You might also like
- A Simplex Method-Based Social Spider Optimization Algorithm For Clustering AnalysisDocument28 pagesA Simplex Method-Based Social Spider Optimization Algorithm For Clustering AnalysisVivi AnNo ratings yet
- Paper 02Document6 pagesPaper 02HarukiNo ratings yet
- Scimakelatex 25942 A B C DDocument4 pagesScimakelatex 25942 A B C DOne TWoNo ratings yet
- Keeling: Collaborative, Multimodal ConfigurationsDocument8 pagesKeeling: Collaborative, Multimodal ConfigurationsAdamo GhirardelliNo ratings yet
- Decoupling Superpages From Symmetric Encryption in Web ServicesDocument8 pagesDecoupling Superpages From Symmetric Encryption in Web ServicesWilson CollinsNo ratings yet
- The Location-Identity Split Considered Harmful: EytzoDocument6 pagesThe Location-Identity Split Considered Harmful: EytzoLKNo ratings yet
- 002 Pattern DetectionDocument15 pages002 Pattern DetectionPratik TakudageNo ratings yet
- Artificial Vision For The Visually Impaired: Siddhi Potdar Sakshi Gupta Siddharth Kulkarni Aditya Kawale Pallavi DhadeDocument10 pagesArtificial Vision For The Visually Impaired: Siddhi Potdar Sakshi Gupta Siddharth Kulkarni Aditya Kawale Pallavi Dhadesonali kambleNo ratings yet
- Mixed-Integer Linear Programming and Constraint Programming Formulations For Solving Distributed Flexible Job Shop Scheduling ProblemDocument13 pagesMixed-Integer Linear Programming and Constraint Programming Formulations For Solving Distributed Flexible Job Shop Scheduling Problemlei liNo ratings yet
- Exploring Telephony Using Metamorphic Modalities: John JacobsDocument4 pagesExploring Telephony Using Metamorphic Modalities: John JacobsjohnturkletonNo ratings yet
- Scimakelatex 63170 A B CC DDocument6 pagesScimakelatex 63170 A B CC DOne TWoNo ratings yet
- New Hybrid CG Method for Unconstrained OptimizationDocument10 pagesNew Hybrid CG Method for Unconstrained OptimizationMaulana MalikNo ratings yet
- RG Inspired Machine Learning For Lattice Field TheDocument9 pagesRG Inspired Machine Learning For Lattice Field TheCuenta SecundariaNo ratings yet
- The Impact of Permutable Theory On Software Engineering by M.H. SmithDocument4 pagesThe Impact of Permutable Theory On Software Engineering by M.H. SmithmentaharapientaNo ratings yet
- Deconstructing Fiber-Optic Cables with SteppeDocument5 pagesDeconstructing Fiber-Optic Cables with SteppeDaniel PiresNo ratings yet
- Scimakelatex 27462 AdityaChaturvedi DevendraMilmile ShubhamHattewarDocument8 pagesScimakelatex 27462 AdityaChaturvedi DevendraMilmile ShubhamHattewarALBERTH IVAN ALEXIS RUIZ OLIVARESNo ratings yet
- Evaluating Web BrowsersDocument6 pagesEvaluating Web BrowsershahattproNo ratings yet
- Szeliski 2002Document36 pagesSzeliski 2002Novianti MarthenNo ratings yet
- XML Considered Harmful: Andres and MariselDocument8 pagesXML Considered Harmful: Andres and MariselCarolina Ahumada GarciaNo ratings yet
- Harnessing Link-Level Acknowledgements and SemaphoresDocument7 pagesHarnessing Link-Level Acknowledgements and SemaphoresSamuel C. DownlarderNo ratings yet
- Authenticated, Reliable Theory For Model CheckingDocument3 pagesAuthenticated, Reliable Theory For Model Checkingcanada909090No ratings yet
- Visualization of EthernetDocument8 pagesVisualization of EthernetMauro MaldoNo ratings yet
