You might also like
- Learn File, Folder & Text File FunctionsDocument8 pagesLearn File, Folder & Text File Functionsnick gomezNo ratings yet
- Heart Attack Risk Assessment ModelDocument13 pagesHeart Attack Risk Assessment ModelmbowejNo ratings yet
- 0.1 Installation of R PackagesDocument10 pages0.1 Installation of R PackagesRajulNo ratings yet
- Mean Devition and Co-EfficiantDocument18 pagesMean Devition and Co-EfficiantAjay SahooNo ratings yet
- IT Grade - WikipediaDocument2 pagesIT Grade - WikipediaVratislav Němec ml.No ratings yet
- Excel Tables, Formulas & Pivot Tables: What You LearnDocument10 pagesExcel Tables, Formulas & Pivot Tables: What You Learnnick gomezNo ratings yet
- Simple Linear RegressionDocument19 pagesSimple Linear RegressionRiya SinghNo ratings yet
- Working With Arrays: What You LearnDocument9 pagesWorking With Arrays: What You Learnnick gomezNo ratings yet
- Daftar Nilai Mata Kuliah Komputer: No Stambuk Nama Nilai HDR Tugas Quis Mid FinalDocument6 pagesDaftar Nilai Mata Kuliah Komputer: No Stambuk Nama Nilai HDR Tugas Quis Mid FinalDiah MhoNo ratings yet
- Stata 10 (Time Series and Forecasting) : Journal of Statistical Software January 2008Document19 pagesStata 10 (Time Series and Forecasting) : Journal of Statistical Software January 2008Alihasen Yacob DebisoNo ratings yet
- Agapi Mikayelyan Mechanics Lab Report 1Document7 pagesAgapi Mikayelyan Mechanics Lab Report 1Վահե ՍուքիասյանNo ratings yet
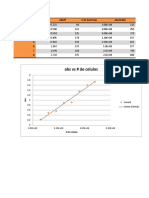
- Abs Vs # de CelulasDocument4 pagesAbs Vs # de CelulasXiadany MendozaNo ratings yet
- Generate random numbers between 1-10, find statisticsDocument4 pagesGenerate random numbers between 1-10, find statisticsNithin GopinadhNo ratings yet
- 01tabel R: Download NowDocument1 page01tabel R: Download NowTaeTaeBreadNo ratings yet
- Opration Management TAMDocument5 pagesOpration Management TAMHK 'sNo ratings yet
- Analyzing Continuous Variables: FrequenciesDocument36 pagesAnalyzing Continuous Variables: FrequenciesintansusmitaNo ratings yet
- Examples On Training ANN To Ease Power System Operation Using MATLABDocument18 pagesExamples On Training ANN To Ease Power System Operation Using MATLABSushma BiradarNo ratings yet
- Forecasting Div BDocument21 pagesForecasting Div BPRANAV BHARARANo ratings yet
- Centipoise (CPS) or Millipascal (Mpas) Poise (P) Centistokes (CKS) Stokes (S) Saybolt Universal (Ssu)Document4 pagesCentipoise (CPS) or Millipascal (Mpas) Poise (P) Centistokes (CKS) Stokes (S) Saybolt Universal (Ssu)Felipe Lepe MattaNo ratings yet
- Rey-1Document13 pagesRey-1Ahmad ArifNo ratings yet
- Module 8 Computing The Point Estimate of A Population MeanDocument33 pagesModule 8 Computing The Point Estimate of A Population MeanJohn Lloyd LucabanNo ratings yet
- Microsoft Excel TutorialDocument12 pagesMicrosoft Excel TutorialthomasNo ratings yet
- 5-6 Valores de K (FSD)Document1 page5-6 Valores de K (FSD)Ana Clara MarialvaNo ratings yet
- Notes On Programs Tramo and Seats: 11 March 2003Document95 pagesNotes On Programs Tramo and Seats: 11 March 2003Juan SantanaNo ratings yet
- Solution ExtraDocument9 pagesSolution ExtraAnushka KanaujiaNo ratings yet
- X-R Chart LabDocument7 pagesX-R Chart Labarslan shahidNo ratings yet
- Diagnóstico - Service ADVISOR™Document1 pageDiagnóstico - Service ADVISOR™Esau Frank Aliaga VilchezNo ratings yet
- Spearman's Rank: A Guide ToDocument4 pagesSpearman's Rank: A Guide TonugrohoNo ratings yet
- MTK 8DDocument140 pagesMTK 8DIdham MuqoddasNo ratings yet
- Lindab Airductsystems - Presiune Admisa - 2Document1 pageLindab Airductsystems - Presiune Admisa - 2Raluca OlaruNo ratings yet
