You might also like
- SA Lecture 3 Requirement Determination II - Use CaseDocument54 pagesSA Lecture 3 Requirement Determination II - Use CaseSondos SaidNo ratings yet
- Chapter Three: The Analysis Phase: Werabe University Institute of Technology Department of Information SystemsDocument64 pagesChapter Three: The Analysis Phase: Werabe University Institute of Technology Department of Information SystemsAli HussenNo ratings yet
- Phase 2: Systems AnalysisDocument15 pagesPhase 2: Systems AnalysisSamuel AssefaNo ratings yet
- AACS1304 03 - System Analysis 202005Document125 pagesAACS1304 03 - System Analysis 202005WIN YE KUANNo ratings yet
- Systems Analysis and Design: Determining Software RequirementsDocument51 pagesSystems Analysis and Design: Determining Software RequirementsNgọc TrâmNo ratings yet
- Chapter 3Document33 pagesChapter 3zaaak ditteNo ratings yet
- Lec 7Document32 pagesLec 7ranaumair1326No ratings yet
- System Analysis & Design: Lecture-4 Information GatheringDocument10 pagesSystem Analysis & Design: Lecture-4 Information GatheringNadim HasanNo ratings yet
- PDF Document (3) 2Document34 pagesPDF Document (3) 2WEI SZI LIMNo ratings yet
- CHAPTER 15 System Life CycleDocument3 pagesCHAPTER 15 System Life CycleMatthew GunawanNo ratings yet
- DDE Mod 5Document22 pagesDDE Mod 5Ricky NeminoNo ratings yet
- System RequirementsDocument15 pagesSystem RequirementsRoxas TanNo ratings yet
- Data GatheringDocument29 pagesData GatheringJenny Sison-Wilson67% (18)
- Chapter ThreeDocument106 pagesChapter ThreeSuraphel BirhaneNo ratings yet
- Chapter ThreeDocument106 pagesChapter ThreeSuraphel BirhaneNo ratings yet
- 3.requirement Gathering and Fact Finding TechniqesDocument21 pages3.requirement Gathering and Fact Finding TechniqesGeethma RamanayakaNo ratings yet
- Surv-Lecture 2Document15 pagesSurv-Lecture 2Doaa RezkNo ratings yet
- Fact Finding TechniquesDocument56 pagesFact Finding TechniqueswalllacNo ratings yet
- Chapter Three - Requirements ElicitationDocument36 pagesChapter Three - Requirements ElicitationBeza GalNo ratings yet
- Chapter Two: Requirements ModelingDocument28 pagesChapter Two: Requirements Modelingjurihu143No ratings yet
- I. Sampling and Investigating Hard DataDocument16 pagesI. Sampling and Investigating Hard DataCristy Balubayan NazarenoNo ratings yet
- System Analysis & Design: Dr. Md. Rakibul Hoque University of DhakaDocument74 pagesSystem Analysis & Design: Dr. Md. Rakibul Hoque University of DhakaNusrat Jahan NafisaNo ratings yet
- Chapter02 - Part 1Document39 pagesChapter02 - Part 1Trần Thị Minh XuânNo ratings yet
- Microsoft PowerPoint - 8. Fact Finding TechniquesDocument17 pagesMicrosoft PowerPoint - 8. Fact Finding TechniquesFăÍż SăįYąð0% (1)
- SAD Approaches To DesignDocument25 pagesSAD Approaches To Designkolakim75No ratings yet
- Technology PDF f4Document6 pagesTechnology PDF f4Bashir Cumar CaliNo ratings yet
- CH 3A System AnalysisDocument64 pagesCH 3A System AnalysisAbraham DamtewNo ratings yet
- Introduction To Business Systems AnalysisDocument11 pagesIntroduction To Business Systems AnalysisMahdi GhulamiNo ratings yet
- Question Topics: Logical ModelDocument37 pagesQuestion Topics: Logical ModelJonnel SamaniegoNo ratings yet
- HW 20220Document59 pagesHW 20220mayank barsenaNo ratings yet
