Volume 9, Issue 5, May – 2024 International Journal of Innovative Science and Research Technology
ISSN No:-2456-2165 https://doi.org/10.38124/ijisrt/IJISRT24MAY229
Consistent Robust Analytical Approach for Outlier
Detection in Multivariate Data using Isolation
Forest and Local Outlier Factor
K. Srinarayani1 K. Jagadeeswar Reddy2
Department of Computer Science and Engineering, Department of Computer Science and Engineering,
SRM Institute of Science and Technology, SRM Institute of Science and Technology,
Ramapuram, Chennai, India Ramapuram, Chennai, India
C. Manikanta Reddy3 C. Shanmukh Pranav4
Department of Computer Science and Engineering, Department of Computer Science and Engineering,
SRM Institute of Science and Technology, SRM Institute of Science and Technology,
Ramapuram, Chennai, India Ramapuram, Chennai, India
Abstract:- Outlier detection in real-time from I. INTRODUCTION
multivariate streaming data is an important research
subject in numerous areas. The new presentation of Outlier detection involves identifying and, if necessary,
gradual Neighborhood Anomaly Variable (iLOF) and its removing anomalous observations from data. An outlier can
variations has acquired consideration for their high be broadly defined as an observation that significantly
recognition execution in information streams with deviates from the majority in a dataset, indicating a different
evolving circulations. generative process. Typically, the level of exception
perceptions in a dataset is little, normally lower than 5%.
This paper presents a new intelligent exception
location framework called include rich intelligent In some certifiable applications, refined information
anomaly discovery, which integrates human interaction investigations are depended upon to sift through anomalies
into the detection process to improve performance and and keep up with framework unwavering quality. This is
simplify detection. It offers interactive mechanism that especially urgent in security basic conditions, where the
allows for instinctive client cooperation during every presence of exceptions might recommend unusual action,
vital stage of the fundamental anomaly recognition like extortion, or on the other hand unpredictable running
calculation, for example, thick cell choice, area mindful circumstances in a framework, possibly prompting huge
distance thresholding, and last top exception approval. execution deterrents and at last framework disappointment.
This approach helps resolve the challenge of specifying Albeit a large part of the writing centers around the
key parameters like density and distance thresholds in bothersome properties of exceptions, they can give
other outlier detection methods. significant data about beforehand obscure attributes of the
frameworks and elements that created them. In this way,
Additionally, the system proposes an innovative revealing insight on such attributes and properties can offer
optimization method to enhance grid-based space intriguing bits of knowledge and possibly lead to significant
partitioning. The Local Outlier Factor (LOF) measures revelations.
the level of outlierness of each occasion in light of the
conveyance thickness in the dataset. Higher LOF values There are three essential AI structures for moving
indicate a higher likelihood of an instance being an toward the issue of exception recognition. The first
outlier. Instances with LOF values above a set threshold methodology, unaided exception location, accepts minimal
are identified as outliers. The calculation of LOF values earlier information on the information. Unlabeled
involves several steps, which are detailed in original information are partitioned into groups, and any perceptions
articles for further reference. isolated from the primary groups are hailed as expected
exceptions. The subsequent methodology, directed
Keywords:- Anomaly Detection, Big Data, Big Data Quality, exception location, endeavors to expressly demonstrate and
Data Quality Dimensions, Quality Anomaly Score, Outlier realize what is an exception and which isolates an exception
Detection, Isolation Forest, Local Outlier Factor. from ordinary perceptions.
IJISRT24MAY229 www.ijisrt.com 132
Volume 9, Issue 5, May – 2024 International Journal of Innovative Science and Research Technology
ISSN No:-2456-2165 https://doi.org/10.38124/ijisrt/IJISRT24MAY229
Similarly as with any managed picking up setting, a III. PROPOSED WORK
decent measure of information should have proactively been
expressly named as exceptions or typical perceptions for a The existing anomaly detection system suffers from
classifier to be prepared. The last methodology is connected several limitations that hinder its efficiency and
with semi-administered order and is basically utilized in applicability. Firstly, the approach is somewhat time-
circumstances where marked odd perceptions are difficult to consuming, and these methods typically have high
get. For this situation, a classifier is prepared utilizing just polynomial running times. Consequently, they struggle to
marked instances of ordinary information, through which a meet the demands of current network businesses. Moreover,
meaning of some ordinariness limit is learned. Therefore, these systems have not been thoroughly investigated,
any novel perceptions that fall outside this limit are viewed leaving potential gaps in their understanding and
as anomalies.. application. Additionally, there is a high level of
communication and computation overheads involved,
II. RELATED WORKS further complicating the process. Overall, the existing
system faces multiple challenges that impede its ability to
In this section, we analyze some related work, that provide effective solutions in anomaly detection.
focuses on Anomaly Detection . Shichao Zhou , Wenzheng
Wang and Chentao Gao implemented learning Exploratory data analysis (EDA) the training of
Hyperspectral Inconsistency Location with Unpredictive exploring a dataset and summing up its fundamental
Recurrence Leftover Priors in 2022. They found that their highlights in information examination. It is a type of
model is a fast and easy procedure to perform and has quick engaging investigation that plans to recognize designs,
Calculation Time. The major drawbacks are big payloads patterns, distinguish abnormalities, and test early
and have high polynomial running times. It cannot be speculations. EDA can be completed at different phases of
changed after configuration. the information examination process, yet it is ordinarily led
before a firm theory or ultimate objective is characterized.
