You might also like
- Introduction To ROBOTICSDocument25 pagesIntroduction To ROBOTICSNyandaMadili MalashiNo ratings yet
- Exploring the Math and Art Connection: Teaching and Learning Between the LinesFrom EverandExploring the Math and Art Connection: Teaching and Learning Between the LinesNo ratings yet
- 8085 Instruction SetDocument27 pages8085 Instruction Setbostanci100% (1)
- Bizhub C284 - All Active Solutions: Legal NoticeDocument36 pagesBizhub C284 - All Active Solutions: Legal NoticeMotocas & MotocasNo ratings yet
- NX Post-Builder PDFDocument65 pagesNX Post-Builder PDFThe Anh100% (3)
- 1-MAST-C Steam Sterilizer Operation and Service ManualDocument54 pages1-MAST-C Steam Sterilizer Operation and Service Manualjojokaway100% (1)
- IMportant Paper On DrawingDocument16 pagesIMportant Paper On DrawingvimalsairamNo ratings yet
- q2 w1 ExpositoryDocument40 pagesq2 w1 ExpositoryCatherine OrdinarioNo ratings yet
- Statistical Modeling and Conceptualization of Visual PatternsDocument22 pagesStatistical Modeling and Conceptualization of Visual PatternsGautam JhaNo ratings yet
- Visualisation of Hierarchical Multivariate Data Categorisation and Case Study On Hate Speech - 2022Document21 pagesVisualisation of Hierarchical Multivariate Data Categorisation and Case Study On Hate Speech - 2022Serhiy YehressNo ratings yet
- Comprehension of Quantitative Information in Graphical DisplaysDocument51 pagesComprehension of Quantitative Information in Graphical DisplaysJosé ValenciaNo ratings yet
- Scene Graph Generation With Hierarchical ContextDocument7 pagesScene Graph Generation With Hierarchical ContextstutinahujaNo ratings yet
- Scale Spaces:: The Problem of RigourDocument22 pagesScale Spaces:: The Problem of Rigourmaus1945No ratings yet
- Pictorial Art and Vision: Further ReadingsDocument3 pagesPictorial Art and Vision: Further ReadingsMeenakshi MadanNo ratings yet
- General Framework For Object DetectionDocument9 pagesGeneral Framework For Object DetectionVinod KanwarNo ratings yet
- Visualizing Cognitive Systems: Getting Past Block Diagrams : University of Technology OHDocument6 pagesVisualizing Cognitive Systems: Getting Past Block Diagrams : University of Technology OHArnav DasaurNo ratings yet
- Forms of Visualisation As A Solving Approach in Teaching MathematicsDocument8 pagesForms of Visualisation As A Solving Approach in Teaching Mathematicsmariana.machadinho.24No ratings yet
- Diagram ProcessingDocument46 pagesDiagram Processingfayshox1325No ratings yet
- VmdiscussDocument4 pagesVmdiscussGautam JhaNo ratings yet
- Ijgi 10 00488Document23 pagesIjgi 10 00488stutinahujaNo ratings yet
- A Gentle Introduction To Graph Neural NetworksDocument14 pagesA Gentle Introduction To Graph Neural NetworksSaad El AbboubiNo ratings yet
- Distant Viewing: Analyzing Large Visual CorporaDocument14 pagesDistant Viewing: Analyzing Large Visual CorporacweqingNo ratings yet
- Clustering ArtDocument8 pagesClustering ArtIuliaNamaşcoNo ratings yet
- Pict Struct Ijcv PDFDocument42 pagesPict Struct Ijcv PDFManikandan VpNo ratings yet
- Teaching Spatial Statistical Techniques and Concepts: ICOTS-7, 2006: Castle (Refereed)Document4 pagesTeaching Spatial Statistical Techniques and Concepts: ICOTS-7, 2006: Castle (Refereed)sotorkNo ratings yet
- What Are Textons?: (Szhu, Cguo, Wangyiz) @cis - Ohio-State - EduDocument15 pagesWhat Are Textons?: (Szhu, Cguo, Wangyiz) @cis - Ohio-State - EduGautam JhaNo ratings yet
- 1.1 Graph TheoryDocument19 pages1.1 Graph Theoryswarup teliNo ratings yet
- Greenberg Pictorial SemanticsDocument49 pagesGreenberg Pictorial SemanticsrazlivintzNo ratings yet
- Mathematical Picture Language Program: Arthur M. Jaffe and Zhengwei LiuDocument6 pagesMathematical Picture Language Program: Arthur M. Jaffe and Zhengwei LiuSangat BaikNo ratings yet
