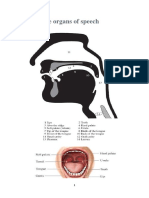
You might also like
- A Course in Phonetics by Peter Ladefoged PDFDocument15 pagesA Course in Phonetics by Peter Ladefoged PDFPralay SutradharNo ratings yet
- Phonetics Phonology Full NotesDocument24 pagesPhonetics Phonology Full NotesMuralitharan Nagalingam100% (4)
- The Language of Clothes - LaurieDocument3 pagesThe Language of Clothes - LauriePatrick Daniel Sagcal0% (1)
- The Mystery of the Seven Vowels: In Theory and PracticeFrom EverandThe Mystery of the Seven Vowels: In Theory and PracticeRating: 4 out of 5 stars4/5 (9)
- Summary GimsonDocument6 pagesSummary GimsonsgambelluribeiroNo ratings yet
- Phonology and PhoneticsDocument23 pagesPhonology and PhoneticsFranz Gerard AlojipanNo ratings yet
- The Articulatory SystemDocument5 pagesThe Articulatory SystemSukma Dwiaugita RahardjoNo ratings yet
- Organ of SpeechDocument10 pagesOrgan of SpeechWinda Rizki Listia DamanikNo ratings yet
- Week - 2 - Consonants - and - Vowels - PPT Filename - UTF-8''Week 2 - Consonants and VowelsDocument30 pagesWeek - 2 - Consonants - and - Vowels - PPT Filename - UTF-8''Week 2 - Consonants and VowelsDũng Trần ViệtNo ratings yet
- Linguistics 2Document45 pagesLinguistics 2Bani AbdullaNo ratings yet
- Ibn Tofail University LevelDocument23 pagesIbn Tofail University LevelImad Es SaouabiNo ratings yet
- Arif Hidayat English PhonologyDocument54 pagesArif Hidayat English PhonologyArif FlouncxNo ratings yet
- PhoneticsDocument17 pagesPhoneticsMohammed DjadaniNo ratings yet
- Phonetics Textbook Unit 1-6 PDFDocument50 pagesPhonetics Textbook Unit 1-6 PDFVirág KovácsNo ratings yet
- Consonant VowelsDocument69 pagesConsonant VowelsMaria Alona SacayananNo ratings yet
- English Phonetics and PhonologyDocument86 pagesEnglish Phonetics and PhonologyAdamsLouisPhan79% (14)
- Gimson Chapter 4Document7 pagesGimson Chapter 4lauponzNo ratings yet
- Unit 8 The English Phonological System (Ii)Document17 pagesUnit 8 The English Phonological System (Ii)Miriam Reinoso SánchezNo ratings yet
- Session II Phonology Presentation-D SnowdenDocument10 pagesSession II Phonology Presentation-D Snowdenapi-218621193No ratings yet
- Linguistics - Unit 3Document5 pagesLinguistics - Unit 3Appas SahaNo ratings yet
- A. Articulatory Phinetic: 1. Air Stream MechanismDocument3 pagesA. Articulatory Phinetic: 1. Air Stream MechanismIis Nur'AzijahNo ratings yet
- Resumen FinalDocument9 pagesResumen FinalmacarenaNo ratings yet
- Sailent Characteristics of English CreoleDocument11 pagesSailent Characteristics of English CreoleVictoria KairooNo ratings yet
- Speech and Theater ExamDocument22 pagesSpeech and Theater ExamCres Jules ArdoNo ratings yet
- دكتور هاشم المحاضرة الاولىDocument6 pagesدكتور هاشم المحاضرة الاولىanmar ahmedNo ratings yet
- Ponology Summary - S6Document38 pagesPonology Summary - S6work WafaNo ratings yet
- Screenshot 2023-02-16 at 10.45.23 AMDocument130 pagesScreenshot 2023-02-16 at 10.45.23 AMduaaghanim45No ratings yet
- Phonetic and PhonologyDocument8 pagesPhonetic and PhonologyIzha AshariNo ratings yet
- How Speech Organs Work in Producing The Speech Sounds?Document33 pagesHow Speech Organs Work in Producing The Speech Sounds?shangar omerNo ratings yet
- Phonetics and PhonologyDocument34 pagesPhonetics and PhonologyArianna BNo ratings yet
- Unit 7 Ta Ündem Formacio ÜnDocument16 pagesUnit 7 Ta Ündem Formacio Ünsergio ruizherguedasNo ratings yet
- Final FonéticaDocument17 pagesFinal Fonéticatita testaNo ratings yet
- Topic 8 PDFDocument15 pagesTopic 8 PDFDave MoonNo ratings yet
- Human Speech OrgansDocument5 pagesHuman Speech OrgansLouise anasthasya altheaNo ratings yet
