You might also like
- Crystal+Essentials a+Beginners+Guide+to+Crystals FINALDocument7 pagesCrystal+Essentials a+Beginners+Guide+to+Crystals FINALGretchenNo ratings yet
- Csec It Mock ExamDocument10 pagesCsec It Mock Examvidur_talreja100% (1)
- Virgil Donati Feature Drumscene Magazine 2010Document10 pagesVirgil Donati Feature Drumscene Magazine 2010Clint Hopkins100% (1)
- Research Youth EmpowermentDocument18 pagesResearch Youth EmpowermentShiba Tatsuya0% (2)
- The HAZOP Leader's Handbook: How to Plan and Conduct Successful HAZOP StudiesFrom EverandThe HAZOP Leader's Handbook: How to Plan and Conduct Successful HAZOP StudiesNo ratings yet
- Informed Consent FormDocument3 pagesInformed Consent FormFrancis John PimentelNo ratings yet
- Tuning Solution V16.0.3.0Document16 pagesTuning Solution V16.0.3.0Amine HerbacheNo ratings yet
- Midterms 88%Document18 pagesMidterms 88%jrence80% (5)
- Analysis of Gilad Hekselman's Feauture On Smile Like That by Esperanza SpaldingDocument4 pagesAnalysis of Gilad Hekselman's Feauture On Smile Like That by Esperanza SpaldingJordan Kerr100% (1)
- Seam 325 Prelim Exam ReviewerDocument6 pagesSeam 325 Prelim Exam ReviewerKyle Steven CaymeNo ratings yet
- Sentiment Analysis in Social NetworksFrom EverandSentiment Analysis in Social NetworksRating: 5 out of 5 stars5/5 (2)
- Voice Recognition System: Speech-To-Text: Journal of Applied and Fundamental Sciences November 2015Document6 pagesVoice Recognition System: Speech-To-Text: Journal of Applied and Fundamental Sciences November 2015Subramani VNo ratings yet
- Voice Recognition System: Speech-To-Text: Journal of Applied and Fundamental Sciences November 2015Document6 pagesVoice Recognition System: Speech-To-Text: Journal of Applied and Fundamental Sciences November 2015Subramani VNo ratings yet
- The Use of Podcast in Improving Students Speaking SkillDocument16 pagesThe Use of Podcast in Improving Students Speaking SkillRitika0% (1)
- Speech To TextDocument6 pagesSpeech To TextTint Swe OoNo ratings yet
- Aaa - Informed Consent For ResearchDocument5 pagesAaa - Informed Consent For ResearchMarvin GonowonNo ratings yet
- Divide-and-Conquer Based Ensemble To Spot EmotionsDocument9 pagesDivide-and-Conquer Based Ensemble To Spot EmotionsVAIJAYANTHI SNo ratings yet
- Research Report ON: Habit of Social Networking Among Youth in VaranasiDocument72 pagesResearch Report ON: Habit of Social Networking Among Youth in VaranasiBheeshm SinghNo ratings yet
- BSIB 616 Research Methods - Final Project ADocument15 pagesBSIB 616 Research Methods - Final Project AhamzaNo ratings yet
- Self-Directed Learning A Tool For Lifelong LearningDocument15 pagesSelf-Directed Learning A Tool For Lifelong LearningZilbran BerontaxNo ratings yet
- 150114863016cre Textnayeemshowkatnonprobabilityandprobabilitysampling PDFDocument10 pages150114863016cre Textnayeemshowkatnonprobabilityandprobabilitysampling PDFFajriNo ratings yet
- A Survey On Language ModelsDocument32 pagesA Survey On Language ModelsNi Luh MeriantiniNo ratings yet
- Celebrity Endorsement and Brand BuildingDocument89 pagesCelebrity Endorsement and Brand BuildingSheron PatelNo ratings yet
- Difficulties Translating Research On Forensic Interview Practices To Practitioners: Finding Water, Leading Horses, But Can We Get Them To Drink?Document9 pagesDifficulties Translating Research On Forensic Interview Practices To Practitioners: Finding Water, Leading Horses, But Can We Get Them To Drink?Andrea Catalina Lobo RomeroNo ratings yet