- Laporan Tugas Perkuliahan Analisis Dan Perancangan Sistem (22176033)Document15 pagesLaporan Tugas Perkuliahan Analisis Dan Perancangan Sistem (22176033)Rohmatul HasanahNo ratings yet
- Fact Finding TechDocument23 pagesFact Finding Techapi-3706009100% (1)
- Systems Analysis and Design Chapter-4: Part - IDocument9 pagesSystems Analysis and Design Chapter-4: Part - INATI NTNo ratings yet
- Sad Chapter 3Document14 pagesSad Chapter 3mickyaszenebeNo ratings yet
- SAD - Unit 2 - Ver1Document27 pagesSAD - Unit 2 - Ver1قدس العجميNo ratings yet
- L#7-8 - Reqs ElicitationDocument30 pagesL#7-8 - Reqs Elicitation221090No ratings yet
- Chapter ThreeDocument29 pagesChapter Threedemeketeme2013No ratings yet
- Basic Software Engineering: Prof. Vijya Tulsani, Assistant ProfessorDocument28 pagesBasic Software Engineering: Prof. Vijya Tulsani, Assistant ProfessorKuldeep ParekhNo ratings yet
- Chapter 4Document30 pagesChapter 4OngHongTeckNo ratings yet
- Assignment of System Analysis and Design Bally Kelly YvanDocument4 pagesAssignment of System Analysis and Design Bally Kelly Yvankelly kim ndayishimiyeNo ratings yet
- Homework Chapter 6 - CS240Document7 pagesHomework Chapter 6 - CS240Angela PintoNo ratings yet
- Chapter 3. Requirements DeterminationDocument12 pagesChapter 3. Requirements DeterminationEugine CasañadaNo ratings yet
- Chapter 05 System AnalysisDocument111 pagesChapter 05 System Analysisfennie lohNo ratings yet
- System Analysis Assignment 1Document11 pagesSystem Analysis Assignment 1Genat HusenNo ratings yet
- Systems Planning and Initial Investigation: Sampling of Existing Documentation, Forms, and FilesDocument7 pagesSystems Planning and Initial Investigation: Sampling of Existing Documentation, Forms, and Filesसुरज पौडेलNo ratings yet
- AIS 4 ANALYSIS PHASE Topic 1Document41 pagesAIS 4 ANALYSIS PHASE Topic 1Razmen Ramirez PintoNo ratings yet
- AIS 4 ANALYSIS PHASE Topic 1 PDFDocument41 pagesAIS 4 ANALYSIS PHASE Topic 1 PDFRazmen Ramirez PintoNo ratings yet
- Fact Finding TechniquesDocument28 pagesFact Finding TechniquesCathy Love MoneroNo ratings yet
- Part 3 - Fact Finding TechniquesDocument49 pagesPart 3 - Fact Finding TechniquesNUR SHAFIAH SOLEHAH ZAIRUL HISHAMNo ratings yet
- Systen Analysis and Designhandout StuDocument16 pagesSysten Analysis and Designhandout StuGraham FulaburiNo ratings yet
- Chapter 3 - System AnalysisDocument81 pagesChapter 3 - System AnalysisShaluNo ratings yet
- Data Collection and Analysis - Fact Finding - Requirements CaptureDocument42 pagesData Collection and Analysis - Fact Finding - Requirements Capturealobi11No ratings yet
- Lec2 - Rqments Gatering 0KDocument28 pagesLec2 - Rqments Gatering 0Krachelortiz510No ratings yet
- Hris 3Document20 pagesHris 3nidaNo ratings yet
- Systems AnalysisDocument13 pagesSystems AnalysisMushawatuNo ratings yet
- Assignment 1 Dumisani Mavenyengwa r184880zDocument11 pagesAssignment 1 Dumisani Mavenyengwa r184880zDumisani MavenyengwaNo ratings yet
- The Dakaz Computer Studies 12Document47 pagesThe Dakaz Computer Studies 12Musenge LuwishaNo ratings yet
- Chap 04Document6 pagesChap 04Kok Siew MingNo ratings yet
- IT 221 - Lecture 3Document31 pagesIT 221 - Lecture 3Amoasi D' OxygenNo ratings yet
- Chapter Four: System DesignDocument62 pagesChapter Four: System DesignG Gጂጂ TubeNo ratings yet
- Chapter Four: System DesignDocument62 pagesChapter Four: System DesignG Gጂጂ TubeNo ratings yet
- Chapter FiveDocument30 pagesChapter FiveG Gጂጂ TubeNo ratings yet
