You might also like
- Instructor's Solution Manual For Neural NetworksDocument40 pagesInstructor's Solution Manual For Neural NetworksshenalNo ratings yet
- A Brief Introduction to MATLAB: Taken From the Book "MATLAB for Beginners: A Gentle Approach"From EverandA Brief Introduction to MATLAB: Taken From the Book "MATLAB for Beginners: A Gentle Approach"Rating: 2.5 out of 5 stars2.5/5 (2)
- TutorialDocument6 pagesTutorialspwajeehNo ratings yet
- Advantages:: Q.No 1.a AnsDocument12 pagesAdvantages:: Q.No 1.a AnsTiwari VivekNo ratings yet
- Homework1 2023Document3 pagesHomework1 2023HAO WUNo ratings yet
- Exercise 03Document5 pagesExercise 03gfjggNo ratings yet
- Fast Training of Multilayer PerceptronsDocument15 pagesFast Training of Multilayer Perceptronsgarima_rathiNo ratings yet
- Insem2 SchemeDocument6 pagesInsem2 SchemeBalathrinath ReddyNo ratings yet
- DSE 5251 Insem1 SchemeDocument8 pagesDSE 5251 Insem1 SchemeBalathrinath ReddyNo ratings yet
- Massachusetts Institute of Technology: 6.867 Machine Learning, Fall 2006 Problem Set 2: SolutionsDocument7 pagesMassachusetts Institute of Technology: 6.867 Machine Learning, Fall 2006 Problem Set 2: Solutionsjuanagallardo01No ratings yet
- HW 1Document4 pagesHW 1sagar0596No ratings yet
- Vmls Additional ExercisesDocument66 pagesVmls Additional ExercisesmarcosilvasegoviaNo ratings yet
- DOS - ReportDocument25 pagesDOS - ReportSagar SimhaNo ratings yet
- 4 Multilayer Perceptrons and Radial Basis FunctionsDocument6 pages4 Multilayer Perceptrons and Radial Basis FunctionsVivekNo ratings yet
- Ex 6Document16 pagesEx 6Pardhasaradhi NallamothuNo ratings yet
- Name-Surya Pratap Singh Enrolment No. - 0829IT181023 Subject - Soft Computing Subject Code - IT701Document17 pagesName-Surya Pratap Singh Enrolment No. - 0829IT181023 Subject - Soft Computing Subject Code - IT701Surya PratapNo ratings yet
- MATLAB Lab Exercises SummaryDocument4 pagesMATLAB Lab Exercises SummaryWisdom Elorm GahNo ratings yet
- Matlab Review PDFDocument19 pagesMatlab Review PDFMian HusnainNo ratings yet
- Performance Analysis of Three ML ClassifiersDocument4 pagesPerformance Analysis of Three ML ClassifiersTiwari VivekNo ratings yet
- CNN Notes on Convolutional Neural NetworksDocument8 pagesCNN Notes on Convolutional Neural NetworksGiri PrakashNo ratings yet
- Support Vector MachinesDocument32 pagesSupport Vector MachinesGeorge PaulNo ratings yet
- Ci - Perceptron Networks1Document43 pagesCi - Perceptron Networks1Bhavisha SutharNo ratings yet
- EE-232 Signals and Systems Lab ReportDocument16 pagesEE-232 Signals and Systems Lab ReportMuhammad Uzair KhanNo ratings yet
- HW 7Document4 pagesHW 7adithya604No ratings yet
- 2802ICT Programming Assignment 2Document6 pages2802ICT Programming Assignment 2Anonymous 07GrYB0sNNo ratings yet
- Neural NetworksDocument37 pagesNeural NetworksOmiarNo ratings yet
- DSCI 303 Machine Learning Problem Set 4Document5 pagesDSCI 303 Machine Learning Problem Set 4Anonymous StudentNo ratings yet
- CS 188 Introduction To Artificial Intelligence Fall 2017 Note 10 Neural Networks: MotivationDocument9 pagesCS 188 Introduction To Artificial Intelligence Fall 2017 Note 10 Neural Networks: MotivationEman JaffriNo ratings yet
- Ex 6Document16 pagesEx 6BirendraKiskuNo ratings yet