- Intro To Phonetics & PhonologyDocument20 pagesIntro To Phonetics & Phonologyzainsaghir7576No ratings yet
- I Year B. Tech. Lab NotesDocument39 pagesI Year B. Tech. Lab Notesbalajichakilam2012No ratings yet
- Classification and Description. Acoustic CorrelatesDocument3 pagesClassification and Description. Acoustic CorrelatescalluraNo ratings yet
- English Phonetics:: The Sounds of English LanguageDocument27 pagesEnglish Phonetics:: The Sounds of English LanguageNguyễn Thanh Thảo NguyênNo ratings yet
- Phonetic ADocument28 pagesPhonetic ANina BandalacNo ratings yet
- Phonetic and PhonologyDocument22 pagesPhonetic and PhonologyloganzxNo ratings yet
- PhoneticsDocument20 pagesPhoneticsMohamed Tayeb SELT94% (16)
- The Organs of SpeechDocument6 pagesThe Organs of SpeechAnonymous ToHeyBoEbX100% (1)
- ÔN TẬP PHONETICSDocument53 pagesÔN TẬP PHONETICSChau Nhat ThanhNo ratings yet
- Speech Production A. Standard CompetencyDocument7 pagesSpeech Production A. Standard CompetencyShofa Lanima HalimNo ratings yet
- TOPIC 8. The Phonological System of The English LanguageDocument9 pagesTOPIC 8. The Phonological System of The English LanguageCristinaNo ratings yet
- Tugas Uas PhonologyDocument86 pagesTugas Uas PhonologySofi Mina NurrohmanNo ratings yet
- Chapter 2 PhonologyDocument13 pagesChapter 2 PhonologyEsther Ponmalar CharlesNo ratings yet
- Lesson 2 - The Production of Speech SoundsDocument17 pagesLesson 2 - The Production of Speech SoundsSafar Zitoun MarouaNo ratings yet
- Consonants and Allophonic VariationDocument33 pagesConsonants and Allophonic VariationAgustina AcostaNo ratings yet
- What Is Definition of PhonologyDocument12 pagesWhat Is Definition of PhonologyIsriani IshakNo ratings yet
- Fonetica Resumen Primer ParcialDocument11 pagesFonetica Resumen Primer Parcialemilse RodríguezNo ratings yet
- Topic 8: Phonological System of The English Language Ii: Consonants. Phonetic SymbolsDocument8 pagesTopic 8: Phonological System of The English Language Ii: Consonants. Phonetic SymbolsLaura Irina Lara SánchezNo ratings yet
- 02chapter 2 SoundDocument98 pages02chapter 2 SoundRoger langaNo ratings yet
- 1st Exam - SummaryDocument34 pages1st Exam - SummaryLucía Inés SantagadaNo ratings yet
- U9 Cavity FeaturesDocument3 pagesU9 Cavity Featureslornanyaga4No ratings yet
- Linb09 Final NotesDocument102 pagesLinb09 Final NotesAnwen ZhangNo ratings yet
- The Sounds of EnglishDocument11 pagesThe Sounds of EnglishNicole Calisay VerzosaNo ratings yet
- 4 Phonetics: Speech OrgansDocument8 pages4 Phonetics: Speech OrgansLorz CatalinaNo ratings yet
- Speech OrgansDocument5 pagesSpeech OrgansprivateceeNo ratings yet
- 语言学3Document45 pages语言学3mochen439No ratings yet
- Ishi at 5 - WordDocument6 pagesIshi at 5 - Wordmilacel mitraNo ratings yet
- Pre and Post InspectionDocument1 pagePre and Post Inspectionmilacel mitraNo ratings yet
- Colorful Illustrated Vocabulary WorksheetDocument2 pagesColorful Illustrated Vocabulary Worksheetmilacel mitraNo ratings yet
- Certificate of EmploymentDocument2 pagesCertificate of Employmentmilacel mitraNo ratings yet
- Manukan Ni Joan Certificate of Employment - MaraDocument1 pageManukan Ni Joan Certificate of Employment - Maramilacel mitraNo ratings yet
- Angel Front PageDocument1 pageAngel Front Pagemilacel mitraNo ratings yet
- Mayet Front PageDocument1 pageMayet Front Pagemilacel mitraNo ratings yet
- Wedding ScriptDocument3 pagesWedding Scriptmilacel mitraNo ratings yet
- Omnibus CertificationDocument2 pagesOmnibus Certificationmilacel mitraNo ratings yet