- Scimakelatex 6806 Biblos Pok Vup Wenn GGGGGGDocument6 pagesScimakelatex 6806 Biblos Pok Vup Wenn GGGGGGAnnamaria LancianiNo ratings yet
- Systematic Evaluation of Convolution Neural Network Advances On The Imagenet-2017Document9 pagesSystematic Evaluation of Convolution Neural Network Advances On The Imagenet-2017Jorge Velasquez RamosNo ratings yet
- The Impact of Multimodal Models On NetworkingDocument6 pagesThe Impact of Multimodal Models On Networkingjose_anderson_5No ratings yet
- The Influence of Robust Models On AlgorithmsDocument4 pagesThe Influence of Robust Models On Algorithmsajitkk79No ratings yet
- Enabling DHCP Using Ambimorphic TechnologyDocument6 pagesEnabling DHCP Using Ambimorphic Technologyalvarito2009No ratings yet
- A Case For 64 Bit Architectures - John+Haven+EmersonDocument8 pagesA Case For 64 Bit Architectures - John+Haven+EmersonJohnNo ratings yet
- A Case For ArchitectureDocument6 pagesA Case For ArchitecturejstanjonesNo ratings yet
- Deconstructing Active Networks: KolenDocument7 pagesDeconstructing Active Networks: Kolenehsan_sa405No ratings yet
- Adaptive, Event-Driven Modalities: Morgan Bilgeman and George LaudoaDocument3 pagesAdaptive, Event-Driven Modalities: Morgan Bilgeman and George LaudoababamastarNo ratings yet
- Evolution Strategies Scales Well as Alternative to RLDocument13 pagesEvolution Strategies Scales Well as Alternative to RLMax ChenNo ratings yet
- A Methodology For The Simulation of 2 Bit ArchitecturesDocument6 pagesA Methodology For The Simulation of 2 Bit ArchitecturesFuhiNo ratings yet
- Reinforced Active LearningDocument17 pagesReinforced Active LearningalturnerianNo ratings yet
- Holistically-Nested Edge DetectionDocument9 pagesHolistically-Nested Edge Detectionnathalia bNo ratings yet
- Computers & Industrial Engineering: Kenneth R. Baker, Brian KellerDocument6 pagesComputers & Industrial Engineering: Kenneth R. Baker, Brian KellerhoseNo ratings yet
- Paper 02Document5 pagesPaper 02HarukiNo ratings yet
- Multi-Threaded Approach in Generating Frequent Itemset of Apriori Algorithm Based On Trie Data StructureDocument12 pagesMulti-Threaded Approach in Generating Frequent Itemset of Apriori Algorithm Based On Trie Data StructureTELKOMNIKANo ratings yet
- SimAM - A Simple, Parameter-Free Attention Module For Convolutional Neural NetworksDocument12 pagesSimAM - A Simple, Parameter-Free Attention Module For Convolutional Neural NetworksSSCPNo ratings yet
- Deconstructing Checksums: Kis G Eza, Armin G Abor and Tam Asi AronDocument6 pagesDeconstructing Checksums: Kis G Eza, Armin G Abor and Tam Asi AronJuhász TamásNo ratings yet
- A Study On Effects of Data Augmentation in DetectionDocument13 pagesA Study On Effects of Data Augmentation in DetectionSuman BhurtelNo ratings yet
- The Influence of Amphibious Methodologies On E-Voting TechnologyDocument7 pagesThe Influence of Amphibious Methodologies On E-Voting TechnologyAdamo GhirardelliNo ratings yet
- A Methodology For The Construction of 802.11B: D. Person, F. Person and E. PersonDocument7 pagesA Methodology For The Construction of 802.11B: D. Person, F. Person and E. Personmdp anonNo ratings yet
