You might also like
- Consistency and Replication - PPTDocument55 pagesConsistency and Replication - PPTcyber_rla4541No ratings yet
- Consistency and Replication in Distributed SystemDocument36 pagesConsistency and Replication in Distributed SystemSunita SahuNo ratings yet
- Distributed System Answer KeyDocument50 pagesDistributed System Answer KeyNeeraj Singh91% (11)
- KTMTSS Shared Memory MultiprocessorDocument29 pagesKTMTSS Shared Memory Multiprocessorquỳnh nguyễnNo ratings yet
- Cache Coherence in Bus-Based Shared Memory MultiprocessorsDocument37 pagesCache Coherence in Bus-Based Shared Memory Multiprocessorsmadhu75No ratings yet
- Shared Memory Multiprocessors: Logical Design and Software InteractionsDocument107 pagesShared Memory Multiprocessors: Logical Design and Software Interactionsfariha2002No ratings yet
- Cache Coherence: CSE 661 - Parallel and Vector ArchitecturesDocument37 pagesCache Coherence: CSE 661 - Parallel and Vector ArchitecturesZia AtiqNo ratings yet
- Chapter 5 - Shared Memory MultiprocessorDocument96 pagesChapter 5 - Shared Memory Multiprocessorquỳnh nguyễnNo ratings yet
- Shared Memory MultiprocessorsDocument45 pagesShared Memory MultiprocessorsSushma Rani VatekarNo ratings yet
- Module 4Document40 pagesModule 4Tharushi DewminiNo ratings yet
- Directory-Based Cache Coherence: Parallel Computer Architecture and Programming CMU 15-418/15-618, Spring 2019Document56 pagesDirectory-Based Cache Coherence: Parallel Computer Architecture and Programming CMU 15-418/15-618, Spring 2019YAAKOV SOLOMONNo ratings yet
- Multi-Core Programming - Increasing Performance Through Software Multi-ThreadingDocument11 pagesMulti-Core Programming - Increasing Performance Through Software Multi-ThreadingKarthikNo ratings yet
- Computer Architecture: Multiprocessors Shared Memory Architectures Prof. Jerry Breecher CSCI 240 Fall 2003Document24 pagesComputer Architecture: Multiprocessors Shared Memory Architectures Prof. Jerry Breecher CSCI 240 Fall 2003nighat_princesNo ratings yet
- Inf3380 para HW 2014Document28 pagesInf3380 para HW 2014Dejan VujičićNo ratings yet
- Multiprocessors: Cs 152 L1 5 .1 DAP Fa97, U.CBDocument38 pagesMultiprocessors: Cs 152 L1 5 .1 DAP Fa97, U.CBIsaacMedeirosNo ratings yet
- High Performance Networking. Low Latency Devices. 'Network Fabric'Document40 pagesHigh Performance Networking. Low Latency Devices. 'Network Fabric'Jason WongNo ratings yet
- 2017 Summer Camp Day4 Part1Document34 pages2017 Summer Camp Day4 Part1gusatNo ratings yet
- Parallel Computer Models: CEG 4131 Computer Architecture III Miodrag BolicDocument27 pagesParallel Computer Models: CEG 4131 Computer Architecture III Miodrag BolicShylaja BNo ratings yet
- Embedded System Module 3 Part 2Document60 pagesEmbedded System Module 3 Part 2Harish G CNo ratings yet
- A Ferroelectric FET-Based Processing-In-Memory ArcDocument8 pagesA Ferroelectric FET-Based Processing-In-Memory ArcFlavia Monica RodriguesNo ratings yet
- Agarwal Et Al. - The MIT Alewife MachineDocument12 pagesAgarwal Et Al. - The MIT Alewife MachineFuzzy KNo ratings yet
- Lect10 SMPCCDocument27 pagesLect10 SMPCCbassam abutraabNo ratings yet
- Disclaimer: - in Preparation of These Slides, Materials Have Been Taken FromDocument33 pagesDisclaimer: - in Preparation of These Slides, Materials Have Been Taken FromZara ShabirNo ratings yet
- Cache Coherence Dubois Briggs 1982Document10 pagesCache Coherence Dubois Briggs 1982The Observation Inc.No ratings yet
