You might also like
- AIML Module - 03Document34 pagesAIML Module - 03bashantr29No ratings yet
- Mastering Machine Learning Basics: A Beginner's CompanionFrom EverandMastering Machine Learning Basics: A Beginner's CompanionNo ratings yet
- Mod3 - Learning TheoryDocument10 pagesMod3 - Learning TheoryKnightfury MilanNo ratings yet
- AI&ML Module 3Document63 pagesAI&ML Module 3Its MeNo ratings yet
- Jumpstart Your ML Journey: A Beginner's Handbook to SuccessFrom EverandJumpstart Your ML Journey: A Beginner's Handbook to SuccessNo ratings yet
- MACHINE LEARNING Notes-6-64Document59 pagesMACHINE LEARNING Notes-6-64JAYACHANDRAN J 20PHD0157No ratings yet
- Module 3 - AIMLDocument134 pagesModule 3 - AIMLharinisk32No ratings yet
- InTech-Types of Machine Learning AlgorithmsDocument30 pagesInTech-Types of Machine Learning AlgorithmsMohit AroraNo ratings yet
- ML Unit-1Document12 pagesML Unit-120-6616 AbhinayNo ratings yet
- Machine Learning: Version 2 CSE IIT, KharagpurDocument9 pagesMachine Learning: Version 2 CSE IIT, KharagpurSatyanarayan Reddy KNo ratings yet
- Introduction - ML NOTESDocument17 pagesIntroduction - ML NOTESAkash SinghNo ratings yet
- A Seminar Report On Machine LearingDocument10 pagesA Seminar Report On Machine Learingali purityNo ratings yet
- AI Module 4Document38 pagesAI Module 4FaReeD HamzaNo ratings yet
- ML AlgosDocument31 pagesML AlgosvivekNo ratings yet
- Introduction To MLDocument3 pagesIntroduction To ML19- 5b7No ratings yet
- Machine LearningDocument128 pagesMachine LearningRamakrishna ChintalaNo ratings yet
- Notes Artificial Intelligence Unit 5Document11 pagesNotes Artificial Intelligence Unit 5Goku KumarNo ratings yet
- Machine Learning For BeginnerDocument31 pagesMachine Learning For Beginnernithin_vnNo ratings yet
- Reinforcement Learning: Parallelizing Genetic AlgorithmsDocument6 pagesReinforcement Learning: Parallelizing Genetic AlgorithmsDHARINI R SIT 2020No ratings yet
- Reinforcement Learning: Parallelizing Genetic AlgorithmsDocument5 pagesReinforcement Learning: Parallelizing Genetic AlgorithmsDHARINI R SIT 2020No ratings yet
- Machine LearningDocument8 pagesMachine Learningramayanta0% (1)
- 21CS54 Aiml Module3 PPTDocument102 pages21CS54 Aiml Module3 PPTsneha s PatelNo ratings yet
- Unit 3Document10 pagesUnit 3vamsi kiranNo ratings yet
- Aiml M3 C1Document59 pagesAiml M3 C1Vivek TgNo ratings yet
- ML Unit-1 Material WORDDocument27 pagesML Unit-1 Material WORDafreed khanNo ratings yet
- Machine Learning (ML) TechniquesDocument14 pagesMachine Learning (ML) TechniquesMukund TiwariNo ratings yet
- AI - Unit 4 - NotesDocument6 pagesAI - Unit 4 - NotesPavan KumarNo ratings yet
- Active Learning Survey: June 2013Document26 pagesActive Learning Survey: June 2013NajibNo ratings yet
- Introspective Multistrategy Learning: On The Construction of Learning StrategiesDocument55 pagesIntrospective Multistrategy Learning: On The Construction of Learning StrategiesCarlos Andres LopezNo ratings yet
- Ai Unit5 LearningDocument62 pagesAi Unit5 Learning1DA19CS111 PrajathNo ratings yet