- RMB - Research Proposal A6Document10 pagesRMB - Research Proposal A6Harshit ShubhankarNo ratings yet
- NTTCBULLETINMarch 2002Document8 pagesNTTCBULLETINMarch 2002bitiashvilinatiaNo ratings yet
- Effective Methods in Learning Arabic Language As ADocument8 pagesEffective Methods in Learning Arabic Language As AAqilah QistinaNo ratings yet
- CJR EnglishDocument3 pagesCJR EnglishPrima Lestari Situmorang100% (2)
- Algihab2019 Chapter ArabicSpeechRecognitionWithDeeDocument18 pagesAlgihab2019 Chapter ArabicSpeechRecognitionWithDeeSarahNo ratings yet
- Development of A Measure Internet Behaviors ScaleDocument9 pagesDevelopment of A Measure Internet Behaviors ScaleAlexa SzatmáriNo ratings yet
- 922 Final Paper v4Document11 pages922 Final Paper v4mohamed samyNo ratings yet
- Reflection On LEarning StylesDocument4 pagesReflection On LEarning StylesEn. Mohd Zulfadli Bin Mat HusinNo ratings yet
- Exploring Learning Through Cognitive Constructivism The Case For Online LessonsDocument16 pagesExploring Learning Through Cognitive Constructivism The Case For Online LessonsresocoleaNo ratings yet
- Sentence-Level Classification Using Parallel Fuzzy Deep Learning ClassifierDocument44 pagesSentence-Level Classification Using Parallel Fuzzy Deep Learning ClassifierOwais AkramNo ratings yet
- A Study On Brand Awareness With Special Reference To Sna Oushadhasala Pvt. Ltd. ThrissurDocument55 pagesA Study On Brand Awareness With Special Reference To Sna Oushadhasala Pvt. Ltd. ThrissurT M Jishnu DasNo ratings yet
- Jan2 2019 PDFDocument10 pagesJan2 2019 PDFswastika bhagowatiNo ratings yet
- The Effectiveness of Using An Online Presentation Platform in The Teaching and Learning of HistoryDocument23 pagesThe Effectiveness of Using An Online Presentation Platform in The Teaching and Learning of HistoryAtif Hameed MaharNo ratings yet
- Journal of Critical Reviews E-COUNSELLING PROCESS AND SKILS: A Literature ReviewDocument16 pagesJournal of Critical Reviews E-COUNSELLING PROCESS AND SKILS: A Literature Reviewfitri wahyuniNo ratings yet
- Tagbilaran CityDocument274 pagesTagbilaran CityJohn Joseph MagdalenaNo ratings yet
- Bangla Speech Emotion Detectionusing Machine Learning Ensemble MethodsDocument8 pagesBangla Speech Emotion Detectionusing Machine Learning Ensemble MethodsSanjidanahid ShornaNo ratings yet
- Framework Design&EvaluationDocument168 pagesFramework Design&EvaluationmohammedNo ratings yet
- Development and Validation of A Probe Word List To Assess Speech Motor Skills in ChildrenDocument28 pagesDevelopment and Validation of A Probe Word List To Assess Speech Motor Skills in ChildrenAtalita AzevedoNo ratings yet
- Sampling Techniques Probabilityfor Quantitative Social Science Researchers AConceptual Guidelineswith ExamplesDocument11 pagesSampling Techniques Probabilityfor Quantitative Social Science Researchers AConceptual Guidelineswith ExamplesWahyonoNo ratings yet
- Discovering Student Dropout Prediction Through Deep LearningDocument5 pagesDiscovering Student Dropout Prediction Through Deep LearningEditor IJTSRDNo ratings yet
