You might also like
- Probability and Stochastic Process 21Document12 pagesProbability and Stochastic Process 21tarungajjuwaliaNo ratings yet
- Families of Random Variables: Homework 7Document4 pagesFamilies of Random Variables: Homework 7Zihan ZhuNo ratings yet
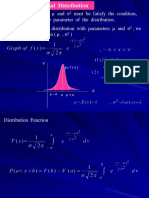
- Normal Distribution: y F (X) YDocument50 pagesNormal Distribution: y F (X) YRichard mwanaNo ratings yet
- Linear Transformations If Y Ax + B, Then y A X+B and SDocument2 pagesLinear Transformations If Y Ax + B, Then y A X+B and SmichaelNo ratings yet
- Probability and Statistics Hints/Solutions To Assignment No. 2Document2 pagesProbability and Statistics Hints/Solutions To Assignment No. 2Praveen BvsNo ratings yet
- Assignment On Sta 614Document21 pagesAssignment On Sta 614Obulezi OJNo ratings yet
- 08 BInomial Distribution15914387211591600949Document4 pages08 BInomial Distribution15914387211591600949Aneel UpadhyayNo ratings yet
- Department of Mathematics Indian Institute of Technology GuwahatiDocument3 pagesDepartment of Mathematics Indian Institute of Technology GuwahatilekhanasriNo ratings yet
- MAST20005 Statistics Assignment 3Document8 pagesMAST20005 Statistics Assignment 3Anonymous na314kKjOANo ratings yet
- Sydu Math1015 (2013) First Semester 1: LocationDocument1 pageSydu Math1015 (2013) First Semester 1: LocationmaplecookieNo ratings yet
- TESTtwo 477 F18 SOLDocument4 pagesTESTtwo 477 F18 SOLMike AudricNo ratings yet
- StochasticModels 2011 Part 2 v1Document22 pagesStochasticModels 2011 Part 2 v1danNo ratings yet
- Linear Transformations If Y Ax + B, Then y A X+B and SDocument3 pagesLinear Transformations If Y Ax + B, Then y A X+B and SmichaelNo ratings yet
- Statistics 1 Revision SheetDocument9 pagesStatistics 1 Revision SheetZira GreyNo ratings yet
- Negative BinomialDocument4 pagesNegative Binomialqwertypushkar123No ratings yet
- W7PSDocument12 pagesW7PSpolar necksonNo ratings yet
- TMA4180 Optimisation I Spring 2018: Solutions To Exercise Set 7Document4 pagesTMA4180 Optimisation I Spring 2018: Solutions To Exercise Set 7Sakshi SharmaNo ratings yet
- 2008 MOP Blue Polynomials-IDocument3 pages2008 MOP Blue Polynomials-IWeerasak BoonwuttiwongNo ratings yet
- Lecture 6: Detection Theory: 1.1 Method of Lagrange MultipliersDocument5 pagesLecture 6: Detection Theory: 1.1 Method of Lagrange MultiplierslakshmiraniNo ratings yet
- ch2 Recursive State EstimationDocument12 pagesch2 Recursive State EstimationksevillanocolinaNo ratings yet
- Imc2023 Day1 SolutionsDocument5 pagesImc2023 Day1 SolutionsAngga NurohmanNo ratings yet
- Solution To Problem Sheet For Conditional Expectation and Random WalkDocument4 pagesSolution To Problem Sheet For Conditional Expectation and Random WalksghaierNo ratings yet
- Coursework 3: Solutions: n−1,α/2 2 n i 2 2 n−1,1−α/2Document3 pagesCoursework 3: Solutions: n−1,α/2 2 n i 2 2 n−1,1−α/2meettoavi059No ratings yet
- Sangap - Solusi (6,13,20,27,34,41,48,55)Document9 pagesSangap - Solusi (6,13,20,27,34,41,48,55)J Esa AditiyaNo ratings yet
- The 1Document5 pagesThe 1mcantimurcanNo ratings yet
- Solutions To OksendalDocument35 pagesSolutions To OksendalJose RamirezNo ratings yet
- Example 6.10 Tunjukkan Bahwa Distribusi Zero-Modified Adalah Distribusi Compund!Document5 pagesExample 6.10 Tunjukkan Bahwa Distribusi Zero-Modified Adalah Distribusi Compund!Dyah Nawangwulan SantosoNo ratings yet
- STA222 Week7Document14 pagesSTA222 Week7Kimondo KingNo ratings yet
- Math 306-Recitation 2: SolutionDocument3 pagesMath 306-Recitation 2: SolutionGarip KontNo ratings yet
- B 2 Stochasticprocesses 2020Document5 pagesB 2 Stochasticprocesses 2020ARISINA BANERJEENo ratings yet