- Machine Learning (Fba)Document3 pagesMachine Learning (Fba)Yaseen Nazir MallaNo ratings yet
- Machine LearningDocument9 pagesMachine LearningNishantRajNo ratings yet
- Machine Learning NotesDocument46 pagesMachine Learning Notesmdluffyyy300No ratings yet
- World's Largest Science, Technology & Medicine Open Access Book PublisherDocument32 pagesWorld's Largest Science, Technology & Medicine Open Access Book PublisherRajeshNo ratings yet
- 2702 PDFDocument7 pages2702 PDFAbsolute ZERONo ratings yet
- Terms in DSDocument6 pagesTerms in DSLeandro Rocha RímuloNo ratings yet
- ML Unit 1-NotesDocument21 pagesML Unit 1-NotesAbhi ReddyNo ratings yet
- Decision TreesDocument5 pagesDecision TreesUchennaNo ratings yet
- Exercise 1D2 - TI-5A - 2007411012 - Valerio MeileakhiDocument7 pagesExercise 1D2 - TI-5A - 2007411012 - Valerio MeileakhiRio TobingNo ratings yet
- Machine Learning: 1.1 Types of Problems and TasksDocument9 pagesMachine Learning: 1.1 Types of Problems and TasksAnonymous wKjrBAYRoNo ratings yet
- Key Ideas in Machine LearningDocument11 pagesKey Ideas in Machine LearningzernnNo ratings yet
- Index: Unit No Topic Page NoDocument5 pagesIndex: Unit No Topic Page NoDHARINI R SIT 2020No ratings yet
- SCSA3015 Deep Learning Unit 1 Notes PDFDocument30 pagesSCSA3015 Deep Learning Unit 1 Notes PDFpooja vikirthiniNo ratings yet
- Machine Learning: Louis Fippo FitimeDocument37 pagesMachine Learning: Louis Fippo FitimeFlorian komNo ratings yet
- Machine-Learning ParadigmsDocument32 pagesMachine-Learning ParadigmsSwamy GiriNo ratings yet
- Viva AnswersDocument5 pagesViva Answers4SF19IS072 Preksha AlvaNo ratings yet
- Experiment 1: Aim: Understanding of Machine Learning AlgorithmsDocument7 pagesExperiment 1: Aim: Understanding of Machine Learning Algorithmsharshit gargNo ratings yet
- Robotics AI& ML Sample QuestionsDocument11 pagesRobotics AI& ML Sample QuestionsSamson MumbaNo ratings yet
- CS607 - FinalTerm Subjectives Solved With References by MoaazDocument16 pagesCS607 - FinalTerm Subjectives Solved With References by MoaazJames RodasNo ratings yet
- Computer Science & Engineering: Apex Institute of TechnologyDocument16 pagesComputer Science & Engineering: Apex Institute of Technologymudit nNo ratings yet
- 1 Supervised Learning: 03/27/2024 CSA2001 - Unit VDocument10 pages1 Supervised Learning: 03/27/2024 CSA2001 - Unit Vroyalaclashg6k8No ratings yet
- Machine Learning: Algorithms TypesDocument32 pagesMachine Learning: Algorithms TypesHayderALMakhzomiNo ratings yet
- InTech-Types of Machine Learning Algorithms PDFDocument32 pagesInTech-Types of Machine Learning Algorithms PDFHayderALMakhzomiNo ratings yet
- InTech-Types of Machine Learning AlgorithmsDocument32 pagesInTech-Types of Machine Learning Algorithmsdaniel aryaNo ratings yet
- Machine Learning: Algorithms TypesDocument27 pagesMachine Learning: Algorithms TypesRaviprakash TripathyNo ratings yet
- Different Adv Algorithms For Machine LearningDocument13 pagesDifferent Adv Algorithms For Machine Learningsudhakara.rr359No ratings yet
- Machine Learning Practical FileDocument41 pagesMachine Learning Practical FileAnupriya JainNo ratings yet