- Chapter Two: Systems Development Life CycleDocument45 pagesChapter Two: Systems Development Life CycleG Gጂጂ TubeNo ratings yet
- Chapter One: Introduction To Structural SADDocument48 pagesChapter One: Introduction To Structural SADG Gጂጂ TubeNo ratings yet
- Chapter Two: Systems Development Life CycleDocument45 pagesChapter Two: Systems Development Life CycleG Gጂጂ TubeNo ratings yet
- Chapter One: Introduction To Structural SADDocument48 pagesChapter One: Introduction To Structural SADG Gጂጂ TubeNo ratings yet
- Chapter 2 Method of Data Collection andDocument59 pagesChapter 2 Method of Data Collection andG Gጂጂ TubeNo ratings yet
- Chapter Three: Requirement AnalysisDocument102 pagesChapter Three: Requirement AnalysisG Gጂጂ TubeNo ratings yet
- Chapter FiveDocument30 pagesChapter FiveG Gጂጂ TubeNo ratings yet
- Chapter 4 Introduction To ProbabilityDocument68 pagesChapter 4 Introduction To ProbabilityG Gጂጂ TubeNo ratings yet
- Chapter 3 Descriptive StatisticsDocument78 pagesChapter 3 Descriptive StatisticsG Gጂጂ TubeNo ratings yet
- Inferential StatisticsDocument119 pagesInferential StatisticsG Gጂጂ TubeNo ratings yet
- Chapter 1 IntroductionDocument388 pagesChapter 1 IntroductionG Gጂጂ TubeNo ratings yet
- Inferential StatisticsDocument119 pagesInferential StatisticsG Gጂጂ TubeNo ratings yet
- Chapter 3 Descriptive StatisticsDocument78 pagesChapter 3 Descriptive StatisticsG Gጂጂ TubeNo ratings yet
- Chapter 3 Descriptive StatisticsDocument78 pagesChapter 3 Descriptive StatisticsG Gጂጂ TubeNo ratings yet
- Inferential StatisticsDocument119 pagesInferential StatisticsG Gጂጂ TubeNo ratings yet
- Chapter 4 Introduction To ProbabilityDocument68 pagesChapter 4 Introduction To ProbabilityG Gጂጂ TubeNo ratings yet
- Chapter 1 IntroductionDocument388 pagesChapter 1 IntroductionG Gጂጂ TubeNo ratings yet
- Chapter 2 Method of Data Collection andDocument59 pagesChapter 2 Method of Data Collection andG Gጂጂ TubeNo ratings yet
- Chapter 4 Introduction To ProbabilityDocument68 pagesChapter 4 Introduction To ProbabilityG Gጂጂ TubeNo ratings yet
- Chapter 4 Introduction To ProbabilityDocument68 pagesChapter 4 Introduction To ProbabilityG Gጂጂ TubeNo ratings yet
- Chapter 2 Method of Data Collection andDocument59 pagesChapter 2 Method of Data Collection andG Gጂጂ TubeNo ratings yet
- Chapter 1 IntroductionDocument388 pagesChapter 1 IntroductionG Gጂጂ TubeNo ratings yet
- Inferential StatisticsDocument119 pagesInferential StatisticsG Gጂጂ TubeNo ratings yet
- Chapter 2 Method of Data Collection andDocument59 pagesChapter 2 Method of Data Collection andG Gጂጂ TubeNo ratings yet
- Chapter 3 Descriptive StatisticsDocument78 pagesChapter 3 Descriptive StatisticsG Gጂጂ TubeNo ratings yet
- Chapter 1 IntroductionDocument388 pagesChapter 1 IntroductionG Gጂጂ TubeNo ratings yet
- Excel Black Belt (Answers)Document54 pagesExcel Black Belt (Answers)21Y6C41 SHARMAINE SEET SHIENNo ratings yet
- Canada CC TopupDocument22 pagesCanada CC TopupFree RobuxNo ratings yet
- Advance Mathematical Physics Lab Students Name: NARESH KUMAWAT (1907061) RAJAT KUMAR (1907062) ANIL KUMAR (1907060)Document4 pagesAdvance Mathematical Physics Lab Students Name: NARESH KUMAWAT (1907061) RAJAT KUMAR (1907062) ANIL KUMAR (1907060)Shashank KNo ratings yet
- SRT AI Community Platform - Hyperwallet PaymentsDocument6 pagesSRT AI Community Platform - Hyperwallet PaymentsNilesh MishraNo ratings yet
