You might also like
- Microcontroller HardwareDocument45 pagesMicrocontroller HardwaredineshlathiaNo ratings yet
- Storage Technology BasicsDocument193 pagesStorage Technology BasicsphanisanyNo ratings yet
- Chapter 02 Computer Organization and Design, Fifth Edition: The Hardware/Software Interface (The Morgan Kaufmann Series in Computer Architecture and Design) 5th EditionDocument93 pagesChapter 02 Computer Organization and Design, Fifth Edition: The Hardware/Software Interface (The Morgan Kaufmann Series in Computer Architecture and Design) 5th EditionPriyanka Meena75% (4)
- 1 Introduction To Parallel ComputingDocument58 pages1 Introduction To Parallel ComputingSNo ratings yet
- Module 4Document40 pagesModule 4Tharushi DewminiNo ratings yet
- Lect10 SMPCCDocument27 pagesLect10 SMPCCbassam abutraabNo ratings yet
- CSCI 8150 Advanced Computer ArchitectureDocument19 pagesCSCI 8150 Advanced Computer ArchitectureHarsh BhardwajNo ratings yet
- Cis620 15 00Document36 pagesCis620 15 00Heval TariQNo ratings yet
- CS82 Advanced Computer Architecture: Parallel Computer Models 1.2 Multiprocessors and MulticomputersDocument19 pagesCS82 Advanced Computer Architecture: Parallel Computer Models 1.2 Multiprocessors and MulticomputersamithaNo ratings yet
- Multiprocessor Systems GuideDocument14 pagesMultiprocessor Systems GuideAmet koko TaroNo ratings yet
- Topic 1 Introduction To Embedded System (ISMAIL - FKEUTM 2020)Document37 pagesTopic 1 Introduction To Embedded System (ISMAIL - FKEUTM 2020)Aya AmirNo ratings yet
- Advanced Computer Architecture Unit 1Document23 pagesAdvanced Computer Architecture Unit 1anujaNo ratings yet
- Cache Coherence in Bus-Based Shared Memory MultiprocessorsDocument37 pagesCache Coherence in Bus-Based Shared Memory Multiprocessorsmadhu75No ratings yet
- Parallel Processors: Session 2Document32 pagesParallel Processors: Session 2Tapti SoniNo ratings yet
- 001-99111 AN99111 Parallel NOR Flash Memory An OverviewDocument8 pages001-99111 AN99111 Parallel NOR Flash Memory An Overviewprashant wagreNo ratings yet
- Memory Organization and Hierarchy GuideDocument16 pagesMemory Organization and Hierarchy GuideNeel RavalNo ratings yet
- Understanding Non-Uniform Memory Access - NUMADocument3 pagesUnderstanding Non-Uniform Memory Access - NUMAANILPETWALNo ratings yet
- Distributed Memory ArchitectureDocument48 pagesDistributed Memory Architecturesanzog raiNo ratings yet
- COA-Unit 4 Memory OraganizationDocument60 pagesCOA-Unit 4 Memory Oraganizationtanuja rajputNo ratings yet
- Directory-Based Cache Coherence: Parallel Computer Architecture and Programming CMU 15-418/15-618, Spring 2019Document56 pagesDirectory-Based Cache Coherence: Parallel Computer Architecture and Programming CMU 15-418/15-618, Spring 2019YAAKOV SOLOMONNo ratings yet
- Shared Memory Multiprocessors OverviewDocument45 pagesShared Memory Multiprocessors Overviewvadla77No ratings yet
- Computer Architecture: Multiprocessors Shared Memory Architectures Prof. Jerry Breecher CSCI 240 Fall 2003Document24 pagesComputer Architecture: Multiprocessors Shared Memory Architectures Prof. Jerry Breecher CSCI 240 Fall 2003nighat_princesNo ratings yet
- Week 2 - The Memory System and Instruction Set ArchitectureDocument19 pagesWeek 2 - The Memory System and Instruction Set ArchitectureGame AccountNo ratings yet
- MIcroprocessor SystemDocument22 pagesMIcroprocessor SystemumairNo ratings yet
- Chapter 02Document63 pagesChapter 02Hisham Al-SagerNo ratings yet
- Low-Power SRAM-Based Delay Buffer Using Gated Driver TreeDocument49 pagesLow-Power SRAM-Based Delay Buffer Using Gated Driver TreeydsrajuNo ratings yet
- Multiprocessors: Cs 152 L1 5 .1 DAP Fa97, U.CBDocument38 pagesMultiprocessors: Cs 152 L1 5 .1 DAP Fa97, U.CBIsaacMedeirosNo ratings yet
- Multi Processor ClassificationDocument11 pagesMulti Processor ClassificationAnikNo ratings yet
- 08 Multiprocessing HistoryDocument38 pages08 Multiprocessing HistoryAli Ali RazaNo ratings yet
