You might also like
- Methods of Molecular Quantum Mechanics: An Introduction to Electronic Molecular StructureFrom EverandMethods of Molecular Quantum Mechanics: An Introduction to Electronic Molecular StructureNo ratings yet
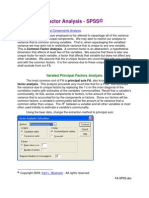
- Factor Analysis - SpssDocument15 pagesFactor Analysis - Spssmanjunatha tNo ratings yet
- Factor Analysis With SPSSDocument10 pagesFactor Analysis With SPSSsatya_buntyNo ratings yet
- Financial Benefits Postal EmployeesDocument5 pagesFinancial Benefits Postal EmployeesGhaneshwer JharbadeNo ratings yet
- Financial Benefits Postal EmployeesDocument5 pagesFinancial Benefits Postal EmployeesGhaneshwer JharbadeNo ratings yet
- Satisfaction On Other Benefits Courier EmployeesDocument6 pagesSatisfaction On Other Benefits Courier EmployeesGhaneshwer JharbadeNo ratings yet
- Factor Analysis: Output SpssDocument18 pagesFactor Analysis: Output SpssElmaNo ratings yet
- Empirical Study DataDocument2 pagesEmpirical Study DataHadi Moheb-AlizadehNo ratings yet
- Factor Analysis OutputDocument5 pagesFactor Analysis OutputAshish RamtekeNo ratings yet
- KabeerDocument8 pagesKabeerDr. Deepak ZataleNo ratings yet
- 21AA17 Eng Team LevelDocument3 pages21AA17 Eng Team LevelMaharajanNo ratings yet
- Lab Report 3Document15 pagesLab Report 3aidoo3045No ratings yet
- SEL-787 Pickup and Slope Test Calculations For AG2011-09Document17 pagesSEL-787 Pickup and Slope Test Calculations For AG2011-09jigyeshNo ratings yet
- Hasil PretestDocument17 pagesHasil PretestAris RiyantoNo ratings yet
- PHÂN TÍCH NHÂN TỐ KHÁM PHÁ EFADocument4 pagesPHÂN TÍCH NHÂN TỐ KHÁM PHÁ EFATrân Phạm Ngọc HuyềnNo ratings yet
- Analysis of Primary DataDocument20 pagesAnalysis of Primary Dataashok jaipalNo ratings yet
- Small Scale Dosimetry: Beta Emitters (SS-) : Manuel Bardiès, INSERM UMR 892, Nantes, France Manuel - Bardies@Document39 pagesSmall Scale Dosimetry: Beta Emitters (SS-) : Manuel Bardiès, INSERM UMR 892, Nantes, France Manuel - Bardies@Madalina-Elena CostacheNo ratings yet
- Factor Analysis: Faktor AnalisisDocument9 pagesFactor Analysis: Faktor AnalisisDhenayu Tresnadya HendrikNo ratings yet
- Kaiser-Meyer-Olkin (KMO)Document5 pagesKaiser-Meyer-Olkin (KMO)fizza amjadNo ratings yet
- SEL-787 Pickup and Slope Test Calculations For AG2011-09Document17 pagesSEL-787 Pickup and Slope Test Calculations For AG2011-09marceloleon4100% (1)
- KMO and Bartlett's TestDocument9 pagesKMO and Bartlett's TestMaria ShoukatNo ratings yet
- 10 - Chapter 6Document24 pages10 - Chapter 6Ziad Lutfi AlTahaynehNo ratings yet
- Financial Benefits Postal EmployeesasDocument5 pagesFinancial Benefits Postal EmployeesasGhaneshwer JharbadeNo ratings yet
- Motor Health Monitoring Using 869Document30 pagesMotor Health Monitoring Using 869tougherghi faroukNo ratings yet
- ANALISIS FAKTOR DARI DATA MENTAH RAMA-dikonversiDocument3 pagesANALISIS FAKTOR DARI DATA MENTAH RAMA-dikonversiMuhammad Ramadhan As'arryNo ratings yet