- Support Vector NetworkDocument25 pagesSupport Vector NetworkatollorigidoNo ratings yet
- cs188 sp23 Note25Document8 pagescs188 sp23 Note25sondosNo ratings yet
- Ex 4Document15 pagesEx 4api-322416213No ratings yet
- Perceptons Neural NetworksDocument33 pagesPerceptons Neural Networksvasu_koneti5124No ratings yet
- Understanding Backpropagation Algorithm - Towards Data ScienceDocument11 pagesUnderstanding Backpropagation Algorithm - Towards Data ScienceKashaf BakaliNo ratings yet
- NN Lab2Document5 pagesNN Lab2Anne WanningenNo ratings yet
- Multilayer Perceptron and Uppercase Handwritten Characters RecognitionDocument4 pagesMultilayer Perceptron and Uppercase Handwritten Characters RecognitionMiguel Angel Beltran RojasNo ratings yet
- CS 229, Public Course Problem Set #4: Unsupervised Learning and Re-Inforcement LearningDocument5 pagesCS 229, Public Course Problem Set #4: Unsupervised Learning and Re-Inforcement Learningsuhar adiNo ratings yet
- Multi Layer PerceptronDocument62 pagesMulti Layer PerceptronKishan Kumar GuptaNo ratings yet
- Supervised Training Via Error Backpropagation: Derivations: 4.1 A Closer Look at The Supervised Training ProblemDocument32 pagesSupervised Training Via Error Backpropagation: Derivations: 4.1 A Closer Look at The Supervised Training ProblemGeorge TsavdNo ratings yet
- 3 2MLP Extra NotesDocument27 pages3 2MLP Extra Notesyoussef hossamNo ratings yet
- Machine LearningDocument46 pagesMachine Learningsussy.rebab19787No ratings yet
- Richi's Neural Nets SummaryDocument114 pagesRichi's Neural Nets Summaryanton dolganovNo ratings yet
- Networks With Threshold Activation Functions: NavigationDocument6 pagesNetworks With Threshold Activation Functions: NavigationsandmancloseNo ratings yet
- PRu 4Document13 pagesPRu 4Yash ShahNo ratings yet
- Ele366 L1Document3 pagesEle366 L1M.r. KhanNo ratings yet
- Ann Work SheetDocument11 pagesAnn Work SheetTariku TesfayeNo ratings yet
- WSN20100100007 87680380Document5 pagesWSN20100100007 87680380Alan CheeNo ratings yet
- Fast Kernel ClassifiersDocument41 pagesFast Kernel ClassifiersEliseo LopezNo ratings yet
- MorphDocument20 pagesMorphYosueNo ratings yet
- TT1_QBAns1Document15 pagesTT1_QBAns1tejaspathak7No ratings yet
- Competition and Self-Organisation - Kohonen NetsDocument12 pagesCompetition and Self-Organisation - Kohonen NetsAnonymous I0bTVBNo ratings yet
- Refresher: Perceptron Training AlgorithmDocument12 pagesRefresher: Perceptron Training Algorithmeduardo_quintanill_3No ratings yet
- Warsaw University of Technology: Problem DescriptionDocument5 pagesWarsaw University of Technology: Problem DescriptionZaid BOUSLIKHINNo ratings yet
- Module 3 FinalDocument88 pagesModule 3 FinalInfancy PioNo ratings yet
- Hardlim: Otherwise X If Y: W W W W W W WDocument2 pagesHardlim: Otherwise X If Y: W W W W W W WAnimesh JainNo ratings yet
- Lab3Block1 2021-1Document3 pagesLab3Block1 2021-1Alex WidénNo ratings yet
- This Code Fragment Defines A Single Layer With Artificial Neurons, and It Expects Input VariablesDocument9 pagesThis Code Fragment Defines A Single Layer With Artificial Neurons, and It Expects Input Variablescrazzy 8No ratings yet
- Keras Perceptron Model for Handwritten Digit RecognitionDocument9 pagesKeras Perceptron Model for Handwritten Digit Recognitioncrazzy 8No ratings yet
