You might also like
- Trading and Price Discovery for Crude Oils: Growth and Development of International Oil MarketsFrom EverandTrading and Price Discovery for Crude Oils: Growth and Development of International Oil MarketsNo ratings yet
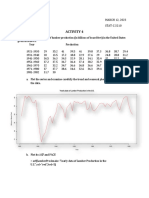
- Time Series Activity 4Document10 pagesTime Series Activity 4Allysa ManatadNo ratings yet
- Assignment1 1Document9 pagesAssignment1 1zhaozhaozizizi2No ratings yet
- Chapter12 Budget Balance and Government DebtDocument33 pagesChapter12 Budget Balance and Government Debtblack pinkNo ratings yet
- ECO364 2012 Final ExamDocument16 pagesECO364 2012 Final ExamChloeNo ratings yet
- ITA - Tin Market Outlook James Willoughby June - 22 PDFDocument12 pagesITA - Tin Market Outlook James Willoughby June - 22 PDFRodrigo RodrigoNo ratings yet
- 4 GrowthDocument36 pages4 GrowthDương NguyễnNo ratings yet
- Longterm - Supplyside - Macro - Models - of - Potential - GrowthDocument52 pagesLongterm - Supplyside - Macro - Models - of - Potential - GrowthMd. Zarif Ibne ArifNo ratings yet
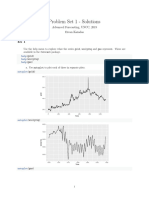
- Assignment1 SolutionDocument21 pagesAssignment1 SolutionxxxNo ratings yet
- Handy, S. (2002) - Accessibility Vs MobilityDocument34 pagesHandy, S. (2002) - Accessibility Vs MobilityMarcos Martinez TiradoNo ratings yet
- Chart With The 3 Data SetsDocument5 pagesChart With The 3 Data SetsBarkın BüyükçakırNo ratings yet
- Macro Workshop FTUDocument7 pagesMacro Workshop FTUHoàng Minh ChâuNo ratings yet
- A Generation of Sociopaths - Reference MaterialDocument30 pagesA Generation of Sociopaths - Reference MaterialWei LeeNo ratings yet
- Slides1 - The Science of MacroDocument17 pagesSlides1 - The Science of Macroalia trikiNo ratings yet
- Ps1sol 6218Document25 pagesPs1sol 6218Ashikur RahmanNo ratings yet
- Beer-Solution R StudioDocument4 pagesBeer-Solution R StudioSieben DoppeltNo ratings yet
- 图解市场Document37 pages图解市场meganmaoNo ratings yet
- Press S.D 0417 - MDocument12 pagesPress S.D 0417 - Midham wahyuNo ratings yet
- Entry and Exit in The Public Charity Sector in TheDocument29 pagesEntry and Exit in The Public Charity Sector in TheBhavesh TrivediNo ratings yet
- Evolution of The International Trading System and Its TrendsDocument20 pagesEvolution of The International Trading System and Its TrendsArike AdeshokanNo ratings yet
- Long Term ViewDocument31 pagesLong Term ViewanisNo ratings yet
- Returning Cash To The Owners: Dividend Policy: Aswath DamodaranDocument69 pagesReturning Cash To The Owners: Dividend Policy: Aswath Damodarangioro_miNo ratings yet
- Brazil Economic ReportDocument217 pagesBrazil Economic Reportaemoraes86No ratings yet
- Chapter 1 MakroDocument25 pagesChapter 1 MakroAndi Kansha AthayaNo ratings yet
- Clean Disruption Transportation PresentationDocument59 pagesClean Disruption Transportation PresentationselimyNo ratings yet
- Week 4 Tutorial Questions (ECF5923)Document3 pagesWeek 4 Tutorial Questions (ECF5923)Anagha SastryNo ratings yet
- Kikkoman Corporation: Corporate and Strategic OverviewDocument42 pagesKikkoman Corporation: Corporate and Strategic OverviewLeinadNo ratings yet
- Anes Timeseries CDF Codebook Var 20220916Document631 pagesAnes Timeseries CDF Codebook Var 20220916Gustavo FranklinNo ratings yet
- SBS DBIA Day 1Document154 pagesSBS DBIA Day 1Risho gitauNo ratings yet
- GDP Vs EmissionsDocument1 pageGDP Vs Emissionsashdownes12No ratings yet
- DIA 2010 Presentacion WDCDocument38 pagesDIA 2010 Presentacion WDCJesús Reinaldo Sanchez AmayaNo ratings yet
- NOVA SBE Introduction To Microeconomics Lectures 4-5Document38 pagesNOVA SBE Introduction To Microeconomics Lectures 4-5Leonardo ViegasNo ratings yet