Joanna Kosiska and Maciej Tobiasz proposed By and large, EDA centers around understanding the
Recognition of Bunch Abnormalities With ML Methods in qualities of a dataset prior to choosing how to manage that
2022. It is effective for distributed optimization, eliminates dataset. Visual strategies like diagrams, plots, and other
the huge workload of traditional methods and tolerates perceptions are many times utilized in exploratory
Variations. But it is Heavyweight, approach is a bit time- information investigation. This is on the grounds that our
consuming and calculation weight might restrict its further normal example distinguishing capacities make it a lot
application for genuine situations. Hongyan Zhao , Dong simpler to recognize patterns and oddities when they are
Yu , Yue Wang and Biao Wang proposed Upgrading the addressed outwardly. For model, exceptions, which are
Expectation of Mach Number in Air stream With a Relapse information focuses that slant a pattern, stand apart
Based Anomaly Identification Structure in 2022. It Worked considerably more quickly on a disperse chart than they do
with very high degree of confidence, provided the integrity in segments on a bookkeeping sheet.
and nontransferablity and achieved a well-balanced tradeoff
among various parameters. The major drawbacks are Presenting data in a configuration that is justifiable,
heavyweifgt of module and it takes huge time and economic like as pictures or graphs, is critical. It is fundamental to see
time to construct and faced critical design challenges. without any problem the data. High level libraries for
information perception are applied at this underlying step,
Ata-Ur-Rehman , Sameema Tariq , Haroon Farooq , where the focus for the proposed calculation is chosen.
Abdul Jaleel and Syed Muhammad Wasif utilized Moreover, this step is utilized for choosing the test class,
Irregularity Recognition With Molecule Separating for On which is vital for understanding the information in a much
the web Video Observation in 2021. They found that their better way. Through this technique, the target class for
model is effective for distributed optimization and achieved classification was selected effectively.
a well-balanced tradeoff among various parameters with
Simplicity and Explainability.The major drawbacks were The proposed system offers several advantages. Firstly,
complexity of its Real Time Implementation, narrowly it features streamlined and decoupled services. Secondly, it
specialized knowledge and an additional configuration is is easy to identify what is impacted. Thirdly, it possesses a
required. powerful representation capability. Additionally, it improves
operational efficiency. The system is fast and efficient,
Qiqi Zhu and Li Sun proposed Huge Information while also being as accurate as the state-of-the-art
Driven Irregularity Location for Cell Organizations. They algorithms. It boasts quick calculation time, achieving sub-
found that their model is Simple, fast and less complex, optimal performance.
better operational efficiency,Simplicity and
Explainability.The major drawbacks are high complexity of
installing and maintainingand. It is difficult to be used in
large-scale parallel computing. This system is Opportunistic
and uncontrollable.
IJISRT24MAY229 www.ijisrt.com 133
Volume 9, Issue 5, May – 2024 International Journal of Innovative Science and Research Technology
ISSN No:-2456-2165 https://doi.org/10.38124/ijisrt/IJISRT24MAY229
is broken or healthy, while 'load' represents the load
condition. These variables are then appended to each
DataFrame according to the condition of the gear teeth.
After this, the features and labels are split into 'x' and 'y' for
further processing. Additionally, the data is shuffled to avoid
any bias in the subsequent steps.
Data Visualization:
Data visualization plays a crucial role in understanding
the dataset. Visualization helps identify any patterns, trends,
or outliers within the data. Scatter plots are used to visualize
the relationship between the vibration data features, such as
'a1', 'a2', 'a3', and 'a4'. The scatter plots allow us to observe
the distribution and relationship between different features.
Histograms are also utilized to understand the distribution of
these features. This step provides insights into the data and
helps in making informed decisions during the model-
building process.
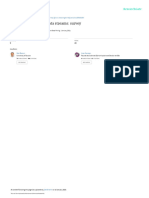
Outlier Detection:
The fourth step involves the detection of anomalies
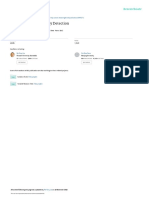
Fig 1 System Architecture of Proposed Method inside the dataset. Anomalies can essentially influence the
presentation of the prescient model. TheElliptic Envelope
The existing algorithm was machine learning . In this method is utilized to detect outliers. This method fits an
model we used isolation forest nad local outlier factor elliptic envelope to the data, thus defining an ellipse around
algorithms. The advantages of the Isolation Forest (IF) and the central data points. Data points outside of this ellipse are
Local Outlier Factor (LOF) are noteworthy.IF offers considered outliers. The contaminated data is then plotted to
scalability to high-dimensional and large datasets, visualize the outliers, aiding in the understanding and
functioning effectively even when irrelevant features are potential removal of these anomalous data points.
included. It can scale up to handle incredibly huge
information sizes and high-layered issues with various Model Building:
unimportant attributes.On the other hand, LOF can extract The final step is to build the predictive maintenance
non-linear features and has good generalizing abilities. It model. For this implementation, we will employ Random
doesn't require complex algorithms to process data. Forest Classifier or AdaBoost Classifier. These models are
However, it adds intricacy what's more, builds the surmising known for their effectiveness in classification tasks. The
above as information successions develop longer. model will be trained on the the preprocessed dataset.