- 2 - Parallel Computer Architecture - 1Document26 pages2 - Parallel Computer Architecture - 1SNo ratings yet
- 0014 SharedMemoryArchitectureDocument31 pages0014 SharedMemoryArchitectureAsif KhanNo ratings yet
- CS 294-73 Software Engineering For Scientific Computing Lecture 14: Performance On Cache-Based Systems, Profiling & Tips For C++Document34 pagesCS 294-73 Software Engineering For Scientific Computing Lecture 14: Performance On Cache-Based Systems, Profiling & Tips For C++Edmund ZinNo ratings yet
- Overview of Parallel Computing: Shawn T. BrownDocument46 pagesOverview of Parallel Computing: Shawn T. BrownKarthik KusumaNo ratings yet
- Multiprocessor: Vikram Singh SlathiaDocument48 pagesMultiprocessor: Vikram Singh SlathiaShivani SharmaNo ratings yet
- 21 - Virtualmemory2 - WIDEDocument36 pages21 - Virtualmemory2 - WIDEChirag SoodNo ratings yet
- 14 NVMDocument46 pages14 NVMmaykelnawarNo ratings yet
- A Survey of Cache Coherence Mechanisms in Shared MDocument27 pagesA Survey of Cache Coherence Mechanisms in Shared Msahasubhajit32102No ratings yet
- L7 Multicore 1Document50 pagesL7 Multicore 1AsHraf G. ElrawEiNo ratings yet
- Ebpf Hardware Offload To Smartnics: Cls BPF and XDP: KeywordsDocument6 pagesEbpf Hardware Offload To Smartnics: Cls BPF and XDP: KeywordsHIPPO LDNo ratings yet
- CH05 COA10e 2 01122021 022920pmDocument6 pagesCH05 COA10e 2 01122021 022920pmAhmed AyazNo ratings yet
- Cis620 15 00Document36 pagesCis620 15 00Heval TariQNo ratings yet
- Unit 5 (Slides)Document75 pagesUnit 5 (Slides)Keerthana g.krishnanNo ratings yet
- Convergence of Parallel Architectures: CS 258, Spring 99 David E. Culler Computer Science Division U.C. BerkeleyDocument25 pagesConvergence of Parallel Architectures: CS 258, Spring 99 David E. Culler Computer Science Division U.C. BerkeleyMurali SrinivasaiahNo ratings yet
- Why Choose A Multiprocessor?Document17 pagesWhy Choose A Multiprocessor?M Ijaz ChohanNo ratings yet
- BRKMPL-2333 2014 San FranciscoDocument64 pagesBRKMPL-2333 2014 San FranciscoJames SmithNo ratings yet
- CA Classes-246-250Document5 pagesCA Classes-246-250SrinivasaRaoNo ratings yet
- Model Paralel ProsesorDocument12 pagesModel Paralel ProsesorKompetisi UI UXNo ratings yet
- Lecture 19Document20 pagesLecture 19api-3801184No ratings yet
- Demystifying Multicore Germany 14 PDFDocument82 pagesDemystifying Multicore Germany 14 PDFJacob CeronNo ratings yet
- Distributed Memory ArchitectureDocument48 pagesDistributed Memory Architecturesanzog raiNo ratings yet
- Lecture 1 Parallel DatabasesDocument30 pagesLecture 1 Parallel DatabasesKumkumo Kussia KossaNo ratings yet
- Memory CacheDocument18 pagesMemory CacheFunsuk VangduNo ratings yet
- Parallel ArchitectureDocument33 pagesParallel ArchitectureDebarshi MajumderNo ratings yet
- Hyper Threading: Concepts & ArchitectureDocument28 pagesHyper Threading: Concepts & Architecturezainvi.sf6018No ratings yet
- Lecture 7 Memory 2021Document64 pagesLecture 7 Memory 2021KANZA AKRAMNo ratings yet
- 1.interprocess Communication Mechanisms 2.memory Management and Virtual MemoryDocument45 pages1.interprocess Communication Mechanisms 2.memory Management and Virtual MemorySri VardhanNo ratings yet
- Cache Coherence and Synchronization - TutorialspointDocument7 pagesCache Coherence and Synchronization - TutorialspointTejender Kumar SachwalNo ratings yet