- MA2216 SummaryDocument1 pageMA2216 SummaryKhor Shi-Jie100% (1)
- Est Bloque IIDocument2 pagesEst Bloque IIm4nu.k1r0No ratings yet
- HASTS215 - HSTS215 NOTES Chapter3Document7 pagesHASTS215 - HSTS215 NOTES Chapter3Carl UsheNo ratings yet
- Lecturenotes3 4 ProbabilityDocument14 pagesLecturenotes3 4 ProbabilityarjunvenugopalacharyNo ratings yet
- Lecture Notes 2 1 Probability InequalitiesDocument9 pagesLecture Notes 2 1 Probability InequalitiesHéctor F BonillaNo ratings yet
- MAth 210 Formula SheetDocument4 pagesMAth 210 Formula Sheetstanley.yang.andriodNo ratings yet
- Lecture 3Document4 pagesLecture 3Amazing cricket shocksNo ratings yet
- Elliptic Ding-Iohara-Miki Algebra and Commutative Families of The Elliptic Ruijsenaars OperatorsDocument21 pagesElliptic Ding-Iohara-Miki Algebra and Commutative Families of The Elliptic Ruijsenaars Operatorsapi-225890336No ratings yet
- Exercise Sheet 4 SolutionsDocument5 pagesExercise Sheet 4 SolutionsRyantyler13No ratings yet
- North South University Mat361 Total Marks-30 (Time - 70 Min + 10min)Document8 pagesNorth South University Mat361 Total Marks-30 (Time - 70 Min + 10min)Dipta Kumar Nath 1612720642No ratings yet
- Herstein Beweis Der Transzendenz Der Zahl eDocument2 pagesHerstein Beweis Der Transzendenz Der Zahl eSatishNo ratings yet
- Formula SheetDocument3 pagesFormula SheetSimthembileNo ratings yet
- 13 Independent Random VariablesDocument34 pages13 Independent Random VariablesAntonio JNo ratings yet
- Son2Document6 pagesSon2PUSHPA SAININo ratings yet
- Class - Xii Mathematics Ncert Solutions: S A PADocument10 pagesClass - Xii Mathematics Ncert Solutions: S A PAAmit RajoriaNo ratings yet
- Hw2sol PDFDocument15 pagesHw2sol PDFPei JingNo ratings yet
- Regular and Irregular Singular Points of Odes: 0 P (X) 0, P (X) 1Document4 pagesRegular and Irregular Singular Points of Odes: 0 P (X) 0, P (X) 1Siti MaimunahNo ratings yet
- SonpoissDocument6 pagesSonpoissJAYDEV AMETANo ratings yet
- Discussion Notes 2-6Document3 pagesDiscussion Notes 2-6Mahbod Matt OlfatNo ratings yet
- CONSECUTIVE PRIMES IN SHORT INTERVALS ARTYOM RADOMSKII - Proc Steklov Institute - Maynard - Radziwill-MatomakiDocument82 pagesCONSECUTIVE PRIMES IN SHORT INTERVALS ARTYOM RADOMSKII - Proc Steklov Institute - Maynard - Radziwill-MatomakiSam TaylorNo ratings yet
- MSO201a: Probability and Statistics 2019-20-II Semester Assignment No. 6 Instructor: Neeraj MisraDocument3 pagesMSO201a: Probability and Statistics 2019-20-II Semester Assignment No. 6 Instructor: Neeraj MisraAdarsh BanthNo ratings yet
- Problem Set 4 - SolutionDocument2 pagesProblem Set 4 - SolutiondamnedchildNo ratings yet
- Distribuciones Completo L11Document3 pagesDistribuciones Completo L11Luis Angel Bejar GilNo ratings yet
- 3assignment SolDocument7 pages3assignment SolDalghak KhanNo ratings yet
- 3 - Corrigé TD1 - Complément de ProbabilitésDocument7 pages3 - Corrigé TD1 - Complément de ProbabilitésAbdeLilah Ait TajerNo ratings yet
- s131 Reviewer 002Document14 pagess131 Reviewer 002lucy heartfiliaNo ratings yet
- 1610 ST5214Document4 pages1610 ST5214Lee De ZhangNo ratings yet
- Opgave Punktvis Ligelig KonvDocument5 pagesOpgave Punktvis Ligelig KonvLuca Di MarcantonioNo ratings yet
- WebDocument329 pagesWebDon ShineshNo ratings yet
- Tables of The Legendre Functions P—½+it(x): Mathematical Tables SeriesFrom EverandTables of The Legendre Functions P—½+it(x): Mathematical Tables SeriesNo ratings yet
- Monitoreo de BombasDocument6 pagesMonitoreo de Bombasroberdani12No ratings yet
- Btech Ce 3 Sem Fluid Mechanics Kce303 2022Document2 pagesBtech Ce 3 Sem Fluid Mechanics Kce303 2022shivchauhan0507No ratings yet