- Internship ReportDocument31 pagesInternship ReportNitesh BishtNo ratings yet
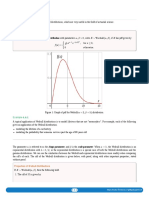
- 4.6 Weibull DistributionsDocument2 pages4.6 Weibull DistributionsJoséBorjNo ratings yet
- Measurement of Grip Strength: Validity and Reliability of The Sphygmomanometer and Jamar Grip DynamometerDocument5 pagesMeasurement of Grip Strength: Validity and Reliability of The Sphygmomanometer and Jamar Grip DynamometerBriel Jake CabusasNo ratings yet
- Descriptive StatisticsDocument17 pagesDescriptive StatisticsPavithra MaddipetlaNo ratings yet
- 3681 EXERCISE - Data Management PDFDocument13 pages3681 EXERCISE - Data Management PDFArjeh CarlNo ratings yet
- Calig Onan Stat121 Stat122Document85 pagesCalig Onan Stat121 Stat122Jimmy Jr Comahig LapeNo ratings yet
- Midterm Project Gec 3Document29 pagesMidterm Project Gec 3Leoncio Jr. ReyNo ratings yet
- 7-Analysis of VarianceDocument8 pages7-Analysis of Variancechobiipiggy26No ratings yet
- Time Series AnalysisDocument44 pagesTime Series AnalysishansrotbachNo ratings yet
- BBLDocument7 pagesBBLSyarifah RaisaNo ratings yet
- SPSS Multiple Regression Analysis TutorialDocument12 pagesSPSS Multiple Regression Analysis TutorialDina ArjuNo ratings yet
- Simbolos Estatistica APADocument2 pagesSimbolos Estatistica APAAlexandra CarvalhoNo ratings yet
- Pengaruh Motivasi Kerja Dan Disiplin Kerja Terhadap Kinerja Karyawan Pada PT Pegadaian (Persero) Cabang NganjukDocument18 pagesPengaruh Motivasi Kerja Dan Disiplin Kerja Terhadap Kinerja Karyawan Pada PT Pegadaian (Persero) Cabang NganjukDeni AbdullatifNo ratings yet
- Midterm Examnation: Introductory EconometricsDocument1 pageMidterm Examnation: Introductory Econometricsngo minh nhatNo ratings yet
- Chapter 5. System Reliability and Reliability Prediction.: Problems & SolutionsDocument29 pagesChapter 5. System Reliability and Reliability Prediction.: Problems & Solutionsdialauchenna100% (1)
- Bollinger Bands RulesDocument2 pagesBollinger Bands RulesHandisaputra LinNo ratings yet
- Status of MIS Data Compilation - MGNREGS-MMJJM ConvergenceDocument1 pageStatus of MIS Data Compilation - MGNREGS-MMJJM ConvergenceBiswaranjan DashNo ratings yet
- 11 Articulo - A Regression-Tree-Based Model For Mining Capital Cost EstimationDocument14 pages11 Articulo - A Regression-Tree-Based Model For Mining Capital Cost EstimationCristian Santivañez MillaNo ratings yet
- Exit Exam Stat and Proba 11Document2 pagesExit Exam Stat and Proba 11Joshua Tala-ocNo ratings yet
- Hypothesis TestingDocument19 pagesHypothesis TestingNei chimNo ratings yet
- Forecasting: © 2007 Pearson EducationDocument58 pagesForecasting: © 2007 Pearson EducationIqbal HussainNo ratings yet
- Classification Ppts 2021Document80 pagesClassification Ppts 2021PRIYA RATHORENo ratings yet
- Demand Forecasting-Quantitative MethodsDocument47 pagesDemand Forecasting-Quantitative MethodsRamteja SpuranNo ratings yet
- Chapter 4 in Managerial EconomicDocument46 pagesChapter 4 in Managerial Economicmyra100% (1)
- Analisis Data SarinaDocument8 pagesAnalisis Data SarinafenyNo ratings yet
