You might also like
- PLC: Programmable Logic Controller – Arktika.: EXPERIMENTAL PRODUCT BASED ON CPLD.From EverandPLC: Programmable Logic Controller – Arktika.: EXPERIMENTAL PRODUCT BASED ON CPLD.No ratings yet
- FPGA Implementations of Feed Forward Neural Network by Using Floating Point Hardware AcceleratorsDocument10 pagesFPGA Implementations of Feed Forward Neural Network by Using Floating Point Hardware AcceleratorsCarlos Torres CasasNo ratings yet
- FPGA Based Multi Core ProcessorDocument16 pagesFPGA Based Multi Core ProcessorvinayNo ratings yet
- Application-Specific Customization of Fpga: Parameterized Soft-Core ProcessorsDocument8 pagesApplication-Specific Customization of Fpga: Parameterized Soft-Core ProcessorsK.GurucharanNo ratings yet
- Design of Arithmetic Unit For High Speed Performance Using Vedic MathematicsDocument6 pagesDesign of Arithmetic Unit For High Speed Performance Using Vedic MathematicssaraNo ratings yet
- Single Chip Solution: Implementation of Soft Core Microcontroller Logics in FPGADocument4 pagesSingle Chip Solution: Implementation of Soft Core Microcontroller Logics in FPGAInternational Organization of Scientific Research (IOSR)No ratings yet
- System of Data Recording Based On Fpga and DSP: Jun Wang, Fuyang Zhang, Peng WuDocument4 pagesSystem of Data Recording Based On Fpga and DSP: Jun Wang, Fuyang Zhang, Peng WutienledhNo ratings yet
- Dynamic ReconfigurationDocument12 pagesDynamic ReconfigurationSambhav VermanNo ratings yet
- FPGA Paper PDFDocument18 pagesFPGA Paper PDFDhayanandhNo ratings yet
- Using Fpga-Soc Interface For Low Cost Iot Based Image ProcessingDocument6 pagesUsing Fpga-Soc Interface For Low Cost Iot Based Image ProcessingMouna elamariNo ratings yet
- Low-Cost and Optimized Two Layers Embedded Board BDocument14 pagesLow-Cost and Optimized Two Layers Embedded Board BJorge CotzomiNo ratings yet
- UWBR Matlab IseDocument20 pagesUWBR Matlab IsejebileeNo ratings yet
- A Reconfigurable System Featuring Dynamically Extensible Embedded Microprocessor, and CustomisableDocument4 pagesA Reconfigurable System Featuring Dynamically Extensible Embedded Microprocessor, and CustomisableMOHAMMAD AWAISNo ratings yet
- CCE 2018 Paper 53Document6 pagesCCE 2018 Paper 53JLuis LuNaNo ratings yet
- A Rapid Prototyping Environment For Microprocessor Based System-on-Chips and Its Application To The Development of A Network ProcessorDocument4 pagesA Rapid Prototyping Environment For Microprocessor Based System-on-Chips and Its Application To The Development of A Network ProcessorSamNo ratings yet
- Performance Modeling of Reconfigurable Distributed Systems Based On The OpenSPARC FPGA Board and The SIRC Communication FrameworkDocument7 pagesPerformance Modeling of Reconfigurable Distributed Systems Based On The OpenSPARC FPGA Board and The SIRC Communication FrameworkKevin ThomasNo ratings yet
- FPGA Genreal PaperDocument7 pagesFPGA Genreal PaperParth SomkuwarNo ratings yet
- Kulmala - Scalable MPEG-4 Encoder oDocument15 pagesKulmala - Scalable MPEG-4 Encoder obinazharNo ratings yet
- Tam MetinDocument4 pagesTam MetinerkandumanNo ratings yet
- FPGA: Field Programmable Gate ArrayDocument5 pagesFPGA: Field Programmable Gate ArrayGolnaz KorkianNo ratings yet