- Agri-Crops Production NC Ii Agri-Crops Production NC Ii: Name: Grade Level: Date: Name: Grade Level: DateDocument1 pageAgri-Crops Production NC Ii Agri-Crops Production NC Ii: Name: Grade Level: Date: Name: Grade Level: Datemilacel mitraNo ratings yet
- GR 11 - Archimedes Seat Plan (2019-2020)Document1 pageGR 11 - Archimedes Seat Plan (2019-2020)milacel mitraNo ratings yet
- GR 11 - Archimedes Seat Plan (2018-2019)Document1 pageGR 11 - Archimedes Seat Plan (2018-2019)milacel mitraNo ratings yet
- SESSION PLAN (Prepare and Cook Meat (PCM) )Document8 pagesSESSION PLAN (Prepare and Cook Meat (PCM) )milacel mitra71% (7)
- Solutions Gold Adv U4 Progress Test Dyslexia Answer KeyDocument2 pagesSolutions Gold Adv U4 Progress Test Dyslexia Answer KeySzymon PaletaNo ratings yet
- De Thi HSG ANH 8 Huyen Lam Thao 22 23Document11 pagesDe Thi HSG ANH 8 Huyen Lam Thao 22 23Đỗ Thị Việt HưngNo ratings yet
- English Exercises Used ToDocument1 pageEnglish Exercises Used ToannaNo ratings yet
- Eng F1 QSDocument13 pagesEng F1 QScharles jumaNo ratings yet
- English Objective t3 PDFDocument2 pagesEnglish Objective t3 PDFLogic AcademyNo ratings yet
- Flip Flop Activity UAODocument21 pagesFlip Flop Activity UAODaniela GómezNo ratings yet
- Eapp Grade 12Document48 pagesEapp Grade 12Morris CarrealNo ratings yet
- Comparative Superlative Practise For PrintingDocument2 pagesComparative Superlative Practise For PrintingMaret KNo ratings yet
- Y6 SPaG RevisionDocument8 pagesY6 SPaG RevisionHeshaniNo ratings yet
- RPT Suggestion Activities For Cefr Created by Nurul FazeelaDocument7 pagesRPT Suggestion Activities For Cefr Created by Nurul FazeelaIna NaaNo ratings yet
- English Dictionary: Business Collocations in The Oxford BusinessDocument4 pagesEnglish Dictionary: Business Collocations in The Oxford BusinessBojana JovanovskaNo ratings yet
- 1 Language & SocietyDocument4 pages1 Language & SocietyMohit SainiNo ratings yet
- Reported Speech: But, If The Reporting Verb Is in The Past Tense, Then Usually We Change The Tenses in TheDocument5 pagesReported Speech: But, If The Reporting Verb Is in The Past Tense, Then Usually We Change The Tenses in TheNicoleta LipanNo ratings yet
- 02 Chapter 2Document80 pages02 Chapter 2dielan wuNo ratings yet
- Past Perfect TenseDocument8 pagesPast Perfect TenseM Taufik HidayatNo ratings yet
- Ist Lecture CommunicationDocument19 pagesIst Lecture Communicationaneela khanNo ratings yet
- DWN 3039Document11 pagesDWN 3039subhashish kumarNo ratings yet
- Early Childhood Bilingualism G2Document5 pagesEarly Childhood Bilingualism G2s.digal.carmelbenedictNo ratings yet
- Easy QuestionsDocument9 pagesEasy QuestionsAhaan DoshiNo ratings yet
- Perangkat Bahasa Jawa Kelas 4 (RPP, Silabus, Prota, Promes)Document40 pagesPerangkat Bahasa Jawa Kelas 4 (RPP, Silabus, Prota, Promes)eko supriyanntoNo ratings yet
- đề 4Document6 pagesđề 4quang trường ngô100% (1)
- English CGDocument321 pagesEnglish CGApple Mae FenizaNo ratings yet
- Spanglish 1Document2 pagesSpanglish 1Laura CNo ratings yet
- Grammar-Modal VerbsDocument2 pagesGrammar-Modal VerbsANA ISABEL SALAS BESNo ratings yet
- Pedis Care BadikDocument15 pagesPedis Care BadikbadikNo ratings yet
- BT Tiếng Anh 1.0Document12 pagesBT Tiếng Anh 1.0Kaisen JutsuNo ratings yet
- Book of Wise Sayings by W. A. CloustonDocument105 pagesBook of Wise Sayings by W. A. Cloustonadelani_oniNo ratings yet
- Ejercicio Interactivo de Past Simple of The Verb To BeDocument1 pageEjercicio Interactivo de Past Simple of The Verb To Bejenniffer urracaNo ratings yet
- COHERENCE - Worksheets - Modular TaskDocument7 pagesCOHERENCE - Worksheets - Modular TaskGinelyn MaralitNo ratings yet