- Tugas 1 DOE - Bab2-4Document15 pagesTugas 1 DOE - Bab2-4RatnaPuspitasari50% (2)
- October 17: Great Learning Authored By: ANIMESH HALDERDocument19 pagesOctober 17: Great Learning Authored By: ANIMESH HALDERanimehNo ratings yet
- 05 - BIOE 211 - Normal Distribution and Hypothesis TestingDocument29 pages05 - BIOE 211 - Normal Distribution and Hypothesis TestingJhelloNo ratings yet
- Part 2: Basic Inferential Data Analysis: SynopsisDocument4 pagesPart 2: Basic Inferential Data Analysis: SynopsisfakhruldeenNo ratings yet
- AISC1004: Fall Semester 2021 Tuesdays 10:00AM-12:00PM Soumo MukherjeeDocument37 pagesAISC1004: Fall Semester 2021 Tuesdays 10:00AM-12:00PM Soumo MukherjeeVishakha ShahNo ratings yet
- ANALYSIS OF VARIANCE (Independent Samples) NewDocument18 pagesANALYSIS OF VARIANCE (Independent Samples) NewMano BilliNo ratings yet
- A-Level Chemistry Revision: Cheeky Revision ShortcutsFrom EverandA-Level Chemistry Revision: Cheeky Revision ShortcutsRating: 4 out of 5 stars4/5 (5)
- A-level Biology Revision: Cheeky Revision ShortcutsFrom EverandA-level Biology Revision: Cheeky Revision ShortcutsRating: 5 out of 5 stars5/5 (5)
- Lower Secondary Science Workbook: Stage 8From EverandLower Secondary Science Workbook: Stage 8Rating: 5 out of 5 stars5/5 (1)
- How to Teach Nature Journaling: Curiosity, Wonder, AttentionFrom EverandHow to Teach Nature Journaling: Curiosity, Wonder, AttentionRating: 4.5 out of 5 stars4.5/5 (3)
- Common Core Science 4 Today, Grade 3: Daily Skill PracticeFrom EverandCommon Core Science 4 Today, Grade 3: Daily Skill PracticeRating: 3.5 out of 5 stars3.5/5 (2)
- AI and the Future of Education: Teaching in the Age of Artificial IntelligenceFrom EverandAI and the Future of Education: Teaching in the Age of Artificial IntelligenceRating: 5 out of 5 stars5/5 (1)
- Airplane Flying Handbook: FAA-H-8083-3C (2024)From EverandAirplane Flying Handbook: FAA-H-8083-3C (2024)Rating: 4 out of 5 stars4/5 (12)
- Pharmaceutical Dispensing and CompoundingFrom EverandPharmaceutical Dispensing and CompoundingRating: 4 out of 5 stars4/5 (2)
- The School Garden Curriculum: An Integrated K-8 Guide for Discovering Science, Ecology, and Whole-Systems ThinkingFrom EverandThe School Garden Curriculum: An Integrated K-8 Guide for Discovering Science, Ecology, and Whole-Systems ThinkingNo ratings yet
- An Introduction to the Periodic Table of Elements : Chemistry Textbook Grade 8 | Children's Chemistry BooksFrom EverandAn Introduction to the Periodic Table of Elements : Chemistry Textbook Grade 8 | Children's Chemistry BooksRating: 5 out of 5 stars5/5 (1)
- Teaching STEM Outdoors: Activities for Young ChildrenFrom EverandTeaching STEM Outdoors: Activities for Young ChildrenRating: 5 out of 5 stars5/5 (2)
- GCSE Biology Revision: Cheeky Revision ShortcutsFrom EverandGCSE Biology Revision: Cheeky Revision ShortcutsRating: 4.5 out of 5 stars4.5/5 (2)
- RASPBERRY PI FOR BEGINNERS: TIPS AND TRICKS TO LEARN RASPBERRY PI PROGRAMMINGFrom EverandRASPBERRY PI FOR BEGINNERS: TIPS AND TRICKS TO LEARN RASPBERRY PI PROGRAMMINGNo ratings yet