- Umwd 06516 0DHDocument3 pagesUmwd 06516 0DHИван ФиличевNo ratings yet
- Document From Sfere Electric23 AbcDocument29 pagesDocument From Sfere Electric23 AbcMuhammad SaleemNo ratings yet
- Vinayak Pujari Research Paper On Biometrics SecurityDocument7 pagesVinayak Pujari Research Paper On Biometrics Securityjessy jamesNo ratings yet
- MYSWEETY GRBL Offline ControllerDocument7 pagesMYSWEETY GRBL Offline ControllerJuan José Bagur ColominasNo ratings yet
- Trends, Networks, and Critical Thinking in The 21st Century: Quarter 4 - Module 2Document14 pagesTrends, Networks, and Critical Thinking in The 21st Century: Quarter 4 - Module 2Jea Caderao Alapan100% (2)
- Delcam - PowerMILL 2014 R1 Whats New EN - 2013Document137 pagesDelcam - PowerMILL 2014 R1 Whats New EN - 2013phạm minh hùngNo ratings yet
- Planning Techiniques, Tools and ApplicationsDocument56 pagesPlanning Techiniques, Tools and ApplicationsSharlyn Marie N. BadilloNo ratings yet
- Dear Mr. PinkDocument7 pagesDear Mr. PinkK59 Nguyễn Tiến DũngNo ratings yet
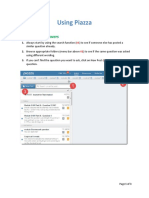
- Using Piazza: I. Looking For AnswersDocument3 pagesUsing Piazza: I. Looking For Answersnmra abidNo ratings yet
- Implementing Control Flow in An SSIS PackageDocument35 pagesImplementing Control Flow in An SSIS PackageRichie PooNo ratings yet
- Introduction To MultimediaDocument217 pagesIntroduction To MultimediaMajestyNo ratings yet
- TYBCA Cyber Security Notes 1Document99 pagesTYBCA Cyber Security Notes 1pradneshshinde29No ratings yet
- Flutek Swing MotorDocument2 pagesFlutek Swing Motorsunil0081No ratings yet
- MC14043B, MC14044B Cmos Msi: Quad R S LatchesDocument7 pagesMC14043B, MC14044B Cmos Msi: Quad R S LatchespaulpuscasuNo ratings yet
- Anypoint Platform Development: Fundamentals (Mule 4) Setup RequirementsDocument3 pagesAnypoint Platform Development: Fundamentals (Mule 4) Setup RequirementsKakz KarthikNo ratings yet
- Guidelines of PBL - MBA (22-24) Sem IIDocument8 pagesGuidelines of PBL - MBA (22-24) Sem IIShivnath KarmakarNo ratings yet
- HP AlmDocument13 pagesHP AlmvasundharaNo ratings yet
- Manual Operacion y Mtto Tele GTH-1056 1278145BDocument153 pagesManual Operacion y Mtto Tele GTH-1056 1278145BOscar GomezNo ratings yet
- How To Organize Your Work Home and Life2 PDFDocument73 pagesHow To Organize Your Work Home and Life2 PDFAnonymous Dr2nIMW9wNo ratings yet
- WebSphere Portal Family Wiki - Database Configuration For WebSphere Portal - Steps To Configure WebSphere Portal 6.1Document7 pagesWebSphere Portal Family Wiki - Database Configuration For WebSphere Portal - Steps To Configure WebSphere Portal 6.1Parameshwara RaoNo ratings yet
- Activity in Module 17Document2 pagesActivity in Module 17Minnie WagsinganNo ratings yet
- 17.1.7 Lab - Exploring DNS Traffic - ILMDocument9 pages17.1.7 Lab - Exploring DNS Traffic - ILMqashlelo2No ratings yet
- C++ Programking Lab 01 and 02 Check - SheetDocument4 pagesC++ Programking Lab 01 and 02 Check - SheetDesny LêNo ratings yet
- Band Pass Filter - Passive RC Filter TutorialDocument10 pagesBand Pass Filter - Passive RC Filter TutorialGabor VatoNo ratings yet
- Unit I Linear Data Structures - ListDocument54 pagesUnit I Linear Data Structures - Listkashokcse16No ratings yet
- Computer-3 1st QuarterDocument5 pagesComputer-3 1st QuarterEdmar John SajoNo ratings yet