- Quality Form: Dr. Cesar A. Villariba Research and Knowledge Management InstituteDocument6 pagesQuality Form: Dr. Cesar A. Villariba Research and Knowledge Management InstitutesahnojNo ratings yet
- The Use of Ai Artificial Intelligence in English Learning Among University StudentDocument11 pagesThe Use of Ai Artificial Intelligence in English Learning Among University StudentCharlie WongNo ratings yet
- Design and Implementation of Student and Alumni Web Portal: Science Journal of University of Zakho September 2017Document7 pagesDesign and Implementation of Student and Alumni Web Portal: Science Journal of University of Zakho September 2017Sravani BaswarajNo ratings yet
- Validity Reliability General Iz AbilityDocument10 pagesValidity Reliability General Iz AbilityDilip Kumar MahataNo ratings yet
- Exploring Learning AnalyticsDocument8 pagesExploring Learning AnalyticsbhatippNo ratings yet
- Islife v5n4p839 enDocument11 pagesIslife v5n4p839 enWaqar HassanNo ratings yet
- References Paper For Sentiment AnalysisDocument21 pagesReferences Paper For Sentiment AnalysisPipiana Anggraini juniNo ratings yet
- Chapter 1 - STRANDbyDocument7 pagesChapter 1 - STRANDbyAce RamosNo ratings yet
- Error Analysis in EFL Writing Classroom: ArticleDocument18 pagesError Analysis in EFL Writing Classroom: ArticleElla Mansel (Carmen M.)No ratings yet
- Important Elements For A Framework in Designing A Mobile LearningDocument5 pagesImportant Elements For A Framework in Designing A Mobile LearningIrfan HimmaturrafiNo ratings yet
- Research ProposalDocument6 pagesResearch ProposalSunlight SharmaNo ratings yet
- Jintelligence 10 000603Document12 pagesJintelligence 10 000603psychometrie.copeNo ratings yet
- The Effect of The Non Cognitive Trait Self Efficacy As A Predictor of Students' Academic Productivity in Anglo Saxon Universities in CameroonDocument18 pagesThe Effect of The Non Cognitive Trait Self Efficacy As A Predictor of Students' Academic Productivity in Anglo Saxon Universities in CameroonEditor IJTSRDNo ratings yet
- 9-Gender and Age Estimation 11 8 2020LastVersionDocument12 pages9-Gender and Age Estimation 11 8 2020LastVersionAnil Kumar BNo ratings yet
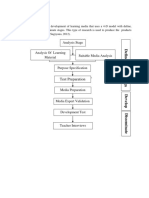
- Analysis Stage: Test PreparationDocument3 pagesAnalysis Stage: Test PreparationandaraNo ratings yet
- Students' Self-Confidence and Its Impacts On Their Learning ProcessDocument16 pagesStudents' Self-Confidence and Its Impacts On Their Learning ProcessBaji MarkNo ratings yet
- Matthes, Jorg - Framing PoliticsDocument15 pagesMatthes, Jorg - Framing PoliticsJoaquin PomboNo ratings yet
- Scopus 3 Full Artificial IntelligenceDocument9 pagesScopus 3 Full Artificial IntelligenceOMAR EL HAMDAOUINo ratings yet
- Plagiarism ComputerDocument14 pagesPlagiarism ComputerSyful IslamNo ratings yet
- The Effect of English Captioned Video On Students' Listening ComprehensionDocument8 pagesThe Effect of English Captioned Video On Students' Listening ComprehensionFADILLAH AMRI FIRDAUSNo ratings yet
- PDF Research in Public Relations IIDocument147 pagesPDF Research in Public Relations IIiypekoraNo ratings yet
- Evaluation of Teaching EffectivenessDocument10 pagesEvaluation of Teaching EffectivenessakintunjiNo ratings yet
- Lightly Supervised and Data-Driven Approaches ToDocument144 pagesLightly Supervised and Data-Driven Approaches ToSusanta SarangiNo ratings yet