- Machine Learning AssignmentsDocument3 pagesMachine Learning AssignmentsUjesh MauryaNo ratings yet
- CPE343 COA Fall2022 Assignment03Document1 pageCPE343 COA Fall2022 Assignment03Hassam HafeezNo ratings yet
- CH 3Document58 pagesCH 3Hassam HafeezNo ratings yet
- Linux Multithreaded Server ArchitectureDocument36 pagesLinux Multithreaded Server ArchitectureShaunak JagtapNo ratings yet
- Lecture Ch4 PerformanceDocument25 pagesLecture Ch4 PerformanceHassam HafeezNo ratings yet
- Lecture Ch5 Single CycleDocument42 pagesLecture Ch5 Single CycleHassam HafeezNo ratings yet
- CDF-CSC322 Operating SystemsDocument9 pagesCDF-CSC322 Operating SystemsHassam HafeezNo ratings yet
- Cell Membrane Structure and FunctionDocument18 pagesCell Membrane Structure and Functionkevin_ramos007No ratings yet
- 24160-Article Text-39228-1-10-20220603Document10 pages24160-Article Text-39228-1-10-20220603pandji pridjantoNo ratings yet
- SASA ReviewerDocument4 pagesSASA ReviewerMia FayeNo ratings yet
- 3.6.3 Function Block Diagram: 3 Operation TheoryDocument2 pages3.6.3 Function Block Diagram: 3 Operation TheoryAC DCNo ratings yet
- Are Humans Really Beings of LightDocument14 pagesAre Humans Really Beings of LightmazhmiNo ratings yet
- P26 27 Power Thermistor-1900548Document3 pagesP26 27 Power Thermistor-1900548Sndy AjosNo ratings yet
- EC2204 Signals and Systems University Questions for Five UnitsDocument19 pagesEC2204 Signals and Systems University Questions for Five UnitsCrazy EditingsNo ratings yet
- Matching TypeDocument26 pagesMatching TypeDiana HernandezNo ratings yet
- Preent Simple TenseDocument3 pagesPreent Simple TenseHenrique Pires SantosNo ratings yet
- Ogre Classic CountersDocument6 pagesOgre Classic Countersgianduja100% (1)
- UPP PE Tank Sump Installation GuideDocument32 pagesUPP PE Tank Sump Installation GuidelowiyaunNo ratings yet
- PestsDocument2 pagesPestsBlake MalveauxNo ratings yet
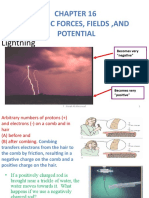
- Electric Forces, Fields, and Potential: LightningDocument164 pagesElectric Forces, Fields, and Potential: LightningIsmail Medhat SalahNo ratings yet
- Markov Analysis of Students Performance and AcadeDocument13 pagesMarkov Analysis of Students Performance and AcadeCross LapenzonaNo ratings yet
- Preliminary Design Review - Ad Lunam HopperDocument100 pagesPreliminary Design Review - Ad Lunam HopperAniketh DevarasettyNo ratings yet
- Thermal Expansion of Iridium at High TemperaturesDocument5 pagesThermal Expansion of Iridium at High TemperaturesAntonio CamaranoNo ratings yet
- Analysis and Design of Precast Concrete Structures BookDocument6 pagesAnalysis and Design of Precast Concrete Structures BookAhmed MostafaNo ratings yet
- Siemens Motor PDFDocument177 pagesSiemens Motor PDFณัฐพล นันไชยNo ratings yet
- UNIT12Document11 pagesUNIT12Jorge Alejandro JuárezNo ratings yet
- Bacon on Marriage and Single LifeDocument2 pagesBacon on Marriage and Single LifeLijimol GeorgeNo ratings yet
- CH 2Document28 pagesCH 2CWHNo ratings yet
- DESIGNING MECHANISMS AND MACHINES: SPRINGSDocument45 pagesDESIGNING MECHANISMS AND MACHINES: SPRINGSAshraf EllamsyNo ratings yet
- Electrical Input Components: Operación de SistemasDocument5 pagesElectrical Input Components: Operación de Sistemasgalvis1020No ratings yet