- Total Variance ExplainedDocument9 pagesTotal Variance ExplainedVân Anh Phan BùiNo ratings yet
- KMO and Bartlett's TestDocument4 pagesKMO and Bartlett's Testpoppi marinaNo ratings yet
- CHM510 Exp 3Document8 pagesCHM510 Exp 3NURANISAH NADIAH MOHD NIZAMNo ratings yet
- Other Benefits Postal EmployeesDocument5 pagesOther Benefits Postal EmployeesGhaneshwer JharbadeNo ratings yet
- SPSSDocument4 pagesSPSSPutri RahmadaniNo ratings yet
- PK# RT Hit Compound Name Match R.Match CAS LibraryDocument11 pagesPK# RT Hit Compound Name Match R.Match CAS LibraryGerson JoelNo ratings yet
- Scale: All Variables: Case Processing SummaryDocument2 pagesScale: All Variables: Case Processing SummaryreyadalamNo ratings yet
- Lecture 17Document7 pagesLecture 17minimailNo ratings yet
- Presentation For PresDocument11 pagesPresentation For PresMaverick P.No ratings yet
- Simple Procedures For Quantification and Reuse of Common Organic Solvent MixturesDocument6 pagesSimple Procedures For Quantification and Reuse of Common Organic Solvent MixturesJonathanNo ratings yet
- Cappadocia 2017Document30 pagesCappadocia 2017Rigol GradnjaNo ratings yet
- Chapter 5: Factor Analysis: 5.1 KMO & Bartlett's TestDocument7 pagesChapter 5: Factor Analysis: 5.1 KMO & Bartlett's TestRayhan TanvirNo ratings yet
- RM Multiqual Lote 45720 Ciclo Abril 2016Document351 pagesRM Multiqual Lote 45720 Ciclo Abril 2016Charles DavisNo ratings yet
- kết quả chạy spss nckhDocument21 pageskết quả chạy spss nckhPHU LE GIANo ratings yet
- Kleen Diesel - IntroductionDocument20 pagesKleen Diesel - IntroductionAhmad Imran100% (1)
- Torsional Vibration Spread SheetDocument14 pagesTorsional Vibration Spread SheetRPDeshNo ratings yet
- Factor AnalysisDocument3 pagesFactor AnalysisarsalanNo ratings yet
- Fa SPSSDocument40 pagesFa SPSSSaad MotawéaNo ratings yet
- Structures Lab 1 - Cantilever Flexure BeamDocument12 pagesStructures Lab 1 - Cantilever Flexure BeamDavid Clark100% (4)
- 11 - Chapter 4Document48 pages11 - Chapter 4Humberto AgmNo ratings yet
- Chem152 Kinetics2 Report PC Gradescope 011420 PDFDocument6 pagesChem152 Kinetics2 Report PC Gradescope 011420 PDFNam NguyenNo ratings yet
- Continuous System and Review ProblemsDocument10 pagesContinuous System and Review ProblemsVictoria FreemanNo ratings yet
- Tugas - Data Preparation and AnalysisDocument4 pagesTugas - Data Preparation and AnalysisAndersonkevin GwenhureNo ratings yet
- Scoring Matrices 06Document25 pagesScoring Matrices 06jitendraNo ratings yet
- Assignment 4 SolnDocument3 pagesAssignment 4 SolnJanNo ratings yet
- Statistics For Engineers-Fall 2009 Tutorial-09-SolutionDocument3 pagesStatistics For Engineers-Fall 2009 Tutorial-09-SolutionEsteban Elias Marquez EscalanteNo ratings yet
- Tugas HKSA Deskriptor (Fitriani Choerunnisa (11171013) 3FA1)Document4 pagesTugas HKSA Deskriptor (Fitriani Choerunnisa (11171013) 3FA1)fitriani choerunnisaNo ratings yet
- Maxwell-Boltzmann Distribution For Ideal Gases: 3/2 2 (-Mmvv/2Rt)Document6 pagesMaxwell-Boltzmann Distribution For Ideal Gases: 3/2 2 (-Mmvv/2Rt)Safitri RaufaNo ratings yet
