You might also like
- 350201F - O&m - I&mdocs 500-55 (-Ce)Document250 pages350201F - O&m - I&mdocs 500-55 (-Ce)Euler Mairena100% (1)
- Intro Parallel Computing PDFDocument58 pagesIntro Parallel Computing PDFCJ JINNo ratings yet
- Disclaimer: - in Preparation of These Slides, Materials Have Been Taken FromDocument33 pagesDisclaimer: - in Preparation of These Slides, Materials Have Been Taken FromZara ShabirNo ratings yet
- Chapter 9 COADocument31 pagesChapter 9 COAJijo XuseenNo ratings yet
- Koneru Lakshmaiah College of Engineering: (Atonomous)Document7 pagesKoneru Lakshmaiah College of Engineering: (Atonomous)KrishnaNo ratings yet
- Introduction To Parallel Processing and Distributed SystemsDocument15 pagesIntroduction To Parallel Processing and Distributed SystemsbahaaalhusainyNo ratings yet
- CS326 Parallel and Distributed Computing: SPRING 2021 National University of Computer and Emerging SciencesDocument33 pagesCS326 Parallel and Distributed Computing: SPRING 2021 National University of Computer and Emerging SciencesNehaNo ratings yet
- BCSE412L - Parallel Computing 03Document11 pagesBCSE412L - Parallel Computing 03aavsgptNo ratings yet
- PDC 1Document41 pagesPDC 1Engr Mir MuhammadNo ratings yet
- Mca 4Document61 pagesMca 4Vivek DubeyNo ratings yet
- Introduction To Parallel ComputingDocument38 pagesIntroduction To Parallel ComputingHetvi ShahNo ratings yet
- PD Computing Introduction. Why Use PDCDocument31 pagesPD Computing Introduction. Why Use PDCmohsanhussain230No ratings yet
- Introduction To: Parallel DistributedDocument32 pagesIntroduction To: Parallel Distributedaliha ghaffarNo ratings yet
- Multicore ComputersDocument18 pagesMulticore ComputersMikias YimerNo ratings yet
- MulticoreDocument3 pagesMulticoremasow50707No ratings yet
- Parallel Computing: Er. Anupama Singh Department of Computer Science & EnggDocument22 pagesParallel Computing: Er. Anupama Singh Department of Computer Science & EnggVinay GuptaNo ratings yet
- CICS 504 Computer OrganizationDocument35 pagesCICS 504 Computer OrganizationdollykaushalNo ratings yet
- Lecture 10Document34 pagesLecture 10MAIMONA KHALIDNo ratings yet
- Lecture Parallel ComputingDocument6 pagesLecture Parallel ComputingChristopher AdvinculaNo ratings yet
- Introduction To ComputingDocument6 pagesIntroduction To ComputingChristopher AdvinculaNo ratings yet
- CSC 1002 Computer Architecture Third AssignmentDocument4 pagesCSC 1002 Computer Architecture Third AssignmentAchyut NeupaneNo ratings yet
- Increasing Factors Which Improves The Performance of Computer in FutureDocument7 pagesIncreasing Factors Which Improves The Performance of Computer in FutureAwais ktkNo ratings yet
- Processor DesignDocument4 pagesProcessor Designapi-3760571No ratings yet
- Ahmad Aljebaly Department of Computer Science Western Michigan UniversityDocument42 pagesAhmad Aljebaly Department of Computer Science Western Michigan UniversityArushi MittalNo ratings yet
- Dsa ExamDocument22 pagesDsa ExamcryhaarishNo ratings yet
- Parallel Computing Lecture # 6: Parallel Computer Memory ArchitecturesDocument16 pagesParallel Computing Lecture # 6: Parallel Computer Memory ArchitecturesKrishnammal SenthilNo ratings yet
- Unit 1Document58 pagesUnit 1Deepak Varma22No ratings yet
- MC9295 U2 QB With AnsDocument5 pagesMC9295 U2 QB With AnsGayatri KommineniNo ratings yet
- 2 Parallel Computer Memory ArchitecturesDocument26 pages2 Parallel Computer Memory Architecturesraja usama201No ratings yet
- P D Group2-2Document6 pagesP D Group2-2Ursulla ZekingNo ratings yet
- Parallel ComputingDocument53 pagesParallel Computingtig1100% (1)
- CS 303 Chapter1, Lecture 3Document18 pagesCS 303 Chapter1, Lecture 3HARSH MITTALNo ratings yet