- Addressing Poverty Challenges in NigeriaDocument5 pagesAddressing Poverty Challenges in NigeriaDELIGHT OLUWASANYANo ratings yet
- The Tail Chaser The Land of The Setting SunDocument77 pagesThe Tail Chaser The Land of The Setting SunDanell BronkhorstNo ratings yet
- Mid Ranja Concept Paper (05-07-2023)Document6 pagesMid Ranja Concept Paper (05-07-2023)Saiba AteeqNo ratings yet
- Essentially - What Does Concrete Sustainability MeanDocument78 pagesEssentially - What Does Concrete Sustainability MeanLuis Alberto Galvez ParedesNo ratings yet
- Environmental Systems and Societies Paper 2 SLDocument7 pagesEnvironmental Systems and Societies Paper 2 SLAfra LamisaNo ratings yet
- S208 Aries NW18G 22-23Document1 pageS208 Aries NW18G 22-23onlyhitmanNo ratings yet
- PGP 1920 IE Lec 2 Agg SCRDocument26 pagesPGP 1920 IE Lec 2 Agg SCRDevendra MahajanNo ratings yet
- Lecture Slides Chap01-1Document27 pagesLecture Slides Chap01-122000492No ratings yet
- Digital Economy (II) : ISMT101Document43 pagesDigital Economy (II) : ISMT101api-3708020No ratings yet
- Argex Mining IncDocument4 pagesArgex Mining IncjayrammenonNo ratings yet
- Natural Gas MonetizationDocument45 pagesNatural Gas MonetizationTobias Okoth100% (1)
- BBT Oct 19Document19 pagesBBT Oct 19BBT ProjectNo ratings yet
- Ganglands in 1990s Korean Gangster FilmDocument27 pagesGanglands in 1990s Korean Gangster FilmAbhinandan GhoseNo ratings yet
- Session 4 SPE Training Exceptional Price PerformanceDocument67 pagesSession 4 SPE Training Exceptional Price PerformanceJarodNo ratings yet
- 18 Pictorial Representation of Data: Bar ChartsDocument2 pages18 Pictorial Representation of Data: Bar ChartsJoi Christian T. AgravanteNo ratings yet
- Stata 12 Graphics: Dawn Koffman Office of Population Research Princeton University June 2013Document49 pagesStata 12 Graphics: Dawn Koffman Office of Population Research Princeton University June 2013Pablo HernandezNo ratings yet
- T-1 JAPAN'S ECONOMIC DEVELOPMENT Unit 2Document28 pagesT-1 JAPAN'S ECONOMIC DEVELOPMENT Unit 2urbsafeNo ratings yet
- Parts Catalog: 9900 Cotton PickerDocument324 pagesParts Catalog: 9900 Cotton PickerBruno AstunNo ratings yet
- 40 - KTS-CM-12Document8 pages40 - KTS-CM-12IrenataNo ratings yet
- Bridge Girder and Beam Framing Plan: BEAM SCHEDULE (C28: Fy414) (LEVEL: 10 M)Document1 pageBridge Girder and Beam Framing Plan: BEAM SCHEDULE (C28: Fy414) (LEVEL: 10 M)cyrus juanezaNo ratings yet
- Areas de Corta FresnosDocument1 pageAreas de Corta FresnosEdith RedónNo ratings yet
- M/S Sidhi Alcast: Production Planning For The Month of Mar.-2017Document13 pagesM/S Sidhi Alcast: Production Planning For The Month of Mar.-2017pulkit gargNo ratings yet
- Avilability & Pricing of GasDocument26 pagesAvilability & Pricing of GasOmkar PantNo ratings yet
- Analysis of UK Road Accident Data (Jan 1969 Dec 1984) : Indian Statistical InstituteDocument15 pagesAnalysis of UK Road Accident Data (Jan 1969 Dec 1984) : Indian Statistical InstituteArijit DuttaNo ratings yet
- Zhao Zihui (A0273946N) Assignment2Document19 pagesZhao Zihui (A0273946N) Assignment2zhaozhaozizizi2No ratings yet
- Linear Regression and CorrelationDocument9 pagesLinear Regression and CorrelationReikin ReikNo ratings yet
- Man City Quiz Book: 1,000 Questions on all things Manchester CityFrom EverandMan City Quiz Book: 1,000 Questions on all things Manchester CityMart MatthewsNo ratings yet
- Ps1sol 6218Document25 pagesPs1sol 6218Ashikur RahmanNo ratings yet
- chp11 AdvancedForecastingModelsDocument32 pageschp11 AdvancedForecastingModelsAshikur RahmanNo ratings yet
- myUniApps SPSSDocument8 pagesmyUniApps SPSSAshikur RahmanNo ratings yet