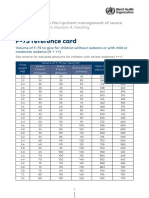
- WHO HEP NFS 21.8 EngDocument3 pagesWHO HEP NFS 21.8 EngCHRYSS FOXNo ratings yet
- Simulation: Intro To Management ScienceDocument29 pagesSimulation: Intro To Management ScienceWaleed AhmadNo ratings yet
- Lab Report 2 Group1Document7 pagesLab Report 2 Group1azamatNo ratings yet
- Monte Carlo Simulation ResultsDocument15 pagesMonte Carlo Simulation ResultsManarNo ratings yet
- Estimate demand for health services using forecasting techniquesDocument5 pagesEstimate demand for health services using forecasting techniquesPrajaktaNo ratings yet
- Lampiran LampiranDocument9 pagesLampiran LampiranJss eeNo ratings yet
- Credit Card Fraud DetectionDocument101 pagesCredit Card Fraud Detectionsripallavid1214No ratings yet
- DATA SCIENCE IDC 302 end sem projectDocument1 pageDATA SCIENCE IDC 302 end sem projectsoniakar3000No ratings yet
- Rajat61RM-Copy1Document1 pageRajat61RM-Copy1The JamesNo ratings yet
- 0.1.JustNifty TA 1 (By Ilango)Document13,477 pages0.1.JustNifty TA 1 (By Ilango)Badri NarayananNo ratings yet
- Siegel Et Al-2015-CA A Cancer Journal For CliniciansDocument27 pagesSiegel Et Al-2015-CA A Cancer Journal For CliniciansfennykusumaNo ratings yet
- 09.technical Documents - 4.5.6.7.8.9 ClauseDocument106 pages09.technical Documents - 4.5.6.7.8.9 ClauseKarina GorisNo ratings yet
- 10-10-SG-002 01 Insulation SpecificationDocument6 pages10-10-SG-002 01 Insulation Specificationguven dalgaNo ratings yet
- Screw Bolt and NutDocument7 pagesScrew Bolt and NutsutarnoNo ratings yet
- Report Math FADocument5 pagesReport Math FAkamosiik26No ratings yet
- English 2 - PublishDocument2 pagesEnglish 2 - PublishGilberto VelandiaNo ratings yet
- Student T Distribution TableDocument1 pageStudent T Distribution Tablevicky696969No ratings yet
- P ARETODocument4 pagesP ARETONicoleta SporeaNo ratings yet
- Six Sigma - Live Lecture 10Document59 pagesSix Sigma - Live Lecture 10Vishwa ChethanNo ratings yet
- Sic1012 Exp6Document8 pagesSic1012 Exp6SumayyahNo ratings yet
- SAT Subject Scoring For World HistoryDocument2 pagesSAT Subject Scoring For World HistoryLarsenTwilNo ratings yet
- FIN+613+Handout+1 1-1 PDFDocument15 pagesFIN+613+Handout+1 1-1 PDFWenting WanNo ratings yet
- Standard dimensions for manufacturing / delivery of profilesDocument1 pageStandard dimensions for manufacturing / delivery of profilesFilip PopescuNo ratings yet
- Dpipe: Calculation Sample and Recommended Sequence For Entering Input DataDocument14 pagesDpipe: Calculation Sample and Recommended Sequence For Entering Input DataAbhinav OjhaNo ratings yet
- 3 ForecastingDocument12 pages3 ForecastingNipun JainNo ratings yet
- ECON5541 Online Individual Assignment 1 AnalysisDocument2 pagesECON5541 Online Individual Assignment 1 Analysis- wurileNo ratings yet
- Sample Size Guideline For Correlation AnalysisDocument10 pagesSample Size Guideline For Correlation AnalysisNethaji MettNo ratings yet
- Torsion TestDocument7 pagesTorsion TestAmmar AlaufiNo ratings yet
- Ies Indoor Report Photometric Filename: Bs101Ecoled4Hthowt35120V-277V - S.Ies DESCRIPTION INFORMATION (From Photometric File)Document6 pagesIes Indoor Report Photometric Filename: Bs101Ecoled4Hthowt35120V-277V - S.Ies DESCRIPTION INFORMATION (From Photometric File)Ankit JainNo ratings yet
- Dianne Auld's Excel Tips: Featuring Compensation and Benefits Formulas Third EditionFrom EverandDianne Auld's Excel Tips: Featuring Compensation and Benefits Formulas Third EditionNo ratings yet
- Data Warehouse Power Point PresentationDocument18 pagesData Warehouse Power Point PresentationMohammed KemalNo ratings yet
- Chap 6Document77 pagesChap 6api-27259648No ratings yet