- Ec6009 Advanced Computer Architecture Unit Iv: Thread Level ParallelismDocument17 pagesEc6009 Advanced Computer Architecture Unit Iv: Thread Level ParallelismAnitha DenisNo ratings yet
- cs668 Lec1 ParallelArchDocument18 pagescs668 Lec1 ParallelArchIshAureaNo ratings yet
- CSCE 613: Interlude: Distributed Shared MemoryDocument21 pagesCSCE 613: Interlude: Distributed Shared MemoryacercNo ratings yet
- AmoebaDocument22 pagesAmoebaShashankSNNo ratings yet
- AOS - Theory - Multi-Processor & Distributed UNIX Operating Systems - IDocument13 pagesAOS - Theory - Multi-Processor & Distributed UNIX Operating Systems - ISujith Ur FrndNo ratings yet
- Unit-5 Part1Document85 pagesUnit-5 Part1himateja mygopulaNo ratings yet
- Multiprocessor Systems: - Tightly Coupled vs. Loosely Coupled SystemsDocument14 pagesMultiprocessor Systems: - Tightly Coupled vs. Loosely Coupled SystemsAmet koko TaroNo ratings yet
- Parallel Processors and Cluster Systems: Gagan Bansal IME SahibabadDocument15 pagesParallel Processors and Cluster Systems: Gagan Bansal IME SahibabadGagan BansalNo ratings yet
- Computer ArchitectureDocument12 pagesComputer Architecturejaibirthakran47No ratings yet
- Multicore Software Development Techniques: Applications, Tips, and TricksFrom EverandMulticore Software Development Techniques: Applications, Tips, and TricksRating: 2.5 out of 5 stars2.5/5 (2)
- Institute Level Files VerificationDocument1 pageInstitute Level Files Verificationvadla77No ratings yet
- Improvement Test Question BankDocument1 pageImprovement Test Question Bankvadla77No ratings yet
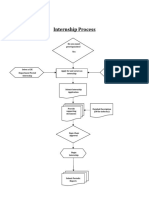
- Internship Process FlowchartDocument2 pagesInternship Process Flowchartvadla77No ratings yet
- Assignment Analog Electronic CircuitsDocument1 pageAssignment Analog Electronic Circuitsvadla77No ratings yet
- Date:25-06-2021 SL.N O Criteria Comments: The DepartmentDocument4 pagesDate:25-06-2021 SL.N O Criteria Comments: The Departmentvadla77No ratings yet
- IOT Assignment 2021-22Document1 pageIOT Assignment 2021-22vadla77No ratings yet
- Internship Process FlowchartDocument2 pagesInternship Process Flowchartvadla77No ratings yet
- 5-Course OutcomesDocument1 page5-Course Outcomesvadla77No ratings yet
- CO-PO Mapping: Co-Po Mapping CO1 CO2 CO3 CO4 Averag e Justification With Respect To Co-Po MappingDocument2 pagesCO-PO Mapping: Co-Po Mapping CO1 CO2 CO3 CO4 Averag e Justification With Respect To Co-Po Mappingvadla77No ratings yet
- Ecsyll 2018 Schmeme 7&8 SemDocument42 pagesEcsyll 2018 Schmeme 7&8 Semvadla77No ratings yet
- CO-PO Mapping: Co-Po Mapping CO1 CO2 CO3 CO4 Averag e Justification With Respect To Co-Po MappingDocument2 pagesCO-PO Mapping: Co-Po Mapping CO1 CO2 CO3 CO4 Averag e Justification With Respect To Co-Po Mappingvadla77No ratings yet
- IOT-Internet of Things Question Bank Module 1Document3 pagesIOT-Internet of Things Question Bank Module 1vadla77No ratings yet
- Analog and Digital Electronics Lab Manual (17CSL37) : Department of Computer Science and EngineeringDocument61 pagesAnalog and Digital Electronics Lab Manual (17CSL37) : Department of Computer Science and Engineeringvadla77No ratings yet
- Anti Diabetic Ayurvedic Fruit Noni IJERTCONV9IS12042Document3 pagesAnti Diabetic Ayurvedic Fruit Noni IJERTCONV9IS12042vadla77No ratings yet
- Csis 3 SyllDocument26 pagesCsis 3 SyllmanjulakinnalNo ratings yet
- Chap 3Lesson21EmsysNewDocument9 pagesChap 3Lesson21EmsysNewvadla77No ratings yet
- Brief History of The X86 Family:: Evolution From 8080/8085 To 8086Document15 pagesBrief History of The X86 Family:: Evolution From 8080/8085 To 8086vadla77No ratings yet