- A Low Power, Programmable Networking Platform and Development EnvironmentDocument19 pagesA Low Power, Programmable Networking Platform and Development EnvironmentNijil Kadavathu ValapilNo ratings yet
- FPGA Design Flow: Page 1 of 5Document6 pagesFPGA Design Flow: Page 1 of 5PRAVEEN034No ratings yet
- FPGA-Based PID Controller ImplementationDocument20 pagesFPGA-Based PID Controller ImplementationShahrzad GhasemiNo ratings yet
- Energy-Ef Cient Low-Latency Signed Multiplier For FPGA-based Hardware AcceleratorsDocument4 pagesEnergy-Ef Cient Low-Latency Signed Multiplier For FPGA-based Hardware AcceleratorsTRIAD TECHNO SERVICESNo ratings yet
- F Pga Implemented Reduced Ethernet MacDocument5 pagesF Pga Implemented Reduced Ethernet MacSaavin AbeygunawardenaNo ratings yet
- Modeling and Simulation of FPGA Based VaDocument13 pagesModeling and Simulation of FPGA Based VaMario OrdenanaNo ratings yet
- Project Report Flow Based Load Balancer On NETFPGADocument30 pagesProject Report Flow Based Load Balancer On NETFPGAKISHORHASYAGARNo ratings yet
- Fpga TutorialDocument10 pagesFpga Tutorialgsavithri_4017No ratings yet
- IMECS2010 pp1196-1199 PDFDocument4 pagesIMECS2010 pp1196-1199 PDFksajjNo ratings yet
- Field Programmable Gate ArrayDocument11 pagesField Programmable Gate ArrayRazeena ImtiazNo ratings yet
- FPGA and FPGAC (High Level Synthesise Tools)Document15 pagesFPGA and FPGAC (High Level Synthesise Tools)RUBEN DARIO TAMAYO BALLIVIANNo ratings yet
- Choi Asap14 KmeansDocument8 pagesChoi Asap14 KmeansjefferyleclercNo ratings yet
- Edge DetectionDocument9 pagesEdge Detectionabinabin2No ratings yet
- Case Study On: Nitte Meenakshi Institute of TechologyDocument8 pagesCase Study On: Nitte Meenakshi Institute of TechologyyogeshNo ratings yet
- Why FPGAs Are So Fast?Document13 pagesWhy FPGAs Are So Fast?bayman66No ratings yet
- Make-SoCs-flexible-with-embedded-FPGADocument6 pagesMake-SoCs-flexible-with-embedded-FPGAALiftsNo ratings yet
- Admin,+Journal+Manager,+42 AJPCR 19632Document7 pagesAdmin,+Journal+Manager,+42 AJPCR 19632shobana confyyNo ratings yet
- A Web (Based Multiuser Operating System For Recongurable ComputingDocument9 pagesA Web (Based Multiuser Operating System For Recongurable ComputingNi RoNo ratings yet
- 8 Bit ALU by XilinxDocument16 pages8 Bit ALU by XilinxDIPTANU MAJUMDERNo ratings yet
- Can 2016Document6 pagesCan 2016MinhHàNo ratings yet
- Secure Remote Protocol For Fpga ReconfigurationDocument5 pagesSecure Remote Protocol For Fpga ReconfigurationesatjournalsNo ratings yet
- I Jcs It 2014050173Document3 pagesI Jcs It 2014050173NikhithaNo ratings yet
- Palladium z1 Ds PDFDocument7 pagesPalladium z1 Ds PDFSlavica DjukanovicNo ratings yet
- Unit 1: System On A ChipDocument19 pagesUnit 1: System On A ChipSumit SinghNo ratings yet
- InterconnectsDocument6 pagesInterconnectsachuu1987No ratings yet
- Design of Embedded ProcessorsDocument80 pagesDesign of Embedded ProcessorsSayan Kumar KhanNo ratings yet
- A FPGA-based Soft Multiprocessor System For JPEG CompressionDocument8 pagesA FPGA-based Soft Multiprocessor System For JPEG CompressionsmkjadoonNo ratings yet
- FPGA Arquitectura BasicaDocument7 pagesFPGA Arquitectura BasicaJesus LeyvaNo ratings yet