- Temporal Patterns (Traps) in Asr of Noisy SpeechDocument4 pagesTemporal Patterns (Traps) in Asr of Noisy SpeechSusanta SarangiNo ratings yet
- Data-Driven Neural Network Based Feature - Phd-ThesisDocument155 pagesData-Driven Neural Network Based Feature - Phd-ThesisSusanta SarangiNo ratings yet
- 2003 Data Driven SRDocument4 pages2003 Data Driven SRSusanta SarangiNo ratings yet
- 2001 Data Driven ApproachDocument6 pages2001 Data Driven ApproachSusanta SarangiNo ratings yet
- 9 IoT Based Automatic Attendance SystemDocument4 pages9 IoT Based Automatic Attendance SystemSusanta SarangiNo ratings yet
- Civil Engineering Societal & Global ImpactDocument248 pagesCivil Engineering Societal & Global ImpactSusanta SarangiNo ratings yet
- Vowel IdentificationDocument15 pagesVowel IdentificationSusanta SarangiNo ratings yet
- Kafka and NiFIDocument8 pagesKafka and NiFIabhimanyu thakurNo ratings yet
- Seuring+and+Muller 2008Document12 pagesSeuring+and+Muller 2008Stephanie Cutts CheneyNo ratings yet
- Vis DK 25 Programming GuideDocument210 pagesVis DK 25 Programming GuideshrihnNo ratings yet
- Rationale of Employee Turnover: An Analysis of Banking Sector in NepalDocument8 pagesRationale of Employee Turnover: An Analysis of Banking Sector in Nepaltempmail5598No ratings yet
- UMTS Material (LT)Document215 pagesUMTS Material (LT)Matthew JejeloyeNo ratings yet
- Cambridge International Examinations Cambridge International Advanced LevelDocument8 pagesCambridge International Examinations Cambridge International Advanced LevelIlesh DinyaNo ratings yet
- As Me Certificate Holder ReportDocument5 pagesAs Me Certificate Holder ReportpandiangvNo ratings yet
- Effect of Temperature On SolubilityDocument8 pagesEffect of Temperature On SolubilityMuzahid KhatryNo ratings yet
- What's in Your BackpackDocument31 pagesWhat's in Your Backpackjohn ezekiel de asisNo ratings yet
- AGA - 168 PQsDocument69 pagesAGA - 168 PQscbourguigNo ratings yet
- Abe Tos 2023Document28 pagesAbe Tos 2023DelenayNo ratings yet
- Data Structures Lab ManualDocument159 pagesData Structures Lab Manualabhiraj1234No ratings yet
- NWPC Annual Report 2014Document56 pagesNWPC Annual Report 2014lupethe3No ratings yet
- SPM Practice June 29Document7 pagesSPM Practice June 29Isabel GohNo ratings yet
- List of Vocabulary Related To MusicDocument2 pagesList of Vocabulary Related To MusicTan HuynhNo ratings yet
- GRP 1Document2 pagesGRP 1Yuva RaniNo ratings yet
- Mitsubishi Electric MSZ-FH VE Remote Controller Eng PDFDocument1 pageMitsubishi Electric MSZ-FH VE Remote Controller Eng PDFShadi MattarNo ratings yet
- Unauthenticated Download Date - 1/31/17 4:04 AMDocument5 pagesUnauthenticated Download Date - 1/31/17 4:04 AMFahmi RaziNo ratings yet
- Quiet Healing CentreDocument12 pagesQuiet Healing CentredoliamahakNo ratings yet
- Set - 2 GR 11 II B. Tech II Semester Supplementary Examinations, Nov, 2013 Design and Analysis of Algorithms)Document1 pageSet - 2 GR 11 II B. Tech II Semester Supplementary Examinations, Nov, 2013 Design and Analysis of Algorithms)Anurag PatnaikuniNo ratings yet
- 2017 - 2022 NEC Strategic PlanDocument44 pages2017 - 2022 NEC Strategic PlanTharindu SamarakoonNo ratings yet
- TVL IACSS9 12ICCS Ia E28 MNHS SHS CAMALIGDocument4 pagesTVL IACSS9 12ICCS Ia E28 MNHS SHS CAMALIGKattie Alison Lumio MacatuggalNo ratings yet