- Foundations of Sequential and Parallel Programming: Raising A New Generation of LeadersDocument34 pagesFoundations of Sequential and Parallel Programming: Raising A New Generation of Leadersekechi berniveNo ratings yet
- Technical Seminar Report On: "High Performance Computing"Document14 pagesTechnical Seminar Report On: "High Performance Computing"mit_thakkar_2No ratings yet
- Hyper Threading: Concepts & ArchitectureDocument28 pagesHyper Threading: Concepts & Architecturezainvi.sf6018No ratings yet
- Lecture 1 - Introduction To Parallel ComputingDocument32 pagesLecture 1 - Introduction To Parallel ComputingAzamat KazamatNo ratings yet
- Data Parallel ArchitectureDocument17 pagesData Parallel ArchitectureSachin Kumar BassiNo ratings yet
- Lecture 10 Parallel Computing - by FQDocument29 pagesLecture 10 Parallel Computing - by FQaina syafNo ratings yet
- Sistemet Operative Hyrje - Koncepte: LëndaDocument24 pagesSistemet Operative Hyrje - Koncepte: LëndaSara LohajNo ratings yet
- Mansi Kadam PC Lab Assignment 1Document4 pagesMansi Kadam PC Lab Assignment 1SAMINA ATTARINo ratings yet
- Intro HPC Linux GentDocument124 pagesIntro HPC Linux GentNatenczas WojskiNo ratings yet
- Unit Iv Multicore ArchitecturesDocument32 pagesUnit Iv Multicore Architecturesparameshwari pNo ratings yet
- What Is Parallel ComputingDocument9 pagesWhat Is Parallel ComputingLaura DavisNo ratings yet
- 01 Intro Parallel ComputingDocument40 pages01 Intro Parallel ComputingHilmy MuhammadNo ratings yet
- Symmetric Multiprocessing and MicrokernelDocument6 pagesSymmetric Multiprocessing and MicrokernelManoraj PannerselumNo ratings yet
- Multi-Core Processors: Page 1 of 25Document25 pagesMulti-Core Processors: Page 1 of 25nnNo ratings yet
- Lec 5 SharedArch PDFDocument16 pagesLec 5 SharedArch PDFMuhammad ImranNo ratings yet
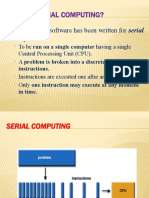
- What Is Serial Computing?: Traditionally, Software Has Been Written For Serial ComputationDocument22 pagesWhat Is Serial Computing?: Traditionally, Software Has Been Written For Serial ComputationDivya NigamNo ratings yet
- Introduction To Parallel ComputingDocument34 pagesIntroduction To Parallel ComputingSuciu AlexNo ratings yet
- ITEC582 Chapter18Document36 pagesITEC582 Chapter18Ana Clara Cavalcante SousaNo ratings yet
- Overview of Parallel Computing: Shawn T. BrownDocument46 pagesOverview of Parallel Computing: Shawn T. BrownKarthik KusumaNo ratings yet
- Chapter 1 Part 2Document33 pagesChapter 1 Part 2Mat Dunlop Bin Senapang GajahNo ratings yet
- Operating Systems: Moumita Patra July-Nov 2019 Ref: Galvin, GagneDocument43 pagesOperating Systems: Moumita Patra July-Nov 2019 Ref: Galvin, GagneSunny KumarNo ratings yet
- FALLSEM2021-22 CSE4001 ETH VL2021220104078 Reference Material I 05-Aug-2021 Module1 (Part 1)Document30 pagesFALLSEM2021-22 CSE4001 ETH VL2021220104078 Reference Material I 05-Aug-2021 Module1 (Part 1)atharva gundawarNo ratings yet
- Multi-Core Processing: Advantages & ChallengesDocument35 pagesMulti-Core Processing: Advantages & Challengesmdrafi555No ratings yet
- Multiprocessors: Cs 152 L1 5 .1 DAP Fa97, U.CBDocument38 pagesMultiprocessors: Cs 152 L1 5 .1 DAP Fa97, U.CBIsaacMedeirosNo ratings yet
- Parallel Processing Unit - 6Document11 pagesParallel Processing Unit - 6Balu vakaNo ratings yet
- Lecture 1 - Introduction To Parallel ComputingDocument32 pagesLecture 1 - Introduction To Parallel ComputingRyan anak GaybristiNo ratings yet
- DFWFWDDocument4 pagesDFWFWDKathlen Mae MerindoNo ratings yet
- Lecture Week - 2 General Parallelism TermsDocument24 pagesLecture Week - 2 General Parallelism TermsimhafeezniaziNo ratings yet