- Comparison of Processing Performance and Architectural Efficiency Metrics For Fpgas and Gpus in 3D Ultrasound Computer TomographyDocument7 pagesComparison of Processing Performance and Architectural Efficiency Metrics For Fpgas and Gpus in 3D Ultrasound Computer TomographyincludecadastroNo ratings yet
- Image Processing Using VHDLDocument36 pagesImage Processing Using VHDLthesjus raiNo ratings yet
- Designing Digital Circuits Using Field Programmable Gate Arrays (Fpgas) (Part 1)Document7 pagesDesigning Digital Circuits Using Field Programmable Gate Arrays (Fpgas) (Part 1)조현민No ratings yet
- Rapid Prototyping of Image Analysis Algorithms On An Adaptive Fgpa ArchitectureDocument5 pagesRapid Prototyping of Image Analysis Algorithms On An Adaptive Fgpa ArchitectureUmar AnjumNo ratings yet
- Summary Master ThesisDocument3 pagesSummary Master ThesisAldoConteNo ratings yet
- Jimaging 05 00016Document22 pagesJimaging 05 00016vn7196No ratings yet
- Hale 2018Document4 pagesHale 2018aham krishnahaNo ratings yet
- Case Study On: Nitte Meenakshi Institute of TechnologyDocument8 pagesCase Study On: Nitte Meenakshi Institute of TechnologyyogeshNo ratings yet
- Definition:: Field-Programmable Gate ArrayDocument6 pagesDefinition:: Field-Programmable Gate ArrayyaduyadavendraNo ratings yet
- Lecture Notes-Computer Architecture-Module 1Document20 pagesLecture Notes-Computer Architecture-Module 1mokshagnanare26No ratings yet
- Why Con Gurable Computing? The Computational Density Advantage of Con Gurable ArchitecturesDocument17 pagesWhy Con Gurable Computing? The Computational Density Advantage of Con Gurable ArchitecturesHari KrishnaNo ratings yet
- HardwareDocument10 pagesHardwarerohitkumar2021No ratings yet
- Service Manual: Front Panel KitDocument26 pagesService Manual: Front Panel KitJorge CorralesNo ratings yet
- Dadex Efast Price List 1ST August 2020Document1 pageDadex Efast Price List 1ST August 2020Jugno ShahNo ratings yet
- Esquema Hidráulico AtualizadoDocument3 pagesEsquema Hidráulico AtualizadoMiguel RodriguezNo ratings yet
- Iridesse Cleaning Procedure Required DailyDocument5 pagesIridesse Cleaning Procedure Required DailyBrent RothlanderNo ratings yet
- NSR-3652 Series of Synchronizer User's Manual -V1.10 - 20180510【M2018004】 - BelarusDocument54 pagesNSR-3652 Series of Synchronizer User's Manual -V1.10 - 20180510【M2018004】 - BelarusАлександр КозловNo ratings yet
- System Analysis and Design Project Requirements CCCDocument20 pagesSystem Analysis and Design Project Requirements CCCMANALO, LHIENY MAE D.No ratings yet
- Vix112 Vmrun Command PDFDocument20 pagesVix112 Vmrun Command PDFtrix337No ratings yet
- LG 1.5 HP, Dual Inverter Compressor, 70 Energy Saving, Fast Cooling, 4 Way Swing, Auto Clean, Wi-Fi LG PhilippinesDocument1 pageLG 1.5 HP, Dual Inverter Compressor, 70 Energy Saving, Fast Cooling, 4 Way Swing, Auto Clean, Wi-Fi LG PhilippinesAltronix NapilisanNo ratings yet
- DevSecOps Lead Job DescriptionDocument2 pagesDevSecOps Lead Job DescriptionjencisoNo ratings yet
- Penetration Testing (White)Document1 pagePenetration Testing (White)alex mendozaNo ratings yet
- Anypoint Platform Development: Fundamentals (Mule 4) Setup RequirementsDocument3 pagesAnypoint Platform Development: Fundamentals (Mule 4) Setup RequirementsKakz KarthikNo ratings yet
