You might also like
- Multicore ComputersDocument21 pagesMulticore Computersmikiasyimer7362No ratings yet
- Thread Level ParallelismDocument21 pagesThread Level ParallelismKashif Mehmood Kashif MehmoodNo ratings yet
- Increasing Factors Which Improves The Performance of Computer in FutureDocument7 pagesIncreasing Factors Which Improves The Performance of Computer in FutureAwais ktkNo ratings yet
- Symmetric Multiprocessing and MicrokernelDocument6 pagesSymmetric Multiprocessing and MicrokernelManoraj PannerselumNo ratings yet
- CS326 Parallel Computing CourseDocument33 pagesCS326 Parallel Computing CourseNehaNo ratings yet
- Parallel Processing & Hyper ThreadingDocument1 pageParallel Processing & Hyper ThreadingRajkumar MishraNo ratings yet
- AOS - Theory - Multi-Processor & Distributed UNIX Operating Systems - IDocument13 pagesAOS - Theory - Multi-Processor & Distributed UNIX Operating Systems - ISujith Ur FrndNo ratings yet
- MulticoreDocument3 pagesMulticoremasow50707No ratings yet
- Lecture 10Document34 pagesLecture 10MAIMONA KHALIDNo ratings yet
- Chapter 9 COADocument31 pagesChapter 9 COAJijo XuseenNo ratings yet
- Computer cluster computing explainedDocument5 pagesComputer cluster computing explainedshaheen sayyad 463No ratings yet
- MULTICORE PROCESSORSDocument12 pagesMULTICORE PROCESSORSJigar KaneriyaNo ratings yet
- Chapter 4Document15 pagesChapter 4MehreenAkramNo ratings yet
- Chapter01 EKT333 Part2 NADocument33 pagesChapter01 EKT333 Part2 NAMat Dunlop Bin Senapang GajahNo ratings yet
- Chapter - 5 Multiprocessors and Thread-Level Parallelism: A Taxonomy of Parallel ArchitecturesDocument41 pagesChapter - 5 Multiprocessors and Thread-Level Parallelism: A Taxonomy of Parallel ArchitecturesraghvendrmNo ratings yet
- Computer System Architecture: Pamantasan NG CabuyaoDocument12 pagesComputer System Architecture: Pamantasan NG CabuyaoBien MedinaNo ratings yet
- Disclaimer: - in Preparation of These Slides, Materials Have Been Taken FromDocument33 pagesDisclaimer: - in Preparation of These Slides, Materials Have Been Taken FromZara ShabirNo ratings yet
- IntroductionDocument34 pagesIntroductionjosephboyong542No ratings yet
- Chapter01 EKT333 Part2 NADocument33 pagesChapter01 EKT333 Part2 NASafwan Md IsaNo ratings yet
- What Is Parallel ComputingDocument9 pagesWhat Is Parallel ComputingLaura DavisNo ratings yet
- Multiprocessors: COMP 211 - Computer Systems Organization and ArchitectureDocument29 pagesMultiprocessors: COMP 211 - Computer Systems Organization and Architecture'Bryan Mendoza'No ratings yet
- Chapter-6 Memory ManagementDocument98 pagesChapter-6 Memory ManagementYasar KhatibNo ratings yet
- Individual Assigment CoaDocument8 pagesIndividual Assigment Coacheruuasrat30No ratings yet
- Tutorial 1 SolutionsDocument5 pagesTutorial 1 SolutionsByronNo ratings yet
- BCSE412L- Parallel Computing 03Document11 pagesBCSE412L- Parallel Computing 03aavsgptNo ratings yet
- Synopsis On "Massive Parallel Processing (MPP) "Document4 pagesSynopsis On "Massive Parallel Processing (MPP) "Jyoti PunhaniNo ratings yet
- Introduction To Parallel and Distributed ComputingDocument29 pagesIntroduction To Parallel and Distributed ComputingBerto ZerimarNo ratings yet
- Ahmad Aljebaly Department of Computer Science Western Michigan UniversityDocument42 pagesAhmad Aljebaly Department of Computer Science Western Michigan UniversityArushi MittalNo ratings yet
- Ch-2 (1)Document51 pagesCh-2 (1)yomem22745No ratings yet