- Computer Memory: New Syllabus 2022-23Document20 pagesComputer Memory: New Syllabus 2022-23kalen chandra RoyNo ratings yet
- Unit 5: Distributed Multiprocessor ArchitecturesDocument48 pagesUnit 5: Distributed Multiprocessor Architecturessushil@irdNo ratings yet
- 02 Parallel Plateforms Architecture-IDocument25 pages02 Parallel Plateforms Architecture-IUmar KhalidNo ratings yet
- 14 NVMDocument46 pages14 NVMmaykelnawarNo ratings yet
- 2ad6a430 1637912349895Document51 pages2ad6a430 1637912349895roopshree udaiwalNo ratings yet
- Shared Memory Multiprocessors ArchitectureDocument99 pagesShared Memory Multiprocessors ArchitecturePopoNo ratings yet
- Why Choose A Multiprocessor?Document17 pagesWhy Choose A Multiprocessor?M Ijaz ChohanNo ratings yet
- Intel'S 3D Xpoint: A Revolutionary Breakthrough in Memory TechnologyDocument6 pagesIntel'S 3D Xpoint: A Revolutionary Breakthrough in Memory TechnologyJose Jestin GeorgeNo ratings yet
- CS6461 - Computer Architecture Fall 2016 Morris Lancaster - Memory SystemsDocument66 pagesCS6461 - Computer Architecture Fall 2016 Morris Lancaster - Memory Systems闫麟阁No ratings yet
- EE6304 Lecture8 Mem HierarchyDocument54 pagesEE6304 Lecture8 Mem HierarchyAshish SoniNo ratings yet
- Theory of Computation Programming Locality of Reference Computer StorageDocument4 pagesTheory of Computation Programming Locality of Reference Computer Storagesitu_elecNo ratings yet
- Challenges of Memory Management ON MODERN NUMA SYSTEMSDocument26 pagesChallenges of Memory Management ON MODERN NUMA SYSTEMSLe PaNo ratings yet
- Model Paralel ProsesorDocument12 pagesModel Paralel ProsesorKompetisi UI UXNo ratings yet
- Memory System Design and CharacteristicsDocument87 pagesMemory System Design and CharacteristicsrajkumarNo ratings yet
- Overview of Parallel Computing: Shawn T. BrownDocument46 pagesOverview of Parallel Computing: Shawn T. BrownKarthik KusumaNo ratings yet
- Shared Memory Multiprocessors: Logical Design and Software InteractionsDocument107 pagesShared Memory Multiprocessors: Logical Design and Software Interactionsfariha2002No ratings yet
- Ca Unit 5 PrabuDocument37 pagesCa Unit 5 Prabu6109 Sathish Kumar JNo ratings yet
- Memory SubsytemsDocument19 pagesMemory Subsytemsaswin1990No ratings yet
- Introduction to Parallel ProgrammingDocument24 pagesIntroduction to Parallel ProgrammingMarlon TugweteNo ratings yet
- Unit VIDocument50 pagesUnit VIoptics opticsNo ratings yet
- Unit 3 OF ESDDocument22 pagesUnit 3 OF ESDTanveer ShariffNo ratings yet
- Shared Memory ArchitecturesDocument34 pagesShared Memory ArchitecturesEr Umesh ThoriyaNo ratings yet
- Types of ComputersDocument48 pagesTypes of Computersnaveed321100% (5)
- Design and Implementation of An EPROM ProgrammerDocument124 pagesDesign and Implementation of An EPROM ProgrammerChidozie Ijeomah100% (1)
- Different Types of MemoryDocument34 pagesDifferent Types of MemoryPirapuraj PonnampalamNo ratings yet
- DLCA Unit 5-MemoryorganizationDocument58 pagesDLCA Unit 5-MemoryorganizationJayendra SriNo ratings yet
- A502018463 23825 5 2019 Unit6Document36 pagesA502018463 23825 5 2019 Unit6ayush ajayNo ratings yet
- Cache&Virtual MemoryDocument50 pagesCache&Virtual Memoryeugen lupuNo ratings yet
- Learning Module 03Document27 pagesLearning Module 03Christal Jhade DiazNo ratings yet
- GTU Memory Hierarchy PresentationDocument20 pagesGTU Memory Hierarchy PresentationIsmael Ali AbdoulayeNo ratings yet
- KTMTSS Shared Memory MultiprocessorDocument29 pagesKTMTSS Shared Memory Multiprocessorquỳnh nguyễnNo ratings yet
- Memory CacheDocument18 pagesMemory CacheFunsuk VangduNo ratings yet
- Digital Electronics NotesDocument29 pagesDigital Electronics NotesHimanshu KhanduriNo ratings yet
- Chapter 2 - Computer OrganizationDocument30 pagesChapter 2 - Computer Organizationadhasbdi2e98qy928eNo ratings yet
- SIMD and Associative Models for Parallel ComputingDocument31 pagesSIMD and Associative Models for Parallel ComputingSNo ratings yet
- 5 - Designing Parallel ProgramsDocument52 pages5 - Designing Parallel ProgramsSNo ratings yet