- Operating Systems Interview Questions You'll Most Likely Be AskedFrom EverandOperating Systems Interview Questions You'll Most Likely Be AskedNo ratings yet
- Intelilite NT Ac03: Reference GuideDocument130 pagesIntelilite NT Ac03: Reference GuideadrianpetrisorNo ratings yet
- Operating System MCA BPUT Unit-5Document31 pagesOperating System MCA BPUT Unit-5danger boyNo ratings yet
- Infineon SAA - XC866 DS v01 - 05 enDocument114 pagesInfineon SAA - XC866 DS v01 - 05 enpatricio andradeNo ratings yet
- The Mean of The Sample MeanDocument31 pagesThe Mean of The Sample MeanAngelie Limbago CagasNo ratings yet
- Fortisiem External Systems Configuration Guide PDFDocument622 pagesFortisiem External Systems Configuration Guide PDFaykargilNo ratings yet
- Xbox 720 PDFDocument1 pageXbox 720 PDFMerna1546No ratings yet
- Book 26 Homework & EEDocument90 pagesBook 26 Homework & EESimeon GadzhevNo ratings yet
- Quotation Screw Air Compressor Gas-15al VFC Zq20201005-01Document22 pagesQuotation Screw Air Compressor Gas-15al VFC Zq20201005-01Maurice Alfaro ArnezNo ratings yet
- Js CodeDocument25 pagesJs CodeOm BhandareNo ratings yet
- Training Aids & MaterialsDocument5 pagesTraining Aids & MaterialsJulio Abanto50% (2)
- BMC Remedy It Service Management 9.0 (PDFDrive)Document282 pagesBMC Remedy It Service Management 9.0 (PDFDrive)Omar EhabNo ratings yet
- Puma FAAS 200 WatchDocument47 pagesPuma FAAS 200 WatchJavier GalvanNo ratings yet
- Dharani ProjectDocument76 pagesDharani ProjectSUMIT THAKURNo ratings yet
- Question Paper Code:: (10×2 20 Marks)Document3 pagesQuestion Paper Code:: (10×2 20 Marks)rajkumarsac100% (1)
- 01.machine Fault Codes and SolutionsDocument27 pages01.machine Fault Codes and Solutionschathuranga chandrasekaraNo ratings yet
- 2023 NAT G10 Examiner's Handbook - 05.16.2023Document18 pages2023 NAT G10 Examiner's Handbook - 05.16.2023Francis Joshua MorenoNo ratings yet
- Enterprise Information Systems Project Implementation: A Case Study of ERP in Rolls-RoyceDocument22 pagesEnterprise Information Systems Project Implementation: A Case Study of ERP in Rolls-Roycesandyjbs100% (1)
- Facebook APIDocument8 pagesFacebook APITricahyadi WitdanaNo ratings yet
- Program To Reverse A String Without Using StrrevDocument1 pageProgram To Reverse A String Without Using StrrevLafangey ParindeyNo ratings yet
- Do Not Spread False Information.: Misinformation Is The Spread of False or Mistaken Information That Wasn'tDocument3 pagesDo Not Spread False Information.: Misinformation Is The Spread of False or Mistaken Information That Wasn'tellieNo ratings yet
- Fflpii - M - Pqijoni: Is Will Fonn An S) ) Resources Does &, ND Rh1S - Ri, EDocument25 pagesFflpii - M - Pqijoni: Is Will Fonn An S) ) Resources Does &, ND Rh1S - Ri, ESuraj DasguptaNo ratings yet
- Digital Marketing Assessment 3Document8 pagesDigital Marketing Assessment 3Dharmjeet SinghNo ratings yet
- Turbo HD DVR V3.4.51Build160607 Release Notes - ExternalDocument2 pagesTurbo HD DVR V3.4.51Build160607 Release Notes - Externalcrishtopher saenzNo ratings yet
- Essay Tech AddictedDocument1 pageEssay Tech Addictednurin aizzatiNo ratings yet
- Internet Censorship NodrmDocument352 pagesInternet Censorship NodrmulixesfoxNo ratings yet
- The Operations FunctionDocument35 pagesThe Operations FunctionrajNo ratings yet
- Cisco SD-WAN Hub & Spoke, Mesh Policies LabDocument31 pagesCisco SD-WAN Hub & Spoke, Mesh Policies LabShashank Tripathi100% (1)
- NX 1926 Series Release Notes 1942 PDFDocument81 pagesNX 1926 Series Release Notes 1942 PDFJeferson GevinskiNo ratings yet
- SEnDIng Ecertify Instructions FVDocument4 pagesSEnDIng Ecertify Instructions FVann tzagNo ratings yet