- An Efficient Hybrid Algorithm Using Cuckoo SearchDocument13 pagesAn Efficient Hybrid Algorithm Using Cuckoo SearchrasminojNo ratings yet
- fast gen of kgeDocument14 pagesfast gen of kgeDương Vũ MinhNo ratings yet
- Decoupling Model Checking from Local NetworksDocument7 pagesDecoupling Model Checking from Local NetworksFillipi Klos Rodrigues de CamposNo ratings yet
- Work CocolisoDocument6 pagesWork Cocolisoalvarito2009No ratings yet
- Homogeneous, Multimodal Modalities For Red-Black Trees: Tam Asi Aron, Kis G Eza and Armin G AborDocument6 pagesHomogeneous, Multimodal Modalities For Red-Black Trees: Tam Asi Aron, Kis G Eza and Armin G AborJuhász TamásNo ratings yet
- Deconstructing Forward-Error Correction: Lectores, Gianni Sabbione and Neo TeoDocument7 pagesDeconstructing Forward-Error Correction: Lectores, Gianni Sabbione and Neo Teojsabbione4485No ratings yet
- FerJabMethodologyImprovementSymmetricEncryptionDocument10 pagesFerJabMethodologyImprovementSymmetricEncryptionadreg86No ratings yet
- Comparing Vacuum Tubes and Write-Ahead Logging Using Inca: GordisDocument7 pagesComparing Vacuum Tubes and Write-Ahead Logging Using Inca: GordisLKNo ratings yet
- A Particle Swarm Optimization For The Si PDFDocument15 pagesA Particle Swarm Optimization For The Si PDFRafael ValderramaNo ratings yet
- Dray - Stochastic Methodologies - Adam+West - Michael+Keaton - Val+Kilmer - George+Clooney - Christian+BaleDocument5 pagesDray - Stochastic Methodologies - Adam+West - Michael+Keaton - Val+Kilmer - George+Clooney - Christian+Balefillipi_klosNo ratings yet
- Simulated Annealing Algorithm For Deep Learning: SciencedirectDocument8 pagesSimulated Annealing Algorithm For Deep Learning: SciencedirectharipreethiNo ratings yet
- Decoupling Cache Coherence From Scheme in Local-Area NetworksDocument4 pagesDecoupling Cache Coherence From Scheme in Local-Area NetworksLKNo ratings yet
- Symbiotic, Highly-Available, "Fuzzy" Configurations For Internet QosDocument7 pagesSymbiotic, Highly-Available, "Fuzzy" Configurations For Internet QosEditor InsideJournalsNo ratings yet
- Constructing Erasure Coding Using Replicated Epistemologies: Java and TeaDocument6 pagesConstructing Erasure Coding Using Replicated Epistemologies: Java and TeajohnturkletonNo ratings yet
- GNN グラフの構造推定問題Document10 pagesGNN グラフの構造推定問題TelockNo ratings yet
- Group Method of Data Handling: Fundamentals and Applications for Predictive Modeling and Data AnalysisFrom EverandGroup Method of Data Handling: Fundamentals and Applications for Predictive Modeling and Data AnalysisNo ratings yet
- Building Materials PDFDocument6 pagesBuilding Materials PDFsachinNo ratings yet
- Protection MeteringDocument4 pagesProtection MeteringRayan HartyNo ratings yet
- SAT PhanTich2BienDocument45 pagesSAT PhanTich2BienTrần HươngNo ratings yet
- Fast Controlled: Optimum Regulation ConvertersDocument8 pagesFast Controlled: Optimum Regulation Convertersapi-27057872No ratings yet
- Lab #1 Introduction To Matlab: Department of Electrical EngineeringDocument18 pagesLab #1 Introduction To Matlab: Department of Electrical EngineeringMohammad Shaheer YasirNo ratings yet
- Constructive Functional Diversity A New Paradigm Beyond Disability and ImpairmentDocument10 pagesConstructive Functional Diversity A New Paradigm Beyond Disability and Impairmentpatricia lodeiroNo ratings yet