Assessment measurements like exactness, accuracy, review,
IV. IMPLEMENTATION and F1-score will be utilized to evaluate the model's
presentation. This model can then be deployed to predict the
The implementation aims to develop a predictive health status of gear teeth based on vibration data, thus
maintenance system for assessing the health of gear teeth enabling timely maintenance and preventing catastrophic
using vibration data. This predictive system could failures.
potentially prevent equipment failures, reduce downtime,
and increase the lifespan of machinery. The approach V. RESULTS
involves five main steps: data acquisition, data preparation,
data visualization, outlier detection, and model building. This implementation outlines the development of a
predictive maintenance system for assessing gear teeth
Data Acquisition: health using vibration data. By following these steps, one
The first step is to gather vibration data from the can efficiently preprocess the data, detect outliers, and build
healthy and broken gear teeth. The dataset consists of 10 an accurate predictive model. Implementing this system in
samples each for both healthy and broken gear teeth. Each industrial settings can potentially prevent equipment
dataset is read into a pandas DataFrame from CSV files, failures, reduce downtime, and increase the life expectancy
resulting in a comprehensive dataset that combines all the of hardware, subsequently prompting critical cost
healthy and broken gear teeth data. This step ensures a investment funds and further developed proficiency. The
sufficient amount of data for training the model. graphs help to visualize the distribution of the vibration data
features and the outliers detected using the Elliptic Envelope
Data Preparation: method. The graphs help to visualize the distribution of the
The next step involves preparing the dataset. Initially, vibration data features and the outliers detected using the
labels and features are assigned to the data. The 'failure' Elliptic Envelope method.
variable is set as the label, indicating whether the gear tooth
IJISRT24MAY229 www.ijisrt.com 134
Volume 9, Issue 5, May – 2024 International Journal of Innovative Science and Research Technology
ISSN No:-2456-2165 https://doi.org/10.38124/ijisrt/IJISRT24MAY229
Data Volume:
The system can handle a large volume of data as it is
built on Python's pandas and scikit-learn libraries, which are
well-equipped to handle big data.
Model Training Time:
The Random Forest Classifier and AdaBoost
Classifier, being ensemble methods, are efficient and
scalable for large datasets. The training time is reasonable
even with a large volume of data.
Model Prediction Time: The prediction time is also
relatively low, making the system suitable for real-time or
near real-time predictions.
VI. DISCUSSION
The Predictive Maintenance System for Gear Teeth
Health using Vibration Data has Several Advantages
and Implications:
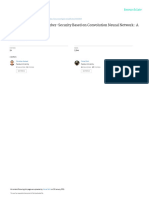
Fig 2 Graph Showing Density Against
Vibration Data Features Early Failure Detection:
By utilizing vibration data, the system can detect
The accuracy of the model is crucial for the success of potential failures in gear teeth before they occur, allowing
the predictive maintenance system. The Random Forest for timely maintenance and preventing catastrophic failures.
Classifier and AdaBoost Classifier models have been chosen
for their high accuracy and efficiency. Reduced Downtime:
By predicting potential failures in advance,
maintenance can be scheduled during planned downtime,
reducing unexpected breakdowns and increasing overall
equipment effectiveness (OEE).
Increased Lifespan of Machinery: Timely maintenance
can increase the lifespan of machinery and reduce the need
for frequent replacements, resulting in cost savings for the
organization.
Real-Time Prediction:
The system provides near real-time predictions,
enabling swift action to be taken to prevent equipment
failure.
VII. CONCLUSION & FUTURE WORKS
We saw that the one-class support vector machines are
planned expecting exact information sets and perform
ineffectively on filthy information on the grounds that the
ideal model is emphatically impacted by exceptions. In view
Fig 3 Detecting Outliers Red Colours are of this anomalies are probably going to become help vectors
Considered to be Outliers and impact the choice surface of the model a ton. To ease
this we involved Secluded Woodland for the grimy
Scalability: information situation that assesses each article with regard to
The scalability of the predictive maintenance system is the rest of the informational index. Moreover we can prune
the model by eliminating the top recognized exceptions and
crucial for its applicability in real-world scenarios. The
system should be capable of handling large amounts of data just fit most of the information.
and provide accurate predictions in a reasonable amount of
time. The scalability of this system depends on the following
factors:
IJISRT24MAY229 www.ijisrt.com 135
Volume 9, Issue 5, May – 2024 International Journal of Innovative Science and Research Technology
ISSN No:-2456-2165 https://doi.org/10.38124/ijisrt/IJISRT24MAY229
Later on we are keen on exploring how human
collaborations can be incorporated with other existing
exception location strategies to lay out a more broad
methodology for exception recognition with human
communication. We are additionally keen on fostering an
inquiry language for exception location which can convey
the capability of exception location as well as likewise
utilizes intelligent anomaly identification instruments that
we have created.