- Chap 2Lesson09EmsysNewDocument22 pagesChap 2Lesson09EmsysNewPhúc Vũ Viết PhúcNo ratings yet
- VTU PH D Regulation2015Document26 pagesVTU PH D Regulation2015Ring MasterNo ratings yet
- Wireless Sensor Network Survey PDFDocument30 pagesWireless Sensor Network Survey PDFbimalNo ratings yet
- Evaluation Guidelines Tier II v0Document26 pagesEvaluation Guidelines Tier II v0vadla77No ratings yet
- CsDocument13 pagesCskrishnagdeshpandeNo ratings yet
- BCS 413 - Lecture5 - Replication - ConsistencyDocument25 pagesBCS 413 - Lecture5 - Replication - ConsistencyDesmond KampoeNo ratings yet
- Microservices Niram PDFDocument6 pagesMicroservices Niram PDFnniram sugriyaaaNo ratings yet
- Module-3 ACADocument50 pagesModule-3 ACA1HK16CS104 Muntazir Hussain BhatNo ratings yet
- Sequential ConsistencyDocument3 pagesSequential ConsistencyDiana PopaNo ratings yet
- Module 3 ACA NotesDocument50 pagesModule 3 ACA NotesShylajaNo ratings yet
- Qn:Explain Different Latency Hiding Techniques /mechanisms? (Ans:Describe Sections 6.1.2,6.1.3, 6.1.5, 6.2.2.)Document28 pagesQn:Explain Different Latency Hiding Techniques /mechanisms? (Ans:Describe Sections 6.1.2,6.1.3, 6.1.5, 6.2.2.)ripcord jakeNo ratings yet
- Distributed Systems 2 Mark Question & AnswersDocument16 pagesDistributed Systems 2 Mark Question & AnswersDr. PADMANABAN KNo ratings yet
- Memory Consistency ModelDocument17 pagesMemory Consistency ModelMuthuselviNo ratings yet
- Parallel ComputingDocument12 pagesParallel ComputingSaravanan Thangavelu100% (1)
- DS Consistancy and Replication (Mod 7)Document13 pagesDS Consistancy and Replication (Mod 7)Hi thereNo ratings yet
- CAQA5e ch5Document31 pagesCAQA5e ch5Harshit MogalapalliNo ratings yet
- MC0085 MQPDocument20 pagesMC0085 MQPUtpal KantNo ratings yet
- Consistency As A Service: Trading Consistency For AvailabilityDocument4 pagesConsistency As A Service: Trading Consistency For AvailabilityPratik MahajanNo ratings yet
- Chapter 7 ReplicationDocument26 pagesChapter 7 ReplicationHarpinder KaurNo ratings yet
- TY BTech IT Structure and Syllabus 2022-23Document140 pagesTY BTech IT Structure and Syllabus 2022-23yghjhNo ratings yet
- Consistency Model PDFDocument4 pagesConsistency Model PDFGoogle GurungNo ratings yet
- GPU Verification Iccad18-GpuDocument8 pagesGPU Verification Iccad18-GpuRNo ratings yet
- Question BankDocument10 pagesQuestion BankgurugovanNo ratings yet
- Distributed Shared MemoryDocument24 pagesDistributed Shared MemorySudha PatelNo ratings yet
- DSM AdvantagesDocument5 pagesDSM AdvantagesMuthuselviNo ratings yet
- Memory Consistency Models: David MosbergerDocument11 pagesMemory Consistency Models: David MosbergerDong ShinNo ratings yet
- Chapter-6 Consistency and ReplicationDocument67 pagesChapter-6 Consistency and ReplicationGUTAMA KUSSE GELEGLONo ratings yet
- Admas University School of Postgraduate Studies Course OutlineDocument3 pagesAdmas University School of Postgraduate Studies Course Outlinehak advNo ratings yet
- Assignment 4solutionDocument5 pagesAssignment 4solutionSherin zafarNo ratings yet
- Distributed Shared MemoryDocument30 pagesDistributed Shared Memorymani_madhukar3654No ratings yet
- Numa MultiprocessorsDocument26 pagesNuma MultiprocessorsVADAPALLY PRAVEEN KUMARNo ratings yet
- Chapter 7-Consistency and ReplicationDocument78 pagesChapter 7-Consistency and ReplicationGebreigziabher M. AbNo ratings yet