You might also like
- Vedic Mathematics Worlds Fastest Mental Math SystemDocument31 pagesVedic Mathematics Worlds Fastest Mental Math SystemAbhishek Sharma100% (2)
- Vedic Mathematics PresentationDocument31 pagesVedic Mathematics Presentationnd_lokesh100% (1)
- Mathematics For Elementary Teachers With Activities 5th Edition Ebook PDFDocument41 pagesMathematics For Elementary Teachers With Activities 5th Edition Ebook PDFjessica.stoops51997% (36)
- GRE - Quantitative Reasoning: QuickStudy Laminated Reference GuideFrom EverandGRE - Quantitative Reasoning: QuickStudy Laminated Reference GuideNo ratings yet
- ARCO SAT Subject Math Level 1 Practice Test PDFDocument29 pagesARCO SAT Subject Math Level 1 Practice Test PDFspartakid100% (2)
- Vectors in Two and Three DimentionsDocument48 pagesVectors in Two and Three Dimentionsuzlifatul jannahNo ratings yet
- Name: Gopala Krishna Chaitanya .Y PGID: 71710060 ASSIGNMENT 1 - SolvedDocument8 pagesName: Gopala Krishna Chaitanya .Y PGID: 71710060 ASSIGNMENT 1 - SolvedKali Prasad Ragavendra KuchibhotlaNo ratings yet
- Perm & Comb DPP (1-8) (13th) KOTADocument31 pagesPerm & Comb DPP (1-8) (13th) KOTARaju SinghNo ratings yet
- Formalist ApproachDocument26 pagesFormalist ApproachRamona ViernesNo ratings yet
- Blue Journal AnswersDocument43 pagesBlue Journal Answersapi-23591525154% (13)
- Normal DistributionDocument4 pagesNormal DistributionAlyssa Marie L. Palamiano100% (1)
- Chapter 1: Systems of Equations: Major New SkillsDocument9 pagesChapter 1: Systems of Equations: Major New SkillsWilson ZhangNo ratings yet
- The Normal CurveDocument29 pagesThe Normal CurveKent gonzaga100% (1)
- Significant FiguresDocument5 pagesSignificant Figuresdedo DZ100% (1)
- Significant Figures: Dr. Ma. Victoria Delis-NaboyaDocument45 pagesSignificant Figures: Dr. Ma. Victoria Delis-NaboyaRochen Shaira DargantesNo ratings yet
- Gvedicmathematics 090321072030 Phpapp02Document32 pagesGvedicmathematics 090321072030 Phpapp02Rashmi GujarNo ratings yet
- Introduction Geometry PosttestDocument3 pagesIntroduction Geometry PosttestIqbal A MirNo ratings yet
- TrigoDocument9 pagesTrigoJirah Jay CenalNo ratings yet
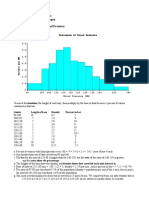
- Exercise 1:: Chapter 3: Describing Data: Numerical MeasuresDocument11 pagesExercise 1:: Chapter 3: Describing Data: Numerical MeasuresPW Nicholas100% (1)
- 5.lines and AnglesDocument41 pages5.lines and Anglesmary gamboa0% (2)
- Full Download Introductory Statistics 9th Edition Mann Solutions ManualDocument20 pagesFull Download Introductory Statistics 9th Edition Mann Solutions Manualsebastianezqjg100% (35)
- EST (With Answer Key)Document40 pagesEST (With Answer Key)chnxyeyed14No ratings yet
- Word ProblemDocument23 pagesWord ProblemMyla Nazar OcfemiaNo ratings yet
- Online Quantitative Analysis Exam HelpDocument6 pagesOnline Quantitative Analysis Exam HelpStatistics Exam HelpNo ratings yet
- HW I ReviewDocument10 pagesHW I ReviewNuraeni ShqNo ratings yet
- Quartile Deviationsand Standard DeviationDocument19 pagesQuartile Deviationsand Standard DeviationAnonymous z3ihT9DJ1vNo ratings yet
- Data Management 3Document13 pagesData Management 3Nestor Gutiza Jr.No ratings yet
- Frequency: Saravana Somasundaram Home Work 1 Math 4/5/7600Document8 pagesFrequency: Saravana Somasundaram Home Work 1 Math 4/5/7600Saravana SomasundaramNo ratings yet
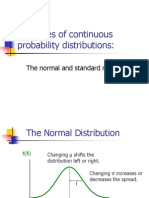
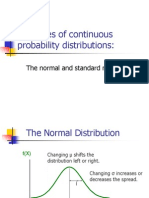
- Examples of Continuous Probability Distributions:: The Normal and Standard NormalDocument57 pagesExamples of Continuous Probability Distributions:: The Normal and Standard NormalkethavarapuramjiNo ratings yet