REFERENCES
[1]. Elouataoui Widad, Elmendili Saida, Youssef Gahi
Quality Anomaly Detection Using Predictive
Techniques: An Extensive Big Data Quality
Framework for Reliable Data Analysis IEEE Access,
2023
[2]. Shichao Zhou, Wenzheng Wang, Chentao Gao
Learning-Free Hyperspectral Anomaly Detection
With Unpredictive Frequency Residual Priors IEEE
Journal of Selected Topics in Applied Earth
Observations and Remote Sensing, 2022
[3]. Joanna Kosinska, Maciej Tobiasz Detection of
Cluster Anomalies With ML Techniques IEEE
Access, 2022
[4]. Ata-Ur-Rehman, Sameema Tariq, Haroon Farooq,
Abdul Jaleel, Syed Muhammad Wasif Anomaly
Detection With Particle Filtering for Online Video
Surveillance IEEE Access, 2021
[5]. Maryam Assafo, Peter Langend Arfer A TOPSIS-
Assisted Feature Selection Scheme and SOM-Based
Anomaly Detection for Milling Tools Under
Different Operating Conditions IEEE Access, 2021
[6]. Qiqi Zhu,Li Sun Big Data Driven Anomaly Detection
for Cellular Networks IEEE Access, 2020
[7]. Scott Miau,Wei-Hsi Hung River Flooding
Forecasting and Anomaly Detection Based on Deep
Learning IEEE Access, 2020
[8]. Tsotsope Daniel Ramotsoela, Gerhard Petrus
Hancke, Adnan M. Abu-Mahfouz Behavioural
Intrusion Detection in Water Distribution Systems
Using Neural Networks IEEE Access, 2020
[9]. Yumna Zahid, Muhammad Atif Tahir, Nouman M.
Durrani, Ahmed Bouridane IBaggedFCNet: An
Ensemble framework for anomaly detection IEEE
access, 2020
[10]. Pan Xiong, Cheng Long, Huiyu Zhou, Xuemin
Zhang, Xuhui Shen GNSS TEC-Based Earthquake
Ionospheric Perturbation Detection Using a Novel
Deep Learning Framework IEEE Journal of Selected
Topics in Applied Earth observations and Remote
sensing, 2022
IJISRT24MAY229 www.ijisrt.com 136
You might also like
- Mte511 - v2 - Theorists - Worksheet 2Document5 pagesMte511 - v2 - Theorists - Worksheet 2connie thomeczek100% (1)
- Survey On Outlier Detection For Support Vector MachineDocument4 pagesSurvey On Outlier Detection For Support Vector MachineIIR indiaNo ratings yet
- Cheng 2019Document8 pagesCheng 2019Bruno RavioloNo ratings yet
- Enhancing Time Series Anomaly Detection: A Hybrid Model Fusion ApproachDocument13 pagesEnhancing Time Series Anomaly Detection: A Hybrid Model Fusion Approachijcijournal1821No ratings yet
- DeepAntDocument15 pagesDeepAntJaya SrivastavaNo ratings yet
- Process Fault Diagnosis - AAMDocument61 pagesProcess Fault Diagnosis - AAMsaynapogado18No ratings yet
- 1 s2.0 S0957417423014963 MainDocument20 pages1 s2.0 S0957417423014963 Mainm.ramakiNo ratings yet
- Generative Adversarial Active Learning For Unsupervised Outlier DetectionDocument13 pagesGenerative Adversarial Active Learning For Unsupervised Outlier DetectionSAGNIK GHOSALNo ratings yet
- Anomaly Detection Using Machine LearningDocument10 pagesAnomaly Detection Using Machine Learningvishal jainNo ratings yet
- Anomaly Detection and Classification Using DT and DLDocument10 pagesAnomaly Detection and Classification Using DT and DLbarracudaNo ratings yet
- Symmetry: Unsupervised Anomaly Detection Approach For Time-Series in Multi-Domains Using Deep Reconstruction ErrorDocument22 pagesSymmetry: Unsupervised Anomaly Detection Approach For Time-Series in Multi-Domains Using Deep Reconstruction ErrorSakshi ChoudharyNo ratings yet
- Using Operational Research and Advanced Informatics For C - 2003 - IFAC ProceediDocument6 pagesUsing Operational Research and Advanced Informatics For C - 2003 - IFAC ProceediNGUYEN MANHNo ratings yet
- IForest ASDDocument6 pagesIForest ASDSAGNIK GHOSALNo ratings yet
- Cse 12Document12 pagesCse 12rupa reddyNo ratings yet
- Annual Reviews in Control: Khaoula Tidriri, Nizar Chatti, Sylvain Verron, Teodor TiplicaDocument19 pagesAnnual Reviews in Control: Khaoula Tidriri, Nizar Chatti, Sylvain Verron, Teodor TiplicaHusnain AliNo ratings yet
- Data Mining Techniques and ApplicationsDocument6 pagesData Mining Techniques and ApplicationsIJRASETPublicationsNo ratings yet
- A Multi Model Approach A Data Engineering Driven Pipeline Model For Detecting Anomaly in Sensor Data Using Stacked LSTMDocument8 pagesA Multi Model Approach A Data Engineering Driven Pipeline Model For Detecting Anomaly in Sensor Data Using Stacked LSTMIJRASETPublicationsNo ratings yet
- Data Mining Approaches.Document6 pagesData Mining Approaches.saajithNo ratings yet
