic Number 30 in StatisticsEdy SutiarsoNo ratings yet
- Bstat Final GroupDocument3 pagesBstat Final GroupLuan VanNo ratings yet
- Statistics SymbolsDocument3 pagesStatistics SymbolsWilcoxAssoc100% (2)
- An R Companion to James Hamilton’s Times Series AnalysisDocument84 pagesAn R Companion to James Hamilton’s Times Series AnalysisAsriani HasanNo ratings yet
- Simple Guide To MinitabDocument28 pagesSimple Guide To MinitabDedi Suryadi100% (1)
- Data Processing & StatisticalDocument21 pagesData Processing & StatisticalJhonwyn Orgas0% (1)
- PTS2 Exam 2017 With SolutionsDocument10 pagesPTS2 Exam 2017 With SolutionsDanish ElahiNo ratings yet