- Multicore Processor ReportDocument19 pagesMulticore Processor ReportDilesh Kumar100% (1)
- Aca NotesDocument148 pagesAca NotesHanisha BavanaNo ratings yet
- Multi-Core Processors: Page 1 of 25Document25 pagesMulti-Core Processors: Page 1 of 25nnNo ratings yet
- Unit 1 NotesDocument31 pagesUnit 1 NotesRanjith SKNo ratings yet
- Thread (Computing) : A Process With Two Threads of Execution, Running On One ProcessorDocument9 pagesThread (Computing) : A Process With Two Threads of Execution, Running On One ProcessorGautam TyagiNo ratings yet
- Coa Unit-3,4 NotesDocument17 pagesCoa Unit-3,4 NotesDeepanshu krNo ratings yet
- Dsa ExamDocument22 pagesDsa ExamcryhaarishNo ratings yet
- Unit 3Document58 pagesUnit 3Subhash Chandra NallaNo ratings yet
- Java ConcurrencyDocument24 pagesJava ConcurrencyKarthik BaskaranNo ratings yet
- Types of Parallel ComputingDocument11 pagesTypes of Parallel Computingprakashvivek990No ratings yet
- Cache Coherence Schemes: An Analysis of Practically Used SchemesDocument12 pagesCache Coherence Schemes: An Analysis of Practically Used SchemesVinay GargNo ratings yet
- PDS Assignment 01Document3 pagesPDS Assignment 01M Shahzaib AliNo ratings yet
- High-Performance Cloud Computing ExplainedDocument58 pagesHigh-Performance Cloud Computing ExplainedDeepak Varma22No ratings yet
- Assignment Os: Saqib Javed 11912Document8 pagesAssignment Os: Saqib Javed 11912Saqib JavedNo ratings yet
- ACA Assignment 4Document16 pagesACA Assignment 4shresth choudharyNo ratings yet
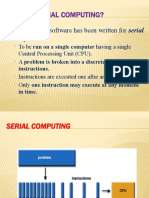
- What Is Serial Computing?: Traditionally, Software Has Been Written For Serial ComputationDocument22 pagesWhat Is Serial Computing?: Traditionally, Software Has Been Written For Serial ComputationDivya NigamNo ratings yet
- Linux Multi-Core ScalabilityDocument7 pagesLinux Multi-Core ScalabilityVISHNUKUMAR RNo ratings yet
- Multiprocessor Architecture SystemDocument10 pagesMultiprocessor Architecture SystemManmeet RajputNo ratings yet
- Need For Memory Hierarchy: (Unit-1,3) (M.M. Chapter 12)Document23 pagesNeed For Memory Hierarchy: (Unit-1,3) (M.M. Chapter 12)Alvin Soriano AdduculNo ratings yet
- PG Cloud Computing Unit IIDocument52 pagesPG Cloud Computing Unit IIdeepthi sanjeevNo ratings yet
- Riding The Next Wave of Embedded Multicore Processors: - Maximizing CPU Performance in A Power-Constrained WorldDocument36 pagesRiding The Next Wave of Embedded Multicore Processors: - Maximizing CPU Performance in A Power-Constrained Worldapi-27099960No ratings yet
- Basic Hardwares For ML - Aravind AriharasudhanDocument23 pagesBasic Hardwares For ML - Aravind AriharasudhanAravind AriharasudhanNo ratings yet
- Architecture CPU, GPU & ClustersDocument11 pagesArchitecture CPU, GPU & ClusterswindtreaterNo ratings yet
- Basics of Operating Systems (IT2019-2) : Assignment VDocument4 pagesBasics of Operating Systems (IT2019-2) : Assignment VGiang LeNo ratings yet
- ITEC582 Chapter18Document36 pagesITEC582 Chapter18Ana Clara Cavalcante SousaNo ratings yet
- CH 4 (Threads)Document8 pagesCH 4 (Threads)Muhammad ImranNo ratings yet
- OS NotesDocument16 pagesOS NotesRahul KumarNo ratings yet
- Multicore Software Development Techniques: Applications, Tips, and TricksFrom EverandMulticore Software Development Techniques: Applications, Tips, and TricksRating: 2.5 out of 5 stars2.5/5 (2)
- Operating Systems Interview Questions You'll Most Likely Be AskedFrom EverandOperating Systems Interview Questions You'll Most Likely Be AskedNo ratings yet