- Event Based Imaging Using Neural NetworksDocument6 pagesEvent Based Imaging Using Neural NetworksInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Students' Admission Prediction Using GRBST With Distributed Data MiningDocument5 pagesStudents' Admission Prediction Using GRBST With Distributed Data MiningshridharbombNo ratings yet
- (C) 2019 Application of Outlier Detection Using Re-Weighted Least Squares and R-Squared For IoT Extracted DataDocument6 pages(C) 2019 Application of Outlier Detection Using Re-Weighted Least Squares and R-Squared For IoT Extracted Datadr.awawdeh.moathNo ratings yet
- TKDD 11Document45 pagesTKDD 11Xin LiNo ratings yet
- Impact of Outlier Removal and Normalization ApproaDocument6 pagesImpact of Outlier Removal and Normalization ApproaPoojaNo ratings yet
- 4 getPDF - JSPDocument4 pages4 getPDF - JSPLuis Felipe Rau AndradeNo ratings yet
- A Monte Carlo-Rough Based Mixed-Integer Probablistic Non-Linear Programming Model For Predicting and Minimizing Unavailability of Power System ComponentsDocument6 pagesA Monte Carlo-Rough Based Mixed-Integer Probablistic Non-Linear Programming Model For Predicting and Minimizing Unavailability of Power System ComponentsakshatNo ratings yet
- DT 444Document19 pagesDT 444htlt215No ratings yet
- Multi-Level Association Rules For Anomaly Extraction in Backbone Network With Improved Scalability and EfficiencyDocument8 pagesMulti-Level Association Rules For Anomaly Extraction in Backbone Network With Improved Scalability and EfficiencyInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- A Survey On Outlier Detection TechniquesDocument37 pagesA Survey On Outlier Detection Techniquesvishal jainNo ratings yet
- 2020 - Rezaeianjouybari - Review - DL For PHM State of The Art and ChellengesDocument29 pages2020 - Rezaeianjouybari - Review - DL For PHM State of The Art and ChellengesjudarangocaNo ratings yet
- 1 s2.0 S2665917422000411 MainDocument6 pages1 s2.0 S2665917422000411 MainrsoekartaNo ratings yet
- Data Mining and CDocument85 pagesData Mining and Cvintageshades96No ratings yet
- Towards More Accurate Iris Recognition System by Using Hybrid Approach For Feature Extraction Along With ClassifierDocument12 pagesTowards More Accurate Iris Recognition System by Using Hybrid Approach For Feature Extraction Along With ClassifierIJRES teamNo ratings yet
- 1 s2.0 S0950705121006626 MainDocument16 pages1 s2.0 S0950705121006626 MainAhmed AmamouNo ratings yet
- Kova Rasan 2018Document11 pagesKova Rasan 2018Gany JatayuNo ratings yet
- IEEE Conference TemplaDocument4 pagesIEEE Conference TemplaAshlesha ShettyNo ratings yet
- Semi-Supervised Bearing Fault Diagnosis and Classification Using Variational Autoencoder-Based Deep Generative ModelsDocument11 pagesSemi-Supervised Bearing Fault Diagnosis and Classification Using Variational Autoencoder-Based Deep Generative ModelsRaouf BenabdesselamNo ratings yet
- Jurnal 3Document15 pagesJurnal 3fikaadillah3No ratings yet
- Feature Selection Based On Information Gain: Related PapersDocument5 pagesFeature Selection Based On Information Gain: Related Papersnijo groupeNo ratings yet
- Deep State Inference Toward Behavioral Model Inference of Black-Box Software SystemsDocument16 pagesDeep State Inference Toward Behavioral Model Inference of Black-Box Software SystemsomanNo ratings yet
- Data Mining - KTUweb PDFDocument82 pagesData Mining - KTUweb PDFHari krishnaNo ratings yet
- An Ensemble Design of Intrusion Detection System For Handling Uncertainty Using Neutrosophic Logic ClassifierDocument9 pagesAn Ensemble Design of Intrusion Detection System For Handling Uncertainty Using Neutrosophic Logic ClassifierMia AmaliaNo ratings yet
- Automatic Root Cause Analysis For LTE Networks Based On Unsupervised TechniquesDocument18 pagesAutomatic Root Cause Analysis For LTE Networks Based On Unsupervised TechniquesMoazzam TiwanaNo ratings yet
- Outlierdetectionoverdatastreams SurveyDocument24 pagesOutlierdetectionoverdatastreams SurveyJalel Eddine HajlaouiNo ratings yet
- Anomaly Detection 2Document8 pagesAnomaly Detection 2Aishwarya SinghNo ratings yet
- Kirchheim PyTorch-OOD A Library ForDocument10 pagesKirchheim PyTorch-OOD A Library ForFrank OrtmeierNo ratings yet
- Krishnendu PCB-IT602BDocument11 pagesKrishnendu PCB-IT602Bk6595055No ratings yet
- Mathematics 10 01273Document17 pagesMathematics 10 01273Shaba ShelNo ratings yet
- Effectively Error Detection On Cloud by Using Time Efficient TechniqueDocument3 pagesEffectively Error Detection On Cloud by Using Time Efficient TechniqueKumara SNo ratings yet