- Hasil SPSS Tak 1-5Document16 pagesHasil SPSS Tak 1-5abdurrasyidNo ratings yet
- Cronbach's Alpha EFA Biến Phụ ThuộcDocument2 pagesCronbach's Alpha EFA Biến Phụ ThuộcThanh VyNo ratings yet
- Is 228 (Part 1) : 1987 Methods For Chemical Analysis Of: (Reaffirmed 2008)Document5 pagesIs 228 (Part 1) : 1987 Methods For Chemical Analysis Of: (Reaffirmed 2008)Indira BanerjeeNo ratings yet
- Intern Presentation SlideDocument41 pagesIntern Presentation Slidejun xiong leeNo ratings yet
- HAI LẦN PTICH NHÂN TỐ KHÁM PHÁDocument9 pagesHAI LẦN PTICH NHÂN TỐ KHÁM PHÁbunkam23.kamNo ratings yet
- Flipper 670 DC Mercury Korfakta 2015 Flipper Marin StockholmDocument1 pageFlipper 670 DC Mercury Korfakta 2015 Flipper Marin StockholmPeter FantNo ratings yet
- Exam 6Document10 pagesExam 6Vannie BelloNo ratings yet
- The Invention of Shopping Tourism. The DDocument19 pagesThe Invention of Shopping Tourism. The DKalvin PratamaNo ratings yet
- OVOP LamonganDocument6 pagesOVOP LamonganKalvin PratamaNo ratings yet
- Kerjasama Pengembangan Klaster-Klaster Industri Kecil Dan MenengahDocument278 pagesKerjasama Pengembangan Klaster-Klaster Industri Kecil Dan MenengahKalvin PratamaNo ratings yet
- Euv14n1p53 PDFDocument16 pagesEuv14n1p53 PDFKalvin PratamaNo ratings yet
- 1 SMDocument9 pages1 SMKalvin PratamaNo ratings yet
- Ain PDFDocument10 pagesAin PDFKalvin PratamaNo ratings yet
- The Role of Urban Trees and Greenspaces in Reducing Urban Air TemperaturesDocument12 pagesThe Role of Urban Trees and Greenspaces in Reducing Urban Air TemperaturesKalvin PratamaNo ratings yet
- Linking Ecosystem Services and Human Health: The Eco-Health Relationship BrowserDocument10 pagesLinking Ecosystem Services and Human Health: The Eco-Health Relationship BrowserKalvin PratamaNo ratings yet
- Tracking Restoration in Natural and Urba PDFDocument16 pagesTracking Restoration in Natural and Urba PDFKalvin PratamaNo ratings yet
- Sword & Shield Fully Evolved Base StatsDocument73 pagesSword & Shield Fully Evolved Base StatsKalvin PratamaNo ratings yet
- The Mystery of Berry Berenson and 9-11Document5 pagesThe Mystery of Berry Berenson and 9-11HierocrypticNo ratings yet
- Texture by The Sand Circle Method MeasurementsDocument2 pagesTexture by The Sand Circle Method MeasurementssajjaduetNo ratings yet
- The Importance of Will and Moral CourageDocument4 pagesThe Importance of Will and Moral CourageCharles Justin C. SaldiNo ratings yet
- Music Laptop Script (WhiteHat JR Customers)Document3 pagesMusic Laptop Script (WhiteHat JR Customers)Yash JainNo ratings yet
- Literacy Planning Sheet Year Group: Reception Stimulus: Jolly Phonics Day Skill Learning Objective Main Teaching Focused Task(s) Key Skill 1Document2 pagesLiteracy Planning Sheet Year Group: Reception Stimulus: Jolly Phonics Day Skill Learning Objective Main Teaching Focused Task(s) Key Skill 1Engy HassanNo ratings yet
- 4 29 2016Document25 pages4 29 2016Aiman LatifNo ratings yet