- SAS Programming Guidelines Interview Questions You'll Most Likely Be AskedFrom EverandSAS Programming Guidelines Interview Questions You'll Most Likely Be AskedNo ratings yet
- Complete Workbook Guide For Laptop Maintenance and RepairDocument56 pagesComplete Workbook Guide For Laptop Maintenance and RepairPackShetAdoboNo ratings yet
- Year 10 Ict CourseworkDocument6 pagesYear 10 Ict Courseworkbcr9srp4100% (2)
- Infotech4 Intermediate Unit3 Workbook PDFDocument1 pageInfotech4 Intermediate Unit3 Workbook PDFpsin100% (1)
- CA-PT10W Instruction ManualDocument57 pagesCA-PT10W Instruction Manualshazan888No ratings yet
- DecodeDocument79 pagesDecodeforfives2No ratings yet
- Cea 201 On ThiDocument9 pagesCea 201 On ThiMai Tien Thanh (K16HL)No ratings yet
- Technology in Action: Alan Evans Kendall Martin Mary Anne Poatsy Ninth EditionDocument77 pagesTechnology in Action: Alan Evans Kendall Martin Mary Anne Poatsy Ninth EditionMD ROKNUZZAMANNo ratings yet
- Isco 581 Rapid Transfer Device: Easy To UseDocument2 pagesIsco 581 Rapid Transfer Device: Easy To UsemartinNo ratings yet
- Learn computer organization fundamentalsDocument5 pagesLearn computer organization fundamentalsK-Cube MorongNo ratings yet
- Computer Hardware Store WebsiteDocument2 pagesComputer Hardware Store WebsiteAtul SinghNo ratings yet
- Toshiba A100 ManualDocument171 pagesToshiba A100 Manualsupplier77No ratings yet
- ™mansa College of Education - ICT 2016Document2 pages™mansa College of Education - ICT 2016Mohammed B.S. MakimuNo ratings yet
- Math in The Modern World Module 3 Appreciating Math As A Human EndeavorDocument5 pagesMath in The Modern World Module 3 Appreciating Math As A Human Endeavorbobby Pascual100% (4)
- Module For CSSDocument18 pagesModule For CSSrecquelle danoNo ratings yet
- Library Management System Project ReportDocument33 pagesLibrary Management System Project ReportMafas Munawfar50% (2)
- Maintain and Repair Computer SystemsDocument3 pagesMaintain and Repair Computer SystemsAre Em GeeNo ratings yet
- Cyber Law IntroductionDocument119 pagesCyber Law Introductionjassi7nishadNo ratings yet
- Mil Session 2Document9 pagesMil Session 2rhiantics_kram11No ratings yet
- Riphah University ACP Final ExamDocument3 pagesRiphah University ACP Final ExamUsama ArshadNo ratings yet
- Joe L. Mott, Abraham Kandel, Theodore P. Baker Discrete Mathematics For CompDocument763 pagesJoe L. Mott, Abraham Kandel, Theodore P. Baker Discrete Mathematics For CompShivam Gupta100% (5)
- Computer Science MQP II Pu 2023-24 Version.Document4 pagesComputer Science MQP II Pu 2023-24 Version.Pavan Kumarv100% (1)
- ELECT1/Elective 1> eff<August, 2020Document13 pagesELECT1/Elective 1> eff<August, 2020Jearvi EvidorNo ratings yet
- Engineering: Systems The Glass IndustryDocument13 pagesEngineering: Systems The Glass IndustryAmer AlkalaifhNo ratings yet
- IE 104 - Computer Fundmentals and ProgrammingDocument13 pagesIE 104 - Computer Fundmentals and ProgrammingRomano GabrilloNo ratings yet
- Droids Stats DatabaseDocument123 pagesDroids Stats DatabaseMarcus Baer95% (19)
- 9A12301 Digital Logic Design and Computer OrganizationDocument4 pages9A12301 Digital Logic Design and Computer OrganizationsivabharathamurthyNo ratings yet
- Dip Module 1Document15 pagesDip Module 1Sujay SNo ratings yet
- Contoh SoalDocument4 pagesContoh SoalSyaifuddin NoctisNo ratings yet
- Revised 4th Sem Time Table - FDocument5 pagesRevised 4th Sem Time Table - FJerry boyNo ratings yet
- Software and Operating SystemDocument8 pagesSoftware and Operating SystemFikri AkmalNo ratings yet