- Online Entropy-Based Discretization For Data Streaming ClassificationDocument12 pagesOnline Entropy-Based Discretization For Data Streaming ClassificationHungNo ratings yet
- Data Warehouse PresentationDocument28 pagesData Warehouse PresentationPrasad DhanikondaNo ratings yet
- DATA ANALYTIC 3 MARKS QDocument10 pagesDATA ANALYTIC 3 MARKS QaaarghyaNo ratings yet
- IEEE Conference TemplateDocument4 pagesIEEE Conference TemplateAshlesha ShettyNo ratings yet
- Feature Selection Based On Fuzzy EntropyDocument5 pagesFeature Selection Based On Fuzzy EntropyInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- A Novel Algorithm For Network Anomaly Detection Using Adaptive Machine LearningDocument12 pagesA Novel Algorithm For Network Anomaly Detection Using Adaptive Machine LearningB AnandNo ratings yet
- Applying Data Mining in Prediction and Classification of Urban TrafficDocument5 pagesApplying Data Mining in Prediction and Classification of Urban TrafficgraviphotonNo ratings yet
- Outlier Detection TechniquesDocument11 pagesOutlier Detection Techniquesvishal jainNo ratings yet
- Transfer Learning Enhanced Vision-Based Human Activity RecognitionDocument15 pagesTransfer Learning Enhanced Vision-Based Human Activity RecognitiondhaferfaroukNo ratings yet
- Manifold Learning Techniques For Unsupervised Anomaly DetectionDocument12 pagesManifold Learning Techniques For Unsupervised Anomaly DetectionAlex ShevchenkoNo ratings yet
- Presentation On Data MiningDocument51 pagesPresentation On Data MiningAbadir Tahir Mohamed100% (1)
- Multi-Dimensional Feature Fusion and Stacking Ensemble MechanismDocument14 pagesMulti-Dimensional Feature Fusion and Stacking Ensemble MechanismyousufNo ratings yet
- Digital Data Forgetting A Machine Learning ApproachDocument6 pagesDigital Data Forgetting A Machine Learning ApproachIJRASETPublicationsNo ratings yet
- Design and Development of Multi-Featured Medical StretcherDocument4 pagesDesign and Development of Multi-Featured Medical StretcherInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- EmoConnect: Nurturing Trust and Relationship Bonds in Alzheimer’s ConversationsDocument3 pagesEmoConnect: Nurturing Trust and Relationship Bonds in Alzheimer’s ConversationsInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Smart and Secure Home with ChatbotDocument9 pagesSmart and Secure Home with ChatbotInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Skin Disease Detection and Remedial SystemDocument7 pagesSkin Disease Detection and Remedial SystemInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Unlocking Sentiments: Enhancing IOCL Petrol Pump ExperiencesDocument8 pagesUnlocking Sentiments: Enhancing IOCL Petrol Pump ExperiencesInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Development of Smart Ground Fault Location Model for Radial Distribution SystemDocument14 pagesDevelopment of Smart Ground Fault Location Model for Radial Distribution SystemInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Reading Intervention Through “Brigada Sa Pagbasa”: Viewpoint of Primary Grade TeachersDocument3 pagesReading Intervention Through “Brigada Sa Pagbasa”: Viewpoint of Primary Grade TeachersInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Preparation and Identification of Magnetic Iron Nanoparticle based on a Natural Hydrogel and its Performance in Targeted Drug DeliveryDocument17 pagesPreparation and Identification of Magnetic Iron Nanoparticle based on a Natural Hydrogel and its Performance in Targeted Drug DeliveryInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Application of Game Theory in Solving Urban Water Challenges in Ibadan-North Local Government Area, Oyo State, NigeriaDocument9 pagesApplication of Game Theory in Solving Urban Water Challenges in Ibadan-North Local Government Area, Oyo State, NigeriaInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- On the Development of a Threat Driven Model for Campus NetworkDocument14 pagesOn the Development of a Threat Driven Model for Campus NetworkInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Esophageal Melanoma - A Rare NeoplasmDocument3 pagesEsophageal Melanoma - A Rare NeoplasmInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Application of Plant Growth Promoting Rhizobacteria on Vegetative Growth in Chili Plants (Capsicum frutescens L.)Document7 pagesApplication of Plant Growth Promoting Rhizobacteria on Vegetative Growth in Chili Plants (Capsicum frutescens L.)International Journal of Innovative Science and Research TechnologyNo ratings yet