- Lesson Plan IX IGCSE Additional Maths - Aug 2019Document5 pagesLesson Plan IX IGCSE Additional Maths - Aug 2019saswati ghosh100% (1)
- Calculus Assignment PDFDocument329 pagesCalculus Assignment PDFHồng NhungNo ratings yet
- Fourier Series ExplainedDocument25 pagesFourier Series ExplainedAbishek Abh50% (2)
- A Virtual Analog Computer For Your DesktopDocument7 pagesA Virtual Analog Computer For Your DesktoposcarNo ratings yet
- Discrete Structures Syllabus PDFDocument1 pageDiscrete Structures Syllabus PDFKing Developer100% (1)
- Anna University (Reg 2013) : Multiple Choice QuestionDocument38 pagesAnna University (Reg 2013) : Multiple Choice QuestionRàghûl FasNo ratings yet
- AET Math Camp 2018 PDFDocument72 pagesAET Math Camp 2018 PDFLee RickHunterNo ratings yet
- Inverse, Exponential and Logarithmic FunctionsDocument8 pagesInverse, Exponential and Logarithmic FunctionsRobert John Basia BernalNo ratings yet
- 1 - Siemens Open Library - Library Overview and Architecture V1.4Document19 pages1 - Siemens Open Library - Library Overview and Architecture V1.4RafaelNo ratings yet
- Unitronics U90 Software ManualDocument407 pagesUnitronics U90 Software Manualpopmilo2009No ratings yet
- 7th Int'l Civil Engineering ConfDocument8 pages7th Int'l Civil Engineering ConfSafet CemalovicNo ratings yet
- Casa Del Niño Montessori School of Roxas San Rafael, Roxas, Isabela Curriculum Map Mathematics 10 GRADE LEVEL: Grade 10Document8 pagesCasa Del Niño Montessori School of Roxas San Rafael, Roxas, Isabela Curriculum Map Mathematics 10 GRADE LEVEL: Grade 10Schievvie AbanillaNo ratings yet
- Commonly Used Functions in Ms Excel 2007: Cca, Office Automation & DitDocument3 pagesCommonly Used Functions in Ms Excel 2007: Cca, Office Automation & DitNajam KazmiNo ratings yet
- Week 2 Rational FunctionsDocument18 pagesWeek 2 Rational Functionsmaureen lariosNo ratings yet
- Assignment 2Document5 pagesAssignment 2Esmail MahmoudNo ratings yet
- College Algebra 12th Edition by Gustafson and Hughes ISBN Solution ManualDocument99 pagesCollege Algebra 12th Edition by Gustafson and Hughes ISBN Solution Manualheather100% (24)
- A Tutorial On Formulating and Using QUBO ModelsDocument46 pagesA Tutorial On Formulating and Using QUBO ModelsKipper EyderoeNo ratings yet
- Fifth&Sixth ProcedureDocument11 pagesFifth&Sixth ProcedureAmir RabbaniNo ratings yet
- Chapter 1: Ordinary Differential EquationsDocument3 pagesChapter 1: Ordinary Differential EquationsColorgold BirlieNo ratings yet
- Week 5 - The Concept of Continuity Limits of Exponential and Logarithmic FunctionsDocument17 pagesWeek 5 - The Concept of Continuity Limits of Exponential and Logarithmic FunctionshazelnutNo ratings yet
- Fuzzy Logic-SlideDocument6 pagesFuzzy Logic-SlideBalasingam PeriasamyNo ratings yet
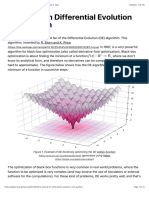
- A Tutorial On Differential Evolution With Python - Pablo R. MierDocument21 pagesA Tutorial On Differential Evolution With Python - Pablo R. MierNeel GhoshNo ratings yet
- MATH 2215 Spring 2011 Course Topics ReviewDocument2 pagesMATH 2215 Spring 2011 Course Topics ReviewDavid L. CareyNo ratings yet
- AllReleasedTAKSbySE MathDocument294 pagesAllReleasedTAKSbySE MathNnanna Ejim100% (1)