- Moment Distribution Method ExplainedDocument37 pagesMoment Distribution Method ExplainedSuleiman Yusuf JibrilNo ratings yet
- Lesson PlanDocument1 pageLesson Planapi-551142254No ratings yet
- Soft Skills and Job Satisfaction - Two Models in Comparison Claudio PalumboDocument4 pagesSoft Skills and Job Satisfaction - Two Models in Comparison Claudio PalumboLecture MaterialNo ratings yet
- Production of Phenol Via Chlorobenzene and Caustic ProcessDocument1 pageProduction of Phenol Via Chlorobenzene and Caustic ProcessPatricia MirandaNo ratings yet
- What Is PCB Busbar or PCB Stiffener Busbar in ElectronicsDocument13 pagesWhat Is PCB Busbar or PCB Stiffener Busbar in ElectronicsjackNo ratings yet
- McGraw-Hill Education TOEFL iBT With 3 Practice Tests and DVD (Ebook) (2014) PDFDocument905 pagesMcGraw-Hill Education TOEFL iBT With 3 Practice Tests and DVD (Ebook) (2014) PDFlooks4tranz100% (3)
- Effects of Kahramanmaras Earthquakes in South of Turkey On Livestock ActivitiesDocument10 pagesEffects of Kahramanmaras Earthquakes in South of Turkey On Livestock ActivitiesIJAR JOURNALNo ratings yet
- ChatGPT Money Machine 2024 - The Ultimate Chatbot Cheat Sheet to Go From Clueless Noob to Prompt Prodigy Fast! Complete AI Beginner’s Course to Catch the GPT Gold Rush Before It Leaves You BehindFrom EverandChatGPT Money Machine 2024 - The Ultimate Chatbot Cheat Sheet to Go From Clueless Noob to Prompt Prodigy Fast! Complete AI Beginner’s Course to Catch the GPT Gold Rush Before It Leaves You BehindNo ratings yet
- Scary Smart: The Future of Artificial Intelligence and How You Can Save Our WorldFrom EverandScary Smart: The Future of Artificial Intelligence and How You Can Save Our WorldRating: 4.5 out of 5 stars4.5/5 (55)
- ChatGPT Side Hustles 2024 - Unlock the Digital Goldmine and Get AI Working for You Fast with More Than 85 Side Hustle Ideas to Boost Passive Income, Create New Cash Flow, and Get Ahead of the CurveFrom EverandChatGPT Side Hustles 2024 - Unlock the Digital Goldmine and Get AI Working for You Fast with More Than 85 Side Hustle Ideas to Boost Passive Income, Create New Cash Flow, and Get Ahead of the CurveNo ratings yet
- Artificial Intelligence: The Insights You Need from Harvard Business ReviewFrom EverandArtificial Intelligence: The Insights You Need from Harvard Business ReviewRating: 4.5 out of 5 stars4.5/5 (104)
- Midjourney Mastery - The Ultimate Handbook of PromptsFrom EverandMidjourney Mastery - The Ultimate Handbook of PromptsRating: 4.5 out of 5 stars4.5/5 (2)
- Generative AI: The Insights You Need from Harvard Business ReviewFrom EverandGenerative AI: The Insights You Need from Harvard Business ReviewRating: 4.5 out of 5 stars4.5/5 (2)
- The AI Advantage: How to Put the Artificial Intelligence Revolution to WorkFrom EverandThe AI Advantage: How to Put the Artificial Intelligence Revolution to WorkRating: 4 out of 5 stars4/5 (7)
- ChatGPT Millionaire 2024 - Bot-Driven Side Hustles, Prompt Engineering Shortcut Secrets, and Automated Income Streams that Print Money While You Sleep. The Ultimate Beginner’s Guide for AI BusinessFrom EverandChatGPT Millionaire 2024 - Bot-Driven Side Hustles, Prompt Engineering Shortcut Secrets, and Automated Income Streams that Print Money While You Sleep. The Ultimate Beginner’s Guide for AI BusinessNo ratings yet