- Global Warming Reduction Proposal AssessmentDocument6 pagesGlobal Warming Reduction Proposal AssessmentInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Firm Size as a Mediator between Inventory Management Andperformance of Nigerian CompaniesDocument8 pagesFirm Size as a Mediator between Inventory Management Andperformance of Nigerian CompaniesInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Exploring the Post-Annealing Influence on Stannous Oxide Thin Films via Chemical Bath Deposition Technique: Unveiling Structural, Optical, and Electrical DynamicsDocument7 pagesExploring the Post-Annealing Influence on Stannous Oxide Thin Films via Chemical Bath Deposition Technique: Unveiling Structural, Optical, and Electrical DynamicsInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- PHREEQ C Modelling Tool Application to Determine the Effect of Anions on Speciation of Selected Metals in Water Systems within Kajiado North Constituency in KenyaDocument71 pagesPHREEQ C Modelling Tool Application to Determine the Effect of Anions on Speciation of Selected Metals in Water Systems within Kajiado North Constituency in KenyaInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Osho Dynamic Meditation; Improved Stress Reduction in Farmer Determine by using Serum Cortisol and EEG (A Qualitative Study Review)Document8 pagesOsho Dynamic Meditation; Improved Stress Reduction in Farmer Determine by using Serum Cortisol and EEG (A Qualitative Study Review)International Journal of Innovative Science and Research TechnologyNo ratings yet
- Mandibular Mass Revealing Vesicular Thyroid Carcinoma A Case ReportDocument5 pagesMandibular Mass Revealing Vesicular Thyroid Carcinoma A Case ReportInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- A Study to Assess the Knowledge Regarding Teratogens Among the Husbands of Antenatal Mother Visiting Obstetrics and Gynecology OPD of Sharda Hospital, Greater Noida, UpDocument5 pagesA Study to Assess the Knowledge Regarding Teratogens Among the Husbands of Antenatal Mother Visiting Obstetrics and Gynecology OPD of Sharda Hospital, Greater Noida, UpInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- The Impact of Music on Orchid plants Growth in Polyhouse EnvironmentsDocument5 pagesThe Impact of Music on Orchid plants Growth in Polyhouse EnvironmentsInternational Journal of Innovative Science and Research Technology100% (1)
- Detection of Phishing WebsitesDocument6 pagesDetection of Phishing WebsitesInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Sustainable Energy Consumption Analysis through Data Driven InsightsDocument16 pagesSustainable Energy Consumption Analysis through Data Driven InsightsInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Vertical Farming System Based on IoTDocument6 pagesVertical Farming System Based on IoTInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Realigning Curriculum to Simplify the Challenges of Multi-Graded Teaching in Government Schools of KarnatakaDocument5 pagesRealigning Curriculum to Simplify the Challenges of Multi-Graded Teaching in Government Schools of KarnatakaInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Investigating Non-Newtonian Fluid Behavior in Hydrocyclones Via Computational Fluid DynamicsDocument18 pagesInvestigating Non-Newtonian Fluid Behavior in Hydrocyclones Via Computational Fluid DynamicsInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Influence of Principals’ Promotion of Professional Development of Teachers on Learners’ Academic Performance in Kenya Certificate of Secondary Education in Kisii County, KenyaDocument13 pagesInfluence of Principals’ Promotion of Professional Development of Teachers on Learners’ Academic Performance in Kenya Certificate of Secondary Education in Kisii County, KenyaInternational Journal of Innovative Science and Research Technology100% (1)
- Detection and Counting of Fake Currency & Genuine Currency Using Image ProcessingDocument6 pagesDetection and Counting of Fake Currency & Genuine Currency Using Image ProcessingInternational Journal of Innovative Science and Research Technology100% (9)