- Cennamo - Intransitivity, Object Marking and Event StructureDocument16 pagesCennamo - Intransitivity, Object Marking and Event StructureAugusto PérezNo ratings yet
- Thermal Engineering For The Construction of Large Concrete Arch DamsDocument10 pagesThermal Engineering For The Construction of Large Concrete Arch DamsOscar LopezNo ratings yet
- Switching Theory and Logic DesignDocument89 pagesSwitching Theory and Logic DesignUppalaguptam Hari Satya PriyaNo ratings yet
- Clauses & PhrasesDocument2 pagesClauses & PhrasesmrskumarNo ratings yet
- Distance Determination For An Automobile Environment Using Inverse Perspective Mapping in OpenCVDocument6 pagesDistance Determination For An Automobile Environment Using Inverse Perspective Mapping in OpenCVCristian StrebaNo ratings yet
- Dcs 2019 Questions PaperDocument14 pagesDcs 2019 Questions PaperDASHARATH VISHAWAKARMANo ratings yet
- Vacuum TubeDocument1 pageVacuum Tubejose condoriNo ratings yet
- Coding Bobol ExcelDocument4 pagesCoding Bobol ExcelMuhammad IsmunandarsyahNo ratings yet
- Calculations of The EFG Tensor in DTN Using GIPAW With CASTEP and QE SoftwareDocument12 pagesCalculations of The EFG Tensor in DTN Using GIPAW With CASTEP and QE SoftwareAllen MNo ratings yet
- 02a-2 V-Can2 Xlrteh4300g033850Document1 page02a-2 V-Can2 Xlrteh4300g033850Daniel PricopNo ratings yet
- Altronic V Service Manual (FORM AV SM)Document15 pagesAltronic V Service Manual (FORM AV SM)francis_mouille_iiNo ratings yet
- Determinants of Profitability Performance: An Analysis of Class I Railroads in The United StatesDocument18 pagesDeterminants of Profitability Performance: An Analysis of Class I Railroads in The United StatesJayaniNo ratings yet
- Lampiran Uji Komparasi Ganda ScheffeDocument2 pagesLampiran Uji Komparasi Ganda ScheffeAhmad Safi'iNo ratings yet
- Biology Transportation in PlantsDocument6 pagesBiology Transportation in PlantsTanaka ChirawuNo ratings yet
- StepperDocument7 pagesStepperahmad_syafrudin_1No ratings yet
- Design of The Power Control Module of TDDocument9 pagesDesign of The Power Control Module of TDGurbir SinghNo ratings yet
- Gear Manufacturing ProcessDocument30 pagesGear Manufacturing ProcessSanjay MehrishiNo ratings yet
- Dilution CalculationsDocument2 pagesDilution CalculationsDeden Putra BabakanNo ratings yet
- Geotextiles and Geomembranes: E.C. Lee, R.S. DouglasDocument8 pagesGeotextiles and Geomembranes: E.C. Lee, R.S. DouglasPaula T. LimaNo ratings yet
- Mechanics of Solids by Crandall, Dahl, Lardner, 2nd ChapterDocument118 pagesMechanics of Solids by Crandall, Dahl, Lardner, 2nd Chapterpurijatin100% (2)
- Al-Farabi The Theory of Emanation and THDocument14 pagesAl-Farabi The Theory of Emanation and THManuel Ricardo Fernandes SoaresNo ratings yet
- How Torque Converters Work - HowStuffWorksDocument7 pagesHow Torque Converters Work - HowStuffWorksKrishanu ModakNo ratings yet
- Assigment Sheet Tast 2 Aina MardianaDocument10 pagesAssigment Sheet Tast 2 Aina MardianaAina MardianaNo ratings yet
- Acessórios Cloro Gás - VaccupermDocument28 pagesAcessórios Cloro Gás - Vaccupermbalzac1910% (1)
- 1-A Survey On Mobile Edge Computing: TheCommunication Perspective PDFDocument37 pages1-A Survey On Mobile Edge Computing: TheCommunication Perspective PDFDHRAIEF AmineNo ratings yet
- Example 1 Strip Method VitalDocument15 pagesExample 1 Strip Method Vitalbini122150% (2)
- What Is Trim?: Changed by Moving Masses Already On Board Forward or AFTDocument2 pagesWhat Is Trim?: Changed by Moving Masses Already On Board Forward or AFTamirsyawal87No ratings yet