- Online Quantitative Analysis Assignment HelpDocument6 pagesOnline Quantitative Analysis Assignment HelpStatistics Homework SolverNo ratings yet
- Imteaz 20G20001 6th Stat AssignmentDocument5 pagesImteaz 20G20001 6th Stat AssignmentImteaz Alam Rabby 1220684030No ratings yet
- QTM Cycle 7 Session 4Document79 pagesQTM Cycle 7 Session 4OttilieNo ratings yet
- CH 5 PDocument4 pagesCH 5 PBrandon TulsiNo ratings yet
- Chapter 1 - Solutions of ExercisesDocument4 pagesChapter 1 - Solutions of ExercisesDanyValentinNo ratings yet
- Assignment-2: Name: Ahamad Ashique Mozumder ID: 1821474030 Section: 25Document13 pagesAssignment-2: Name: Ahamad Ashique Mozumder ID: 1821474030 Section: 25Salman ShahriarNo ratings yet
- APstat-Ch2 HW Kirkwood Solutions PDFDocument9 pagesAPstat-Ch2 HW Kirkwood Solutions PDFFrank ChenNo ratings yet
- Continuous Probability DistributionDocument14 pagesContinuous Probability DistributionMbuguz BeNel MuyaNo ratings yet
- Examples of Continuous Probability Distributions:: The Normal and Standard NormalDocument57 pagesExamples of Continuous Probability Distributions:: The Normal and Standard NormalPawan JajuNo ratings yet
- Tugas Kuliah Statistika SESI 4Document4 pagesTugas Kuliah Statistika SESI 4CEOAmsyaNo ratings yet
- IGNOU AssignmentDocument9 pagesIGNOU AssignmentAbhilasha Shukla0% (1)
- Mathematica HinduDocument32 pagesMathematica HinduV8TronNo ratings yet
- Examples of Continuous Probability Distributions:: The Normal and Standard NormalDocument57 pagesExamples of Continuous Probability Distributions:: The Normal and Standard NormalAkshay VetalNo ratings yet
- Normal DistributionDocument2 pagesNormal DistributionSaruNo ratings yet
- Chapter 10 SolutionsDocument22 pagesChapter 10 SolutionsGreg100% (1)
- Discussion1 SolutionDocument5 pagesDiscussion1 Solutionana_paciosNo ratings yet
- Biostat - Normal DistributionDocument4 pagesBiostat - Normal DistributionAnna Dominique JimenezNo ratings yet
- H4 ExpectedValue NormalDistribution SolutionDocument6 pagesH4 ExpectedValue NormalDistribution SolutionHennrocksNo ratings yet
- Module 3: Descriptive Statistics: Activities/AssessmentDocument9 pagesModule 3: Descriptive Statistics: Activities/AssessmentJane Arcon del RosarioNo ratings yet
- Stats QuizDocument6 pagesStats QuizMikomi SylvieNo ratings yet
- Econ 201 PS2 Suggested Solutions: April 21, 2015Document8 pagesEcon 201 PS2 Suggested Solutions: April 21, 2015qiucumberNo ratings yet
- Normal Distribution StanfordDocument43 pagesNormal Distribution Stanfordapi-204699162100% (1)
- MAT240Document54 pagesMAT240Hiền Nguyễn ThịNo ratings yet
- ECON 2P91: Assignment #1Document7 pagesECON 2P91: Assignment #1Joel Christian MascariñaNo ratings yet
- Continuous Probability Distribution PDFDocument47 pagesContinuous Probability Distribution PDFDipika PandaNo ratings yet
- Significant FiguresDocument10 pagesSignificant FiguresamirNo ratings yet
- Averages (Solutions)Document15 pagesAverages (Solutions)sahittiNo ratings yet
- RevisionDocument12 pagesRevisionlooooooooooolNo ratings yet
- ELEM STATandPROBDocument8 pagesELEM STATandPROBKyla Mae OrquijoNo ratings yet
- Normal Distribution of Statistics and Probability and Basic Calculus - Continuity of FunctionsDocument4 pagesNormal Distribution of Statistics and Probability and Basic Calculus - Continuity of FunctionsAlt GakeNo ratings yet
- Normal Distribution PPT With Assignment 1 Without AnswersDocument33 pagesNormal Distribution PPT With Assignment 1 Without AnswersJedidiah Daniel Lopez HerbillaNo ratings yet
- Scientific Notation and Significant FiguresDocument18 pagesScientific Notation and Significant FiguresLawrence AnDrew FrondaNo ratings yet