- Beeps VI Es MDocument47 pagesBeeps VI Es MAshikur RahmanNo ratings yet
- Discussion PapersDocument83 pagesDiscussion PapersAshikur RahmanNo ratings yet
- GRE VocabolaryDocument15 pagesGRE VocabolaryAshikur RahmanNo ratings yet
- Logarithms Explained by James WilcoxDocument7 pagesLogarithms Explained by James WilcoxDanna Sofia Fernandez CorreaNo ratings yet
- Group-1 1BM19EC020 044 045 052Document15 pagesGroup-1 1BM19EC020 044 045 052Vineet ANo ratings yet
- Mathematical Physics Unit - 6 Laplace Transform and ApplicationDocument55 pagesMathematical Physics Unit - 6 Laplace Transform and ApplicationErmias NigussieNo ratings yet
- Marketing Strategy Dissertation ProposalDocument8 pagesMarketing Strategy Dissertation ProposalSparkles Soft75% (4)
- Letter To Chair of The Federal Trade CommissionDocument3 pagesLetter To Chair of The Federal Trade CommissionFOX 17 News Digital StaffNo ratings yet
- BaddiDocument43 pagesBaddi01copy100% (3)
- SUSPENSION SYSTEMS - LectureDocument84 pagesSUSPENSION SYSTEMS - LectureEbrahem Ahmed HafezNo ratings yet
- 2023bske PCVL For Barangay 7216005 JatianDocument56 pages2023bske PCVL For Barangay 7216005 JatianBhin BhinNo ratings yet
- OSY - Chapter1Document11 pagesOSY - Chapter1Rupesh BavgeNo ratings yet
- SAURE LEICA IWAA2018 Laser Tracker StandardsDocument10 pagesSAURE LEICA IWAA2018 Laser Tracker Standardscmm5477No ratings yet
- Landschaftspark Duisburg Nord-Duisburg, Germany: Latz + PartnersDocument4 pagesLandschaftspark Duisburg Nord-Duisburg, Germany: Latz + PartnersAmith KrishnanNo ratings yet
- ĐỀ SỐ 9 đên 16Document28 pagesĐỀ SỐ 9 đên 16Phương Thảo HàNo ratings yet
- Agile E0 Course ID 56031Document8 pagesAgile E0 Course ID 56031krishna prasad73% (145)
- CNG Kits 468 CylinderDocument13 pagesCNG Kits 468 CylinderRoberto HernandezNo ratings yet
- 12HF InstallManual Ver8 WebDocument6 pages12HF InstallManual Ver8 WebUmen AryanNo ratings yet
- Engine MountDocument1 pageEngine MountHarist ArdyNo ratings yet
- 05.2 Power SeriesDocument30 pages05.2 Power SeriesAli AbdullahNo ratings yet
- Oracle Certkiller 1z0-822 140qDocument106 pagesOracle Certkiller 1z0-822 140qDenazareth JesusNo ratings yet
- Tales of A Security GuardDocument127 pagesTales of A Security GuardAlexNo ratings yet
- Trahair (2009) - Buckling Analysis Design of Steel FramesDocument5 pagesTrahair (2009) - Buckling Analysis Design of Steel FramesGogyNo ratings yet
- Allplan 2006 - SchedulesDocument240 pagesAllplan 2006 - SchedulesbathcolNo ratings yet
- Course: EC2P001 Introduction To Electronics Lab: Indian Institute of Technology Bhubaneswar School of Electrical ScienceDocument5 pagesCourse: EC2P001 Introduction To Electronics Lab: Indian Institute of Technology Bhubaneswar School of Electrical ScienceAnik ChaudhuriNo ratings yet
- Cronbach AlphaDocument16 pagesCronbach AlphaBảo TrâmNo ratings yet
- Preca Solutions BrochureDocument16 pagesPreca Solutions BrochurePMC - PRECANo ratings yet
- CBAP Cheat SheetDocument18 pagesCBAP Cheat SheetShruti GuptaNo ratings yet
- Ultima Underworld 2 - Player's GuideDocument40 pagesUltima Underworld 2 - Player's GuideThea_VatarNo ratings yet
- Azure Analytics Assessment QuestionnaireDocument29 pagesAzure Analytics Assessment Questionnaireraju mahtreNo ratings yet
- B Evolution Cisco Jabber and Migration of Jabber To Webex Lab v3 LabDocument136 pagesB Evolution Cisco Jabber and Migration of Jabber To Webex Lab v3 LabFerdinand LouisNo ratings yet
- Aug. 13, 2020 Activity 1 by LJ Diane TuazonDocument2 pagesAug. 13, 2020 Activity 1 by LJ Diane TuazonLj Diane TuazonNo ratings yet
- Mechanical Instruction ManualDocument16 pagesMechanical Instruction ManualMorarescu AndreiNo ratings yet