- Acknowledgement: Vaibhavi A T SDocument5 pagesAcknowledgement: Vaibhavi A T SVaibhavi AtsNo ratings yet
- Unit I Introduction 1.1 What Motivated Data Mining? Why Is It Important?Document18 pagesUnit I Introduction 1.1 What Motivated Data Mining? Why Is It Important?ANITHA AMMUNo ratings yet
- VERTICA SQL Reference ManualDocument970 pagesVERTICA SQL Reference ManuallietavecNo ratings yet
- GP KPI Index-Card Supplier-PerformanceDocument20 pagesGP KPI Index-Card Supplier-PerformanceSaldi AhmadNo ratings yet
- SMB File Migration To Emc Isilon: Guidance For Optimal Data Migration of SMB WorkflowsDocument46 pagesSMB File Migration To Emc Isilon: Guidance For Optimal Data Migration of SMB WorkflowsVishal GoyalNo ratings yet
- 20201st Sem Syllabus Auditing Assurance PrinciplesDocument10 pages20201st Sem Syllabus Auditing Assurance PrinciplesJamie Rose AragonesNo ratings yet
- ML Capstone Template CourseraDocument23 pagesML Capstone Template Courseraالريس حمادةNo ratings yet
- Chapter1 AnswersDocument5 pagesChapter1 AnswersTamala Stuckey88% (8)
- Hitachi Ultrastar C10K900 DatasheetDocument2 pagesHitachi Ultrastar C10K900 DatasheetAuria AlvesNo ratings yet
- Ca-Clipper RDDS: Advantage Database ServerDocument5 pagesCa-Clipper RDDS: Advantage Database ServerJose CorderoNo ratings yet
- Oracle Database 11g Privileges Roles and Application ContextsDocument44 pagesOracle Database 11g Privileges Roles and Application ContextsYelena BytenskayaNo ratings yet
- Database ConfigurationDocument5 pagesDatabase ConfigurationHarvey AguilarNo ratings yet
- The Ultimate C - C - SEN - 2005 - SAP Certified Application Associate - SAP Enable NowDocument2 pagesThe Ultimate C - C - SEN - 2005 - SAP Certified Application Associate - SAP Enable NowTeresaNo ratings yet
- How Can Trace and Debug Be Turned On For A Concurrent Request (Doc ID 759389.1)Document10 pagesHow Can Trace and Debug Be Turned On For A Concurrent Request (Doc ID 759389.1)cubNguyenNo ratings yet
- Flowchart of Pincer Search AlgorithmDocument1 pageFlowchart of Pincer Search AlgorithmNilotpal SahariahNo ratings yet
- BCA DBMS GNDU 2016 Semester III ExaminationDocument2 pagesBCA DBMS GNDU 2016 Semester III ExaminationBonny WaliaNo ratings yet
- 034513Document4,422 pages034513Dilip Kumar Alugu100% (1)
- Aman D. Kherariya PDFDocument77 pagesAman D. Kherariya PDFpragati kadamNo ratings yet
- Netbackup Cheat SheetDocument4 pagesNetbackup Cheat SheetAnvesh ReddyNo ratings yet
- Sfcfs AdminDocument157 pagesSfcfs Adminkatiyaramit3No ratings yet
- AIS - Chapter 3 Relational DatabaseDocument24 pagesAIS - Chapter 3 Relational DatabaseErmias GuragawNo ratings yet
- r4r Co inDocument179 pagesr4r Co insakunthalapcsNo ratings yet
- Serial Interface RS485 (RS422) Configuration InstructionsDocument20 pagesSerial Interface RS485 (RS422) Configuration Instructionsyana sopian hidayatNo ratings yet
- Unit-2 ER Model: For Example, Suppose We Design A School Database. in This Database, The Student Will Be AnDocument18 pagesUnit-2 ER Model: For Example, Suppose We Design A School Database. in This Database, The Student Will Be AnMilan SamantarayNo ratings yet
- RMM SyllabusDocument3 pagesRMM Syllabusgayathri saravananNo ratings yet
- Assignment 2 Qualitative AnalysisDocument3 pagesAssignment 2 Qualitative AnalysisTru TxNo ratings yet
- A Research Proposal of The IMPORATANT OF TRANINING AND DEVELOPMNET ON EMPLOYEES Yitagesu MarkosDocument20 pagesA Research Proposal of The IMPORATANT OF TRANINING AND DEVELOPMNET ON EMPLOYEES Yitagesu Markoshachalu lanjissaNo ratings yet
- 2.3 DatabasesDocument12 pages2.3 DatabasesadinebissoonNo ratings yet