- Rijwana Hussein Final EssayDocument18 pagesRijwana Hussein Final EssayhusseinrijwanaNo ratings yet
- What's Trending in Difference-In-DifferencesDocument27 pagesWhat's Trending in Difference-In-Differencesteddybear20072003No ratings yet
- BSBSUS601 Ass Task 1 - v2.1Document4 pagesBSBSUS601 Ass Task 1 - v2.1Nupur VermaNo ratings yet
- Bio Physics: Prepared by Gayathry SatheesanDocument19 pagesBio Physics: Prepared by Gayathry SatheesanrehandeshmukhNo ratings yet
- EXTENSOMETRO United - Loadcells - InstrumentsDocument7 pagesEXTENSOMETRO United - Loadcells - InstrumentsAgustin PerdomoNo ratings yet
- BS en 14024-2004 Thermal BreakDocument32 pagesBS en 14024-2004 Thermal BreakGlenn LamboNo ratings yet
- MT Evenness Tester 2341 EN 2022-03Document4 pagesMT Evenness Tester 2341 EN 2022-03Quynh TrangNo ratings yet
- Ravi Shankar's Birth Chart / Kundali: Astrological Services For Accurate Answers and Better FeatureDocument1 pageRavi Shankar's Birth Chart / Kundali: Astrological Services For Accurate Answers and Better FeatureEd ReesNo ratings yet
- 2019jahh 22 447GDocument12 pages2019jahh 22 447GTomi DwiNo ratings yet
- Lightspeed Oneforma GuidelinesDocument59 pagesLightspeed Oneforma GuidelinesKim Chi PhanNo ratings yet
- DESIGN AND ANALYSIS OF HYDRAULIC POWERPACK AND PUMcalculationsDocument10 pagesDESIGN AND ANALYSIS OF HYDRAULIC POWERPACK AND PUMcalculationssubhasNo ratings yet
- Boehm KabelDocument4 pagesBoehm KabelMihai-Sergiu MateiNo ratings yet
- JTBD Excel TemplateDocument3 pagesJTBD Excel TemplateDavid GolinNo ratings yet
- Case Study of Master of Business AdminisDocument8 pagesCase Study of Master of Business AdminisYoke MalondaNo ratings yet
- Pavement DesignDocument12 pagesPavement DesignTarun KumarNo ratings yet
- Coulombs LawDocument8 pagesCoulombs LawDaniel Esteban Pinto ChaparroNo ratings yet
- MomentumDocument16 pagesMomentumminglei caiNo ratings yet
- Summary Epri Workshop 2017Document3 pagesSummary Epri Workshop 2017arissaNo ratings yet
- Exclusion of Oral by Documentary EvidenceDocument6 pagesExclusion of Oral by Documentary EvidenceShashikantSauravBarnwalNo ratings yet
- Qualitative Data Analysis Methods and TechniquesDocument7 pagesQualitative Data Analysis Methods and Techniquessisay gebremariamNo ratings yet
- Training Evaluation Form: Seven Seas HotelDocument2 pagesTraining Evaluation Form: Seven Seas HotelPiyush SevenseasNo ratings yet
- 02 - Financial Accounting - Accounts Receivable ReportsDocument28 pages02 - Financial Accounting - Accounts Receivable ReportsjohnNo ratings yet
- An Analysis of "Limited and Selective Effect Theory" and "Uses and Gratification Theory" From Perspective of Mass Media ResearchDocument6 pagesAn Analysis of "Limited and Selective Effect Theory" and "Uses and Gratification Theory" From Perspective of Mass Media ResearchIAEME PublicationNo ratings yet
- Cap Analysis: (Municipality of Calinog)Document21 pagesCap Analysis: (Municipality of Calinog)mpdo calinogNo ratings yet