- 4 - Parallel Programming - IntroductionDocument45 pages4 - Parallel Programming - IntroductionSNo ratings yet
- 3 VLSI Introduction 1Document54 pages3 VLSI Introduction 1SNo ratings yet
- Computer Security & Cryptography: Identification and AuthenticationDocument22 pagesComputer Security & Cryptography: Identification and AuthenticationSNo ratings yet
- Authorisation: by M.O. OdeoDocument33 pagesAuthorisation: by M.O. OdeoSNo ratings yet
- Classical Encryption Techniques ExplainedDocument39 pagesClassical Encryption Techniques ExplainedSNo ratings yet
- 1.0 Computer Security and CryptographyDocument22 pages1.0 Computer Security and CryptographySNo ratings yet
- Unit 4 Memory: Computer Organization & Architecture By: Pankaj TiwariDocument24 pagesUnit 4 Memory: Computer Organization & Architecture By: Pankaj TiwariANUJ TIWARINo ratings yet
- FPGA Project ProposalDocument6 pagesFPGA Project ProposalBilal Haider TanoliNo ratings yet
- Assignment 1-SolutionDocument4 pagesAssignment 1-SolutionAsad RehanNo ratings yet
- Rowhammer: A Retrospective: Onur Mutlu Jeremie S. Kim Eth Z Urich Carnegie Mellon UniversityDocument16 pagesRowhammer: A Retrospective: Onur Mutlu Jeremie S. Kim Eth Z Urich Carnegie Mellon UniversityMegha JoshiNo ratings yet
- DSPDocument77 pagesDSPVikas YadavNo ratings yet
- Addressing ModesDocument20 pagesAddressing ModesAkhil B SkariaNo ratings yet
- William Stallings Computer Organization and Architecture 6 EditionDocument46 pagesWilliam Stallings Computer Organization and Architecture 6 EditionSatiajatiBaskoroNo ratings yet
- At Mega 48 PaDocument23 pagesAt Mega 48 PaCesar GFerNo ratings yet
- COA SyllabusDocument1 pageCOA SyllabusSandeep JamdagniNo ratings yet
- Lecture 5B Code Generation From HLLDocument9 pagesLecture 5B Code Generation From HLLJonnahNo ratings yet
- My PC Build 2020 (Bismillah) Build v. 0.0.1 Name CPU Mobo Memory Storage GPU PSU CPU CoolerDocument2 pagesMy PC Build 2020 (Bismillah) Build v. 0.0.1 Name CPU Mobo Memory Storage GPU PSU CPU CoolerGhaffar ZharfanNo ratings yet
- Lecture 28Document15 pagesLecture 28KumarNo ratings yet
- Chapter 2introduction To The C2xx DSP Core and Code GenerationDocument4 pagesChapter 2introduction To The C2xx DSP Core and Code Generationdivya624No ratings yet
- Next:: 5.2.2 Process Discussion 5.2 Bicmos Process Technology 5.2 Bicmos Process TechnologyDocument8 pagesNext:: 5.2.2 Process Discussion 5.2 Bicmos Process Technology 5.2 Bicmos Process TechnologysirapuNo ratings yet
- Oc8051 DesignDocument34 pagesOc8051 DesignnikolicnemanjaNo ratings yet
- Dpco Unit 3,4,5 QBDocument18 pagesDpco Unit 3,4,5 QBAISWARYA MNo ratings yet
- 1nasiruddin - PPT of Ic 8288 External Bus Controller by M Nasiruddin PDFDocument15 pages1nasiruddin - PPT of Ic 8288 External Bus Controller by M Nasiruddin PDFForce XNo ratings yet
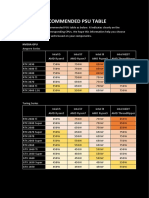
- Recommended Psu TableDocument2 pagesRecommended Psu TableFaisal Fikri HakimNo ratings yet
- President Ramon Magsaysay State University: AC221: Fundamentals of Electronic CircuitsDocument8 pagesPresident Ramon Magsaysay State University: AC221: Fundamentals of Electronic CircuitsWade DachNo ratings yet
- Gép ÖsszerakásDocument3 pagesGép ÖsszerakásPetraWardersNo ratings yet
- Cmos Inverter Layout Tutorial: Prepared By: Eng. Hazem W. MararDocument12 pagesCmos Inverter Layout Tutorial: Prepared By: Eng. Hazem W. Mararkrsrajesh1No ratings yet
- How Computer Memory Works - Ethan GabrielDocument2 pagesHow Computer Memory Works - Ethan GabrielEthan GabrielNo ratings yet
- COA-Unit 4 Memory OraganizationDocument60 pagesCOA-Unit 4 Memory Oraganizationtanuja rajputNo ratings yet
- Basic Course On 8051 MicrocontrollersDocument2 pagesBasic Course On 8051 Microcontrollerssathish37No ratings yet
- Ee3230 L3 CmosDocument61 pagesEe3230 L3 Cmos林岩徵No ratings yet
- W27C512 45Z PDFDocument20 pagesW27C512 45Z PDFAbdelkrim RamdaneNo ratings yet
- COMP 231 Microprocessor and Assembly LanguageDocument62 pagesCOMP 231 Microprocessor and Assembly LanguageAarush TimalsinaNo ratings yet