- Machine Learning: The Ultimate Beginner's Guide to Learn Machine Learning, Artificial Intelligence & Neural Networks Step by StepFrom EverandMachine Learning: The Ultimate Beginner's Guide to Learn Machine Learning, Artificial Intelligence & Neural Networks Step by StepRating: 4.5 out of 5 stars4.5/5 (19)
- AI and Machine Learning for Coders: A Programmer's Guide to Artificial IntelligenceFrom EverandAI and Machine Learning for Coders: A Programmer's Guide to Artificial IntelligenceRating: 4 out of 5 stars4/5 (2)
- Who's Afraid of AI?: Fear and Promise in the Age of Thinking MachinesFrom EverandWho's Afraid of AI?: Fear and Promise in the Age of Thinking MachinesRating: 4.5 out of 5 stars4.5/5 (13)
- The Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our WorldFrom EverandThe Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our WorldRating: 4.5 out of 5 stars4.5/5 (107)
- Demystifying Prompt Engineering: AI Prompts at Your Fingertips (A Step-By-Step Guide)From EverandDemystifying Prompt Engineering: AI Prompts at Your Fingertips (A Step-By-Step Guide)Rating: 4 out of 5 stars4/5 (1)
- 2084: Artificial Intelligence and the Future of HumanityFrom Everand2084: Artificial Intelligence and the Future of HumanityRating: 4 out of 5 stars4/5 (81)
- Mastering Large Language Models: Advanced techniques, applications, cutting-edge methods, and top LLMs (English Edition)From EverandMastering Large Language Models: Advanced techniques, applications, cutting-edge methods, and top LLMs (English Edition)No ratings yet
- How to Make Money Online Using ChatGPT Prompts: Secrets Revealed for Unlocking Hidden Opportunities. Earn Full-Time Income Using ChatGPT with the Untold Potential of Conversational AI.From EverandHow to Make Money Online Using ChatGPT Prompts: Secrets Revealed for Unlocking Hidden Opportunities. Earn Full-Time Income Using ChatGPT with the Untold Potential of Conversational AI.No ratings yet
- Artificial Intelligence: A Guide for Thinking HumansFrom EverandArtificial Intelligence: A Guide for Thinking HumansRating: 4.5 out of 5 stars4.5/5 (30)
- Power and Prediction: The Disruptive Economics of Artificial IntelligenceFrom EverandPower and Prediction: The Disruptive Economics of Artificial IntelligenceRating: 4.5 out of 5 stars4.5/5 (38)
- Artificial Intelligence: The Complete Beginner’s Guide to the Future of A.I.From EverandArtificial Intelligence: The Complete Beginner’s Guide to the Future of A.I.Rating: 4 out of 5 stars4/5 (15)
- Your AI Survival Guide: Scraped Knees, Bruised Elbows, and Lessons Learned from Real-World AI DeploymentsFrom EverandYour AI Survival Guide: Scraped Knees, Bruised Elbows, and Lessons Learned from Real-World AI DeploymentsNo ratings yet
- Artificial Intelligence & Generative AI for Beginners: The Complete GuideFrom EverandArtificial Intelligence & Generative AI for Beginners: The Complete GuideRating: 5 out of 5 stars5/5 (1)
- The Digital Mind: How Science is Redefining HumanityFrom EverandThe Digital Mind: How Science is Redefining HumanityRating: 4.5 out of 5 stars4.5/5 (2)
- 100M Offers Made Easy: Create Your Own Irresistible Offers by Turning ChatGPT into Alex HormoziFrom Everand100M Offers Made Easy: Create Your Own Irresistible Offers by Turning ChatGPT into Alex HormoziNo ratings yet