- Face Recognition by Elastic Bunch Graph MatchingDocument23 pagesFace Recognition by Elastic Bunch Graph MatchingPranjal GoreNo ratings yet
- Taxonomy of Appearance RepresentationDocument10 pagesTaxonomy of Appearance RepresentationRishab MehtaNo ratings yet
- Aula 1.3 - EPPLER 2006 Compara Mapa Mental Conceitual Metafora VisualDocument10 pagesAula 1.3 - EPPLER 2006 Compara Mapa Mental Conceitual Metafora VisualcarlosadmgoNo ratings yet
- Graph Visualization and Navigation in Information Visualization: A SurveyDocument20 pagesGraph Visualization and Navigation in Information Visualization: A SurveyHarry HeNo ratings yet
- A Not-So-Characteristic Equation The Art of Linear AlgebraDocument15 pagesA Not-So-Characteristic Equation The Art of Linear AlgebraHIPOLITO ARTURO RIVEROS GUEVARANo ratings yet
- Chen Minds Eye A 2015 CVPR PaperDocument10 pagesChen Minds Eye A 2015 CVPR PaperPallavi BhartiNo ratings yet
- R E: K G E R - R C S: Otat Nowledge Raph Mbedding by ELA Tional Otation in Omplex PaceDocument18 pagesR E: K G E R - R C S: Otat Nowledge Raph Mbedding by ELA Tional Otation in Omplex PaceDr. Kaushal Kishor SharmaNo ratings yet
- Development and Application of A Metric On Semantic Nets: S1S1tM3, 17, I, 1707 LiDocument14 pagesDevelopment and Application of A Metric On Semantic Nets: S1S1tM3, 17, I, 1707 Liphyoset thawNo ratings yet
- A Comparison Between Concept Maps Mind Maps ConcepDocument10 pagesA Comparison Between Concept Maps Mind Maps ConcepNadia Aparecida BossaNo ratings yet
- Picturing Science: Design Patterns in Graphical AbstractsDocument16 pagesPicturing Science: Design Patterns in Graphical AbstractsJoanne BlancoNo ratings yet
- Image With A Message: Towards Detecting Non-Literal Image Usages by Visual LinkingDocument8 pagesImage With A Message: Towards Detecting Non-Literal Image Usages by Visual LinkingSanjay KNo ratings yet
- Enlish 8 Week 1 Q2Document6 pagesEnlish 8 Week 1 Q2Jinky MendozaNo ratings yet
- Qualitative Structural Analysis Using Diagrammatic ReasoningDocument7 pagesQualitative Structural Analysis Using Diagrammatic ReasoningUnknownNo ratings yet
- GionisDocument191 pagesGionisvutavivaNo ratings yet
- DC GCNDocument11 pagesDC GCN1692124482No ratings yet
- Nips 99 YwtDocument7 pagesNips 99 YwtmikeNo ratings yet
- Paper 13Document10 pagesPaper 13Andrea CalíNo ratings yet
- Psikologi TerjemahDocument3 pagesPsikologi TerjemahIka PrasetyaNo ratings yet
- Deep Visual-Semantic Alignments For Generating Image DescriptionsDocument17 pagesDeep Visual-Semantic Alignments For Generating Image DescriptionsJosephNo ratings yet
- Correlated Topic Models: David M. Blei John D. LaffertyDocument8 pagesCorrelated Topic Models: David M. Blei John D. Laffertyandrea ramirezNo ratings yet
- Design Problem Solving With Conceptual DiagramsDocument6 pagesDesign Problem Solving With Conceptual DiagramsshivanNo ratings yet
- Design Problem Solving With Conceptual DiagramsDocument7 pagesDesign Problem Solving With Conceptual Diagramsmeee itectNo ratings yet
- Diagres PapDocument30 pagesDiagres Papju1976No ratings yet
- Knowledge - Graph - Embedding - and - OpenKE (Report)Document5 pagesKnowledge - Graph - Embedding - and - OpenKE (Report)Toàn NguyễnNo ratings yet
- Cognitive Principles of Graphic Displays: Barbara TverskyDocument9 pagesCognitive Principles of Graphic Displays: Barbara TverskyShaymma Ramphalie-OuditNo ratings yet
- Saliency Detection by Multi-Context Deep LearningDocument10 pagesSaliency Detection by Multi-Context Deep Learningsiva shankaranNo ratings yet
- A General Framework For Object DetectionDocument8 pagesA General Framework For Object DetectionHira RasabNo ratings yet
- Breast Screening Chicken Sexing and TheDocument14 pagesBreast Screening Chicken Sexing and TheAll_n_CifuentesNo ratings yet
