You might also like
- Starting A Business Candle Making 2009Document2 pagesStarting A Business Candle Making 2009Carlo Fabros Junio100% (4)
- Basic Guide to Programming Languages Python, JavaScript, and RubyFrom EverandBasic Guide to Programming Languages Python, JavaScript, and RubyNo ratings yet
- 16 Online Translation Tools Recommended by Translators: 1. LingueeDocument4 pages16 Online Translation Tools Recommended by Translators: 1. LingueeDz CaSPeRNo ratings yet
- Computer Programming Languages PDFDocument5 pagesComputer Programming Languages PDFJyoti AryaNo ratings yet
- PythonDocument7 pagesPythonANJANA INFOTECHNo ratings yet
- Project Report On Evaporative CoolerDocument12 pagesProject Report On Evaporative Coolersourabh singh tomerNo ratings yet
- Flexible Ductwork Report - November 2011v2Document69 pagesFlexible Ductwork Report - November 2011v2bommobNo ratings yet
- C#.Net Core (NareshIT)Document205 pagesC#.Net Core (NareshIT)Aniket Nsc0025100% (1)
- JARVIS A PC Voice AssistantDocument9 pagesJARVIS A PC Voice AssistantInternational Journal of Advance Study and Research WorkNo ratings yet
- ChatbotDocument41 pagesChatbotvarsha devarakonda13090% (1)
- Masterbatch Buyers Guide PDFDocument8 pagesMasterbatch Buyers Guide PDFgurver55No ratings yet
- Individual Project - Mason LearyDocument15 pagesIndividual Project - Mason Learyapi-273094620No ratings yet
- Translation TechnologyDocument42 pagesTranslation TechnologyIsra SayedNo ratings yet
- Tuning Sphinx To Outperforme Google2014Document10 pagesTuning Sphinx To Outperforme Google2014hhakim32No ratings yet
- HO W Does Programming Language Work?Document7 pagesHO W Does Programming Language Work?Amal UsmanNo ratings yet
- Chatbot For Generation of Subtitles in Regional Languages: Shreyas B, Aravinth P, Kripakaran PDocument4 pagesChatbot For Generation of Subtitles in Regional Languages: Shreyas B, Aravinth P, Kripakaran P17druva MNo ratings yet
- Module 2 - COSC95 - Evolution of Major Programming Language - VCBDocument8 pagesModule 2 - COSC95 - Evolution of Major Programming Language - VCBApril VasquezNo ratings yet
- 2009 Website LocalizationDocument7 pages2009 Website LocalizationyonathanNo ratings yet
- 1.INTRODUCTION A voice browser is a “device which interprets a (voice) markup language and is capable of generating voice output and/or interpreting voice input,and possibly other input/output modalities." The definition of a voice browser, above, is a broad one.The fact that the system deals with speech is obvious given the first word of the name,but what makes a software system that interacts with the user via speech a "browser"?The information that the system uses (for either domain data or dialog flow) is dynamic and comes somewhere from the Internet. From an end-user's perspective, the impetus is to provide a service similar to what graphical browsers of HTML and related technologies do today, but on devices that are not equipped with full-browsers or even the screens to support them. This situation is only exacerbated by the fact that much of today's content depends on the ability to run scripting languages and 3rd-party plDocument24 pages1.INTRODUCTION A voice browser is a “device which interprets a (voice) markup language and is capable of generating voice output and/or interpreting voice input,and possibly other input/output modalities." The definition of a voice browser, above, is a broad one.The fact that the system deals with speech is obvious given the first word of the name,but what makes a software system that interacts with the user via speech a "browser"?The information that the system uses (for either domain data or dialog flow) is dynamic and comes somewhere from the Internet. From an end-user's perspective, the impetus is to provide a service similar to what graphical browsers of HTML and related technologies do today, but on devices that are not equipped with full-browsers or even the screens to support them. This situation is only exacerbated by the fact that much of today's content depends on the ability to run scripting languages and 3rd-party plPooja ReddyNo ratings yet
- 16 Online Translation Tools Recommended by TranslatorsDocument3 pages16 Online Translation Tools Recommended by TranslatorsReda SndlNo ratings yet
- Top Programming Languages to Learn in 2022: JavaScript, Python & MoreDocument5 pagesTop Programming Languages to Learn in 2022: JavaScript, Python & MoreTiktok PerngacenganNo ratings yet
- Wojciech Froelich: Cto - Argos MultilingualDocument7 pagesWojciech Froelich: Cto - Argos MultilingualAleksanderNo ratings yet
- Tejaswini Group ReportDocument18 pagesTejaswini Group ReportRiyaNo ratings yet
- Voice Browser Seminar ReportDocument5 pagesVoice Browser Seminar Reportanup03_336320810% (1)
- Programming Languages copyDocument19 pagesProgramming Languages copyВарвара ФедорищеваNo ratings yet
- Navigating The Rapid Evolution of Programming LanguageDocument4 pagesNavigating The Rapid Evolution of Programming LanguageNoumaan Ul Haq SyedNo ratings yet
- Text To Speech Converter DocumentationDocument28 pagesText To Speech Converter DocumentationRanjitha H R67% (3)
- 1.1 Background To The Study: Chapter One: IntroductionDocument4 pages1.1 Background To The Study: Chapter One: IntroductionvectorNo ratings yet
- Programming Languages.: L/O/G/ODocument15 pagesProgramming Languages.: L/O/G/OyevhenNo ratings yet
- Computer Programming Language: Saint Anthony College of TechnologyDocument9 pagesComputer Programming Language: Saint Anthony College of TechnologyKath Magbag-RivalesNo ratings yet
- Languages of ComputerDocument6 pagesLanguages of ComputerNaeem AshrafNo ratings yet
- The Evolution of Programming LanguagesDocument5 pagesThe Evolution of Programming Languagesdangabrieldeyro1No ratings yet
- HISTORY OF PROGRAMMING LANGUAGES Ali Zaidi - 049Document9 pagesHISTORY OF PROGRAMMING LANGUAGES Ali Zaidi - 049AliNo ratings yet
- Top Programming LanguagesDocument4 pagesTop Programming LanguagesUroš PopovićNo ratings yet
- Levels of ProgrammingDocument4 pagesLevels of ProgrammingMitchzel Molo MonteroNo ratings yet
- Research Papers Evolution of Programming LanguagesDocument6 pagesResearch Papers Evolution of Programming LanguagesxwrcmecndNo ratings yet
- Future of ProgrammingDocument10 pagesFuture of ProgramminglsklyutNo ratings yet
- Programming Language With High Level LanguageDocument9 pagesProgramming Language With High Level LanguageCalle HodyNo ratings yet
- Research On Speech Recognition Technique While Building Speech Recognition BotDocument13 pagesResearch On Speech Recognition Technique While Building Speech Recognition BotBurhan RajputNo ratings yet
- What Is ProgrammingDocument5 pagesWhat Is ProgrammingSACHIDANAND CHATURVEDINo ratings yet
- Speech Emotion Recognition Using Deep LearningDocument39 pagesSpeech Emotion Recognition Using Deep LearningJohn Cena100% (1)
- Voice BrowsersDocument3 pagesVoice Browsersankireddy080519No ratings yet
- Voice CalculatorDocument8 pagesVoice CalculatorRohit RajNo ratings yet
- Computer Programming Languages in 4 SlidesDocument4 pagesComputer Programming Languages in 4 Slides9312No ratings yet
- Developing A Language For Spoken Programming: Benjamin M. Gordon Department of Computer Science University of New MexicoDocument7 pagesDeveloping A Language For Spoken Programming: Benjamin M. Gordon Department of Computer Science University of New MexicoJohn WatsonNo ratings yet
- Lab 01 - Characteristics of Programming Languages (Answers) PDFDocument5 pagesLab 01 - Characteristics of Programming Languages (Answers) PDFliNo ratings yet
- Programming LanguageDocument24 pagesProgramming LanguagePercival A FernandezNo ratings yet
- Saya Recognition Dragon ReportDocument13 pagesSaya Recognition Dragon ReportRishi SoniNo ratings yet
- Design and Implementation of A Cross Platform Document File Reader Using Speech SynthesisDocument11 pagesDesign and Implementation of A Cross Platform Document File Reader Using Speech SynthesisKIU PUBLICATION AND EXTENSIONNo ratings yet
- Speech Recognition Application Architecture ForDocument4 pagesSpeech Recognition Application Architecture Forhhakim32No ratings yet
- The New Era of Browsing - Voice Browsing: Khushbu, Manika Kapoor, Ayesha TafsirDocument4 pagesThe New Era of Browsing - Voice Browsing: Khushbu, Manika Kapoor, Ayesha TafsirkksNo ratings yet
- Top Programming Languages for Mobile AppsDocument8 pagesTop Programming Languages for Mobile AppsSelam DeliNo ratings yet
- AI Voice Assistant Project ReportDocument12 pagesAI Voice Assistant Project ReportNEWBIE HUNo ratings yet
- The Kaldi Speech Recognition Toolkit PDFDocument4 pagesThe Kaldi Speech Recognition Toolkit PDFngoisaotinhyeu_valleNo ratings yet
- ITEP-206-Lesson-1Document34 pagesITEP-206-Lesson-1kaitlynzeaaNo ratings yet
- Best Programming Languages 2022Document3 pagesBest Programming Languages 2022Riya TiwariNo ratings yet
- Chapter 1Document11 pagesChapter 1amanuelNo ratings yet
- Activity Fundamentals of ProgrammingDocument2 pagesActivity Fundamentals of ProgrammingNestor Navarro Jr.No ratings yet
- Short Notes On C: ISO/IEC 14882:2017 (Informally Known As C++)Document4 pagesShort Notes On C: ISO/IEC 14882:2017 (Informally Known As C++)Kushagra shuklaNo ratings yet
- Voice Controlling Linux Systems: International Journal of Emerging Trends & Technology in Computer Science (IJETTCS)Document2 pagesVoice Controlling Linux Systems: International Journal of Emerging Trends & Technology in Computer Science (IJETTCS)International Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- Transformer Agents Revolutionizing NLP With Hugging Face's Open-Source ToolsDocument6 pagesTransformer Agents Revolutionizing NLP With Hugging Face's Open-Source ToolsMy SocialNo ratings yet
- Unit 1 Introduction A Brief Description of Visual Basic 2010Document12 pagesUnit 1 Introduction A Brief Description of Visual Basic 2010khem sharuNo ratings yet
- Stcfinalsuper 213Document23 pagesStcfinalsuper 213Digvijay jadhavNo ratings yet
- Top 10 Programming Languages of 2011Document1 pageTop 10 Programming Languages of 2011Akshaya Kumar PandaNo ratings yet
- Corporate Governance in SMEsDocument18 pagesCorporate Governance in SMEsSana DjaanineNo ratings yet
- Kennedy 1945 Bibliography of Indonesian Peoples and CulturesDocument12 pagesKennedy 1945 Bibliography of Indonesian Peoples and CulturesJennifer Williams NourseNo ratings yet
- Interesting Facts (Compiled by Andrés Cordero 2023)Document127 pagesInteresting Facts (Compiled by Andrés Cordero 2023)AndresCorderoNo ratings yet
- PedigreesDocument5 pagesPedigreestpn72hjg88No ratings yet
- BOQ - Hearts & Arrows Office 04sep2023Document15 pagesBOQ - Hearts & Arrows Office 04sep2023ChristianNo ratings yet
- Inertial Reference Frames: Example 1Document2 pagesInertial Reference Frames: Example 1abhishek murarkaNo ratings yet
- Environmental Threats Differentiated Reading Comprehension Ver 1Document20 pagesEnvironmental Threats Differentiated Reading Comprehension Ver 1Camila DiasNo ratings yet
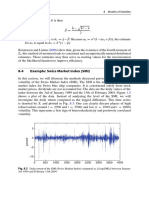
- 8.4 Example: Swiss Market Index (SMI) : 188 8 Models of VolatilityDocument3 pages8.4 Example: Swiss Market Index (SMI) : 188 8 Models of VolatilityNickesh ShahNo ratings yet
- X RayDocument16 pagesX RayMedical Physics2124No ratings yet
- United Airlines Case Study: Using Marketing to Address External ChallengesDocument4 pagesUnited Airlines Case Study: Using Marketing to Address External ChallengesSakshiGuptaNo ratings yet
- Ek Pardesi Mera Dil Le Gaya Lyrics English Translation - Lyrics GemDocument1 pageEk Pardesi Mera Dil Le Gaya Lyrics English Translation - Lyrics Gemmahsa.molaiepanahNo ratings yet
- CP Mother's Day Lesson PlanDocument2 pagesCP Mother's Day Lesson PlanAma MiriNo ratings yet
- Proposed Panel Antenna: Globe Telecom ProprietaryDocument2 pagesProposed Panel Antenna: Globe Telecom ProprietaryJason QuibanNo ratings yet
- Final Annotated BibiliographyDocument4 pagesFinal Annotated Bibiliographyapi-491166748No ratings yet
- GD&T WIZ Tutor Covers The Vast Breadth of Geometric Dimensioning and Tolerancing Without Compromising On The Depth. The Topics Covered AreDocument1 pageGD&T WIZ Tutor Covers The Vast Breadth of Geometric Dimensioning and Tolerancing Without Compromising On The Depth. The Topics Covered AreVinay ManjuNo ratings yet
- BCRW Course - Answer-Booklet PDFDocument18 pagesBCRW Course - Answer-Booklet PDFSarah ChaudharyNo ratings yet
- Abstract Photo CompositionDocument2 pagesAbstract Photo Compositionapi-260853196No ratings yet
- Hanwha Engineering & Construction - Brochure - enDocument48 pagesHanwha Engineering & Construction - Brochure - enAnthony GeorgeNo ratings yet
- English Extra Conversation Club International Women's DayDocument2 pagesEnglish Extra Conversation Club International Women's Dayevagloria11No ratings yet
- Appliance Saver Prevents OverheatingDocument2 pagesAppliance Saver Prevents OverheatingphilipNo ratings yet
- Technology Consulting: Amruta Kulkarni Anu Abraham Rajat JainDocument9 pagesTechnology Consulting: Amruta Kulkarni Anu Abraham Rajat JainRajat JainNo ratings yet
- Ahu, Chiller, Fcu Technical Bid TabulationDocument15 pagesAhu, Chiller, Fcu Technical Bid TabulationJohn Henry AsuncionNo ratings yet
- 4 TheEulerianFunctions - 000 PDFDocument16 pages4 TheEulerianFunctions - 000 PDFShorouk Al- IssaNo ratings yet
- Omobonike 1Document13 pagesOmobonike 1ODHIAMBO DENNISNo ratings yet
- 5.a Personal Diet Consultant For Healthy MealDocument5 pages5.a Personal Diet Consultant For Healthy MealKishore SahaNo ratings yet
- KingmakerDocument5 pagesKingmakerIan P RiuttaNo ratings yet