- An Efficient Cloud-Powered Bidding MarketplaceDocument5 pagesAn Efficient Cloud-Powered Bidding MarketplaceInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Review on Childhood Obesity: Discussing Effects of Gestational Age at Birth and Spotting Association of Postterm Birth with Childhood ObesityDocument10 pagesReview on Childhood Obesity: Discussing Effects of Gestational Age at Birth and Spotting Association of Postterm Birth with Childhood ObesityInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Entrepreneurial Creative Thinking and Venture Performance: Reviewing the Influence of Psychomotor Education on the Profitability of Small and Medium Scale Firms in Port Harcourt MetropolisDocument10 pagesEntrepreneurial Creative Thinking and Venture Performance: Reviewing the Influence of Psychomotor Education on the Profitability of Small and Medium Scale Firms in Port Harcourt MetropolisInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- G107 - 4 - Individual File Submission - 20007322 - 001Document6 pagesG107 - 4 - Individual File Submission - 20007322 - 001Lim Liang XuanNo ratings yet
- Data Sheet Kabelindo Nyfgby Cable Based On Kabelindo Datasheet PDF FreeDocument10 pagesData Sheet Kabelindo Nyfgby Cable Based On Kabelindo Datasheet PDF FreeRisa RidmaNo ratings yet
- General Mathematics: Jelvis PelayoDocument30 pagesGeneral Mathematics: Jelvis PelayoJenna Alyssa BaligatNo ratings yet
- Structures Handbook 2016-17Document217 pagesStructures Handbook 2016-17Swaminathan VivekananthamNo ratings yet
- TRC 9000238Document12 pagesTRC 9000238PRAVIN KAWLENo ratings yet
- Methods For Evaluating Overconsolidation Ratio From Piezocone Sounding ResultsDocument13 pagesMethods For Evaluating Overconsolidation Ratio From Piezocone Sounding ResultsBárbara RodríguezNo ratings yet
- Electric Motor - Generator PDFDocument2 pagesElectric Motor - Generator PDFGus EdiNo ratings yet
- Physics: Pearson Edexcel International GCSE (9-1)Document36 pagesPhysics: Pearson Edexcel International GCSE (9-1)superpooh-1100% (1)
- Manual TC 900 RiDocument3 pagesManual TC 900 RiedgardoNo ratings yet
- Mysterious Lights and Crop Circles - Linda Moulton HoweDocument399 pagesMysterious Lights and Crop Circles - Linda Moulton HoweFritz Katz100% (1)
- Skills: Team Member A Team Member B Team Member C Team Member D Team Member E Team Member F Team Member G Team Member HDocument5 pagesSkills: Team Member A Team Member B Team Member C Team Member D Team Member E Team Member F Team Member G Team Member HSaadNo ratings yet
- Module 1, 3 of The Submitted Self Monitoring Reports (SMRS) For The Recent YearDocument10 pagesModule 1, 3 of The Submitted Self Monitoring Reports (SMRS) For The Recent YearedenbulataoNo ratings yet
- Perhitungan Tiangan Type W1 BaruDocument2 pagesPerhitungan Tiangan Type W1 Barucandra kurniawan ramadhaniNo ratings yet
- 1Document19 pages1Ahammad KabeerNo ratings yet
- Kapiel Raaj LessonsDocument1 pageKapiel Raaj LessonsAshok Kumar K R0% (2)
- Likerts Management SystemDocument2 pagesLikerts Management SystemNabeel Yaqub100% (1)
- Name (SN, FN M.I) : - Grade and Section: - Date of EvaluationDocument2 pagesName (SN, FN M.I) : - Grade and Section: - Date of EvaluationAngela RaeNo ratings yet
- Process Design EngineeringDocument196 pagesProcess Design EngineeringAriyanto Purnomo IlBewokll100% (2)
- PHD Thesis Microbiology PDFDocument4 pagesPHD Thesis Microbiology PDFPaperWritingHelpUK100% (4)
- Hydrology Notes 2Document14 pagesHydrology Notes 2NzezwaNo ratings yet
- 1996-Chen, C. L., & Ling, C. H. (1996) - Granular-Flow Rheology Role of Shear-Rate Number in Transition RegimeDocument12 pages1996-Chen, C. L., & Ling, C. H. (1996) - Granular-Flow Rheology Role of Shear-Rate Number in Transition Regimehayel elnaggarNo ratings yet
- 2021 2022 Be Narrative ReportDocument2 pages2021 2022 Be Narrative ReportCeleste Macalalag100% (2)
- Lesson 1 Unit 2 in Environmental ScienceDocument5 pagesLesson 1 Unit 2 in Environmental Sciencemobile legendsNo ratings yet
- ORAL-COMMUNICATION Quarter-1 Module-5 ZarcenoDocument7 pagesORAL-COMMUNICATION Quarter-1 Module-5 ZarcenoElmerito MelindoNo ratings yet
- Bharathiar University::Coimbatore-641 046 B. Sc. Mathematics Degree Course - Cbcs Pattern Scheme of ExaminationDocument31 pagesBharathiar University::Coimbatore-641 046 B. Sc. Mathematics Degree Course - Cbcs Pattern Scheme of ExaminationAjay AdithyaNo ratings yet
- Fundamentals PDFDocument8 pagesFundamentals PDFAli YıldırımNo ratings yet
- Work Immersion - TemplateDocument59 pagesWork Immersion - TemplateMaricel AiranNo ratings yet
- River ProcessesDocument2 pagesRiver ProcessesMoniqueNo ratings yet
- Developing Effective Paragraphs With Topic Sentences and Supporting DetailsDocument21 pagesDeveloping Effective Paragraphs With Topic Sentences and Supporting DetailsRochelle SantillanNo ratings yet