- Continuous Random Variables Part 4Document3 pagesContinuous Random Variables Part 4shan khanNo ratings yet
- Dwnload Full Introductory Statistics 9th Edition Mann Solutions Manual PDFDocument35 pagesDwnload Full Introductory Statistics 9th Edition Mann Solutions Manual PDFilorlamsals100% (13)
- Tugas Kuliah StatistikaDocument4 pagesTugas Kuliah StatistikaCEOAmsyaNo ratings yet
- Stat 231 A1Document11 pagesStat 231 A1nathanNo ratings yet
- Saint Joseph College Senior High School Department Tunga-Tunga, Maasin City, Southern Leyte 6600 PhilippinesDocument11 pagesSaint Joseph College Senior High School Department Tunga-Tunga, Maasin City, Southern Leyte 6600 PhilippinesJimkenneth RanesNo ratings yet
- Cheb YshevDocument13 pagesCheb Yshevkriss WongNo ratings yet
- SoftballDocument3 pagesSoftballRamona ViernesNo ratings yet
- Lesson 0 1: Differentiates Language Us Ed in Academic Texts From Various Dis CiplinesDocument57 pagesLesson 0 1: Differentiates Language Us Ed in Academic Texts From Various Dis CiplinesRamona ViernesNo ratings yet
- q1 Wk2academic Writing StudentsDocument51 pagesq1 Wk2academic Writing StudentsRamona ViernesNo ratings yet
- Abstraction Acitivity Module 5 9Document5 pagesAbstraction Acitivity Module 5 9Ramona ViernesNo ratings yet
- Health MDG 10Document40 pagesHealth MDG 10Ramona ViernesNo ratings yet
- FILMDocument17 pagesFILMRamona ViernesNo ratings yet
- Two Brothers Character AnalysisDocument1 pageTwo Brothers Character AnalysisRamona ViernesNo ratings yet
- ITMO 2015 IndividualDocument7 pagesITMO 2015 IndividualJonjon LeoncioNo ratings yet
- Sample QP 1 - 12th Maths - Pre Board Feb 2023 - 2024Document6 pagesSample QP 1 - 12th Maths - Pre Board Feb 2023 - 2024cuddalorespeakeasyNo ratings yet
- DE01 SolDocument117 pagesDE01 SolvamsiprasannakoduruNo ratings yet
- SFDFSGDFGDocument16 pagesSFDFSGDFGGelina Tibayan100% (2)
- Introduction To Triangles: Learning Enhancement TeamDocument4 pagesIntroduction To Triangles: Learning Enhancement Teamthierry abaniNo ratings yet
- Designing and Constructing TeacherDocument8 pagesDesigning and Constructing TeacherKristel NaborNo ratings yet
- Asm Unit1square &square Root, Cube &cube Root, Linear EquationsDocument3 pagesAsm Unit1square &square Root, Cube &cube Root, Linear EquationsanchitNo ratings yet
- 5.1.A 5.1.A Geometric Shapes PLTW PPTDocument5 pages5.1.A 5.1.A Geometric Shapes PLTW PPTLOGAN HENSLEENo ratings yet
- Mathematics: Quarter 2 - Module 7: Solving Problems On CirclesDocument28 pagesMathematics: Quarter 2 - Module 7: Solving Problems On CirclesDexiel Kay RomiscalNo ratings yet
- Lesson 4.3Document25 pagesLesson 4.3Randall MicallefNo ratings yet
- DLP 33Document6 pagesDLP 33Pablo JimeneaNo ratings yet
- Geometry Expressions Manual PDFDocument52 pagesGeometry Expressions Manual PDFYaseen GhulamNo ratings yet
- If This Measure Is Given: and You Want This Measure: Then Do ThisDocument4 pagesIf This Measure Is Given: and You Want This Measure: Then Do ThisNikunja PadhanNo ratings yet
- Fieldwork 2 - Hadi, Martina Bianca ODocument11 pagesFieldwork 2 - Hadi, Martina Bianca Omaria leonoraNo ratings yet
- The State of Louisiana Literacy TestDocument4 pagesThe State of Louisiana Literacy Testhomeroom9bNo ratings yet
- Section A: Duration 2 HrsDocument6 pagesSection A: Duration 2 HrsrheNo ratings yet
- Problem Set No. 1Document19 pagesProblem Set No. 1Yessel PogiNo ratings yet
- Justus Selfieometry ProjectDocument16 pagesJustus Selfieometry Projectapi-377726174No ratings yet
- Curriculum 2a Unit Plan Crop For WeeblyDocument11 pagesCurriculum 2a Unit Plan Crop For Weeblyapi-532162660No ratings yet