- Graph Theory: Graph of A Function Graph (Disambiguation)Document8 pagesGraph Theory: Graph of A Function Graph (Disambiguation)Navi_85No ratings yet
- Geometrical Pictures (Duval-1995)Document7 pagesGeometrical Pictures (Duval-1995)eduard515No ratings yet
- Pentland - 1984 - Fractal-Based Description of Natural ScenesDocument14 pagesPentland - 1984 - Fractal-Based Description of Natural ScenesDaniel OviedoNo ratings yet
- Incorporating Interactive 3-Dimensional Graphics in Astronomy Research PapersDocument18 pagesIncorporating Interactive 3-Dimensional Graphics in Astronomy Research PapersDainXBNo ratings yet
- Chapters 1 To 6 1Document120 pagesChapters 1 To 6 1Mary Antonitte ChicaNo ratings yet
- Comprehension of Illustrated Text: Pictures Help To Build Mental ModelsDocument23 pagesComprehension of Illustrated Text: Pictures Help To Build Mental ModelsLeo AleksanderNo ratings yet
- Contouring With UncertaintyDocument9 pagesContouring With UncertaintyGonn BandaNo ratings yet
- Poincaré Embeddings For Learning Hierarchical Representations - NIPS-2017-poincare-embeddings-for-learning-hierarchical-representations-PaperDocument10 pagesPoincaré Embeddings For Learning Hierarchical Representations - NIPS-2017-poincare-embeddings-for-learning-hierarchical-representations-Paperciro carvalloNo ratings yet
- Tronic Meeting Systems To Support GroupDocument22 pagesTronic Meeting Systems To Support GroupjojokawayNo ratings yet
- Functions and Limitations of TrustDocument26 pagesFunctions and Limitations of TrustjojokawayNo ratings yet
- The Role of Information Technology in THDocument35 pagesThe Role of Information Technology in THjojokawayNo ratings yet
- Electronic TonguesA ReviewDocument11 pagesElectronic TonguesA ReviewjojokawayNo ratings yet
- ContentsDocument12 pagesContentsjojokawayNo ratings yet
- Information Technology LawDocument3 pagesInformation Technology LawjojokawayNo ratings yet
- Patterns of Cooperation in International Water Law - Principles AnDocument26 pagesPatterns of Cooperation in International Water Law - Principles AnjojokawayNo ratings yet
- Therac25 LevesonDocument49 pagesTherac25 LevesonjojokawayNo ratings yet
- The Impact of Managed Care On Patients TDocument5 pagesThe Impact of Managed Care On Patients TjojokawayNo ratings yet
- Sirius: Static Program Repair With Dependence Graph-Based Systematic Edit PatternsDocument11 pagesSirius: Static Program Repair With Dependence Graph-Based Systematic Edit PatternsjojokawayNo ratings yet
- Excel Healthcare Autoclaves New Generation 17LB 22LB ManualDocument39 pagesExcel Healthcare Autoclaves New Generation 17LB 22LB ManualjojokawayNo ratings yet
- Medical Dev 1Document9 pagesMedical Dev 1jojokawayNo ratings yet
- Legal PrinciplesDocument33 pagesLegal PrinciplesjojokawayNo ratings yet
- Kansal - A. - 2002. - Solid - Waste - Management20161024 6489 L7o4l9 With Cover Page v2Document6 pagesKansal - A. - 2002. - Solid - Waste - Management20161024 6489 L7o4l9 With Cover Page v2jojokawayNo ratings yet
- Hopper 1993 Ann Rev EntDocument25 pagesHopper 1993 Ann Rev EntjojokawayNo ratings yet
- 01 13413 OvidkoDocument11 pages01 13413 OvidkojojokawayNo ratings yet
- Biocontrol PaperDocument25 pagesBiocontrol PaperjojokawayNo ratings yet
- 05 - Ghaffar20190509 5607 1ouzr5 With Cover Page v2Document17 pages05 - Ghaffar20190509 5607 1ouzr5 With Cover Page v2jojokawayNo ratings yet
- System Ipn MatDocument10 pagesSystem Ipn MatjojokawayNo ratings yet
- Lucasmechanicseconomicgrowth: Related PapersDocument41 pagesLucasmechanicseconomicgrowth: Related PapersjojokawayNo ratings yet
- Lab 16 Troubleshooting LabsDocument37 pagesLab 16 Troubleshooting LabsjojokawayNo ratings yet
- Chapter - 05 With Cover Page v2Document47 pagesChapter - 05 With Cover Page v2jojokawayNo ratings yet
- hl2170w - Network Connection Repair Instructions Rev LD 07262010Document5 pageshl2170w - Network Connection Repair Instructions Rev LD 07262010jojokawayNo ratings yet
- Page 22 To 28Document7 pagesPage 22 To 28jojokawayNo ratings yet
- Dusud E-Mail 22H12 NK Radio DRGEMDocument6 pagesDusud E-Mail 22H12 NK Radio DRGEMjojokawayNo ratings yet
- Économie 2Document47 pagesÉconomie 2jojokawayNo ratings yet
- NSW 227Document8 pagesNSW 227jojokawayNo ratings yet
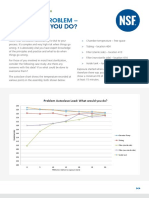
- Autoclave Problem-What Would You Do-Case Study-NSF PBDocument3 pagesAutoclave Problem-What Would You Do-Case Study-NSF PBjojokawayNo ratings yet
- Pe-E7886x FX 2018-11Document10 pagesPe-E7886x FX 2018-11jojokawayNo ratings yet
- GPS Receiver Architectures and Measurements: Proceedings of The IEEE February 1999Document18 pagesGPS Receiver Architectures and Measurements: Proceedings of The IEEE February 1999Abhay WadsingeNo ratings yet
- Verilog HDL - 18ec56 AssignmentDocument2 pagesVerilog HDL - 18ec56 Assignmentsureshfm1No ratings yet
- ACS 2000AD APPL SW Troubleshooting ManualDocument71 pagesACS 2000AD APPL SW Troubleshooting ManualFarhan Sattar0% (1)
- Discrete Mathematics: Advanced Counting TechniquesDocument36 pagesDiscrete Mathematics: Advanced Counting TechniquesanasurirajuNo ratings yet
- C - Operators C - OperatorsDocument6 pagesC - Operators C - OperatorsHECTOR FABIAN OROZCO GARCIANo ratings yet
- Product Information DIGSI 5 V09.60Document48 pagesProduct Information DIGSI 5 V09.60messias.messiNo ratings yet
- EC8652 Wireless CommunicationDocument2 pagesEC8652 Wireless CommunicationPunithaNo ratings yet
- Line6PodHD400 PDFDocument9 pagesLine6PodHD400 PDFlessonschoollNo ratings yet
- Elliptic Curve Cryptography Over Finite FieldsDocument6 pagesElliptic Curve Cryptography Over Finite FieldsSadik LubishtaniNo ratings yet
- HCIA-Security Lab Guide For Network Security Engineers V3.0Document125 pagesHCIA-Security Lab Guide For Network Security Engineers V3.0SIRIMA BREVA OGARANo ratings yet
- OPC UA Webinar - SlidesDocument21 pagesOPC UA Webinar - SlideskNo ratings yet
- UntitledDocument27 pagesUntitledDianarra VergaraNo ratings yet
- Spi Controlled H-Bridge: 1 FeaturesDocument23 pagesSpi Controlled H-Bridge: 1 Featuresazz zinouNo ratings yet
- System For Fake Currency Detection Using Image ProcessingDocument6 pagesSystem For Fake Currency Detection Using Image ProcessingIJRASETPublicationsNo ratings yet
- Can PowerPoint Speak Aloud & Read The Text in My SlideshowsDocument6 pagesCan PowerPoint Speak Aloud & Read The Text in My SlideshowsMohsin AliNo ratings yet
- CHICAGO - BROCHURE - ENG - Data EngineeringDocument9 pagesCHICAGO - BROCHURE - ENG - Data EngineeringRenato DuranNo ratings yet
- Danelec Ecdis Dm800 Software g2 v3 User ManualDocument333 pagesDanelec Ecdis Dm800 Software g2 v3 User ManualPaw PhoenixNo ratings yet
- Brute ForceDocument2 pagesBrute Forcenagham abuwardaNo ratings yet
- MIDTERM REVISION (S) -đã chuyển đổiDocument24 pagesMIDTERM REVISION (S) -đã chuyển đổiThu Thu0% (1)
- PLL Software Installation GuideDocument8 pagesPLL Software Installation GuideFava yavarNo ratings yet
- LFS-PM-T43 Operating ManualDocument29 pagesLFS-PM-T43 Operating ManualJuan Carlos CosmeNo ratings yet
- Minecraft - Wikipedia, The Free EncyclopediaDocument26 pagesMinecraft - Wikipedia, The Free Encyclopediarrr20130% (1)
- Thread-Level Parallelism and Synchronization IssuesDocument9 pagesThread-Level Parallelism and Synchronization IssuesSIYAB KhanNo ratings yet
- HP9335 LCDDocument27 pagesHP9335 LCDPaul Abi najemNo ratings yet
- OSINT Handbook 2020 (Parte 2)Document199 pagesOSINT Handbook 2020 (Parte 2)ArthurwstNo ratings yet
- Time Table - BT - 2 - Yr-2Document2 pagesTime Table - BT - 2 - Yr-2Just FunNo ratings yet