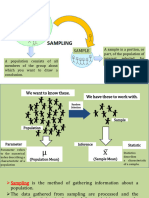
You might also like
- Sampling MethodsDocument7 pagesSampling MethodsshreebhagyeshNo ratings yet
- SamplingDocument22 pagesSamplingkumarianuradha125.akNo ratings yet
- 62 - Ex 12A Populations and SamplesDocument30 pages62 - Ex 12A Populations and SamplesRalph Rezin MooreNo ratings yet
- Sampling & Sampling Distribution: by Asif HanifDocument25 pagesSampling & Sampling Distribution: by Asif Hanifsadia245No ratings yet
- 2006 - Philosophy, Methodology and Action ResearchDocument43 pages2006 - Philosophy, Methodology and Action ResearchnurleennaNo ratings yet
- Sampling & Sampling DistributionsDocument34 pagesSampling & Sampling DistributionsBhagwat BalotNo ratings yet
- Samplin DistnDocument37 pagesSamplin DistnRaffayNo ratings yet
- Curs 6-EsantionareaDocument23 pagesCurs 6-EsantionareaSTIUCA CRISTINA-DANIELANo ratings yet
- Measurement and Scales and Selecting Sampling 21102022 095103amDocument21 pagesMeasurement and Scales and Selecting Sampling 21102022 095103amMuhammad ZubairNo ratings yet
- SamplingDocument22 pagesSamplingtatevijayNo ratings yet
- WEEK 2. Sampling TechniquesDocument23 pagesWEEK 2. Sampling Techniquesandrell.alfafaraNo ratings yet
- Sampling and Its TypesDocument27 pagesSampling and Its TypesNeelamani SamalNo ratings yet
- Probability Sampling Methods and Nonprobability Sampling MethdsDocument48 pagesProbability Sampling Methods and Nonprobability Sampling MethdsMarjorie Joyce BarituaNo ratings yet
- 02 ABE Review - Sampling TechniquesDocument41 pages02 ABE Review - Sampling TechniquesRio Banan IINo ratings yet
- Sampling (Method)Document31 pagesSampling (Method)kia.reshuNo ratings yet
- Introduction To Inferential Statistics Objectives: ExampleDocument12 pagesIntroduction To Inferential Statistics Objectives: ExampleMarianne Christie RagayNo ratings yet
- AE 9 AY 2021-2022 Module 2 (Complete)Document32 pagesAE 9 AY 2021-2022 Module 2 (Complete)Mae Ann RaquinNo ratings yet
- Sample Size: Slovin's EquationDocument6 pagesSample Size: Slovin's Equationthyrany cattelNo ratings yet
- Sampling DistributionDocument29 pagesSampling DistributionFun Toosh345No ratings yet
- Leigh Shawntel J. Nitro Bsmt-1A Biostatistics Activity n0.2Document3 pagesLeigh Shawntel J. Nitro Bsmt-1A Biostatistics Activity n0.2Lue Soles100% (3)
- Random SamplingDocument26 pagesRandom SamplingAirene CastañosNo ratings yet
- Sampling 1Document26 pagesSampling 1Abhijit AshNo ratings yet
- Sampling - PPT - Google SlidesDocument20 pagesSampling - PPT - Google Slidesnaveen816876No ratings yet
- Sampling and Sampling TechniquesDocument25 pagesSampling and Sampling TechniquesNinoNo ratings yet
- NJC Sampling Lecture NotesDocument24 pagesNJC Sampling Lecture NotesbhimabiNo ratings yet
- BIOMETRYDocument37 pagesBIOMETRYAddisu GedamuNo ratings yet
- J. K. Shah Classes Sampling Theory and Theory of EstimationDocument37 pagesJ. K. Shah Classes Sampling Theory and Theory of EstimationGautamNo ratings yet
- Sampling and Sampling DisttDocument28 pagesSampling and Sampling DisttIshrat Hussain TuriNo ratings yet
- MRM Mod 3Document121 pagesMRM Mod 3Mamatha NUNo ratings yet
- SAMPLING AND ESTIMATION Notes and ExamplesDocument20 pagesSAMPLING AND ESTIMATION Notes and ExamplesHaddonesKimberlyNo ratings yet
- Punjabi University