- About Jordan's PolicyDocument20 pagesAbout Jordan's PolicySaeed Al-SaeedNo ratings yet
- Protocompiler WPDocument13 pagesProtocompiler WPajaysimha_vlsiNo ratings yet
- Lab 2Document10 pagesLab 2waleedNo ratings yet
- Pubg - Freefire (Swapon Vai)Document3 pagesPubg - Freefire (Swapon Vai)Shafiqul Islam Sajib100% (1)
- MowersDocument132 pagesMowersguillermosNo ratings yet
- Weld Restoration of Disk - Example of Elliott Repair TechnologyDocument49 pagesWeld Restoration of Disk - Example of Elliott Repair TechnologyMachineryengNo ratings yet
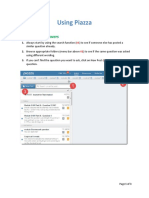
- Using Piazza: I. Looking For AnswersDocument3 pagesUsing Piazza: I. Looking For Answersnmra abidNo ratings yet
- ESP-report 22633 (31-33)Document23 pagesESP-report 22633 (31-33)1322 - Prasad KumbharNo ratings yet
- LKN To JBLP PDFDocument1 pageLKN To JBLP PDFMohd Kousar RazaNo ratings yet
- The Perfect Integrated Solution For All Your Reverse Engineering ProjectsDocument1 pageThe Perfect Integrated Solution For All Your Reverse Engineering ProjectsflibflurbNo ratings yet
- READ ME - InfoDocument2 pagesREAD ME - InfoSalih AktaşNo ratings yet
- List of Thesis Title Proposal For It StudentsDocument7 pagesList of Thesis Title Proposal For It StudentsHelpWritingCollegePapersSavannah100% (2)
- KX-TGDA20: Additional Digital Cordless HandsetDocument16 pagesKX-TGDA20: Additional Digital Cordless HandsetBrando GarciaNo ratings yet
- Skripsi IntiDocument153 pagesSkripsi IntiRIZKY FADILAHNo ratings yet
- BrandIdentityforIG SECUREDDocument1 pageBrandIdentityforIG SECUREDSimone MartaNo ratings yet
- Implementing Control Flow in An SSIS PackageDocument35 pagesImplementing Control Flow in An SSIS PackageRichie PooNo ratings yet
- Package ExampleDocument3 pagesPackage ExampleSunil SuryawanshiNo ratings yet
- Domestic BER Technical Bulletin July 2020Document33 pagesDomestic BER Technical Bulletin July 2020Denis DillaneNo ratings yet
- SMF&W 851-01-07 Manual Arc Welding 220319Document9 pagesSMF&W 851-01-07 Manual Arc Welding 220319Shahid RazaNo ratings yet
- CompTIA Security+ All-in-One Exam Guide, Sixth Edition (Exam SY0-601)From EverandCompTIA Security+ All-in-One Exam Guide, Sixth Edition (Exam SY0-601)Rating: 5 out of 5 stars5/5 (1)
- Computer Science: A Concise IntroductionFrom EverandComputer Science: A Concise IntroductionRating: 4.5 out of 5 stars4.5/5 (14)
- Chip War: The Quest to Dominate the World's Most Critical TechnologyFrom EverandChip War: The Quest to Dominate the World's Most Critical TechnologyRating: 4.5 out of 5 stars4.5/5 (227)
- Chip War: The Fight for the World's Most Critical TechnologyFrom EverandChip War: The Fight for the World's Most Critical TechnologyRating: 4.5 out of 5 stars4.5/5 (82)
- CompTIA A+ Certification All-in-One Exam Guide, Eleventh Edition (Exams 220-1101 & 220-1102)From EverandCompTIA A+ Certification All-in-One Exam Guide, Eleventh Edition (Exams 220-1101 & 220-1102)Rating: 5 out of 5 stars5/5 (2)
- Hacking With Linux 2020:A Complete Beginners Guide to the World of Hacking Using Linux - Explore the Methods and Tools of Ethical Hacking with LinuxFrom EverandHacking With Linux 2020:A Complete Beginners Guide to the World of Hacking Using Linux - Explore the Methods and Tools of Ethical Hacking with LinuxNo ratings yet
- iPhone X Hacks, Tips and Tricks: Discover 101 Awesome Tips and Tricks for iPhone XS, XS Max and iPhone XFrom EverandiPhone X Hacks, Tips and Tricks: Discover 101 Awesome Tips and Tricks for iPhone XS, XS Max and iPhone XRating: 3 out of 5 stars3/5 (2)
- How to Jailbreak Roku: Unlock Roku, Roku Stick, Roku Ultra, Roku Express, Roku TV with Kodi Step by Step GuideFrom EverandHow to Jailbreak Roku: Unlock Roku, Roku Stick, Roku Ultra, Roku Express, Roku TV with Kodi Step by Step GuideRating: 1 out of 5 stars1/5 (1)
- Amazon Web Services (AWS) Interview Questions and AnswersFrom EverandAmazon Web Services (AWS) Interview Questions and AnswersRating: 4.5 out of 5 stars4.5/5 (3)
- Amazon Echo Manual Guide : Top 30 Hacks And Secrets To Master Amazon Echo & Alexa For Beginners: The Blokehead Success SeriesFrom EverandAmazon Echo Manual Guide : Top 30 Hacks And Secrets To Master Amazon Echo & Alexa For Beginners: The Blokehead Success SeriesNo ratings yet
- CompTIA A+ Complete Review Guide: Exam Core 1 220-1001 and Exam Core 2 220-1002From EverandCompTIA A+ Complete Review Guide: Exam Core 1 220-1001 and Exam Core 2 220-1002Rating: 5 out of 5 stars5/5 (1)
- Patterns in the Machine: A Software Engineering Guide to Embedded DevelopmentFrom EverandPatterns in the Machine: A Software Engineering Guide to Embedded DevelopmentRating: 5 out of 5 stars5/5 (1)
- Programming with STM32: Getting Started with the Nucleo Board and C/C++From EverandProgramming with STM32: Getting Started with the Nucleo Board and C/C++Rating: 3.5 out of 5 stars3.5/5 (3)
- CompTIA A+ Complete Review Guide: Core 1 Exam 220-1101 and Core 2 Exam 220-1102From EverandCompTIA A+ Complete Review Guide: Core 1 Exam 220-1101 and Core 2 Exam 220-1102Rating: 5 out of 5 stars5/5 (2)
- Exploring Apple Mac - Sonoma Edition: The Illustrated, Practical Guide to Using MacOSFrom EverandExploring Apple Mac - Sonoma Edition: The Illustrated, Practical Guide to Using MacOSNo ratings yet
- Cancer and EMF Radiation: How to Protect Yourself from the Silent Carcinogen of ElectropollutionFrom EverandCancer and EMF Radiation: How to Protect Yourself from the Silent Carcinogen of ElectropollutionRating: 5 out of 5 stars5/5 (2)
- How To Market Mobile Apps: Your Step By Step Guide To Marketing Mobile AppsFrom EverandHow To Market Mobile Apps: Your Step By Step Guide To Marketing Mobile AppsNo ratings yet
- Windows 10 Mastery: The Complete User Guide to Learn Windows 10 from Beginner to ExpertFrom EverandWindows 10 Mastery: The Complete User Guide to Learn Windows 10 from Beginner to ExpertRating: 3.5 out of 5 stars3.5/5 (6)
- Raspberry Pi | 101: The Beginner’s Guide with Basics on Hardware, Software, Programming & ProjecFrom EverandRaspberry Pi | 101: The Beginner’s Guide with Basics on Hardware, Software, Programming & ProjecNo ratings yet
- Embedded Systems Design with Platform FPGAs: Principles and PracticesFrom EverandEmbedded Systems Design with Platform FPGAs: Principles and PracticesRating: 5 out of 5 stars5/5 (1)
- CompTIA A+ Complete Practice Tests: Core 1 Exam 220-1101 and Core 2 Exam 220-1102From EverandCompTIA A+ Complete Practice Tests: Core 1 Exam 220-1101 and Core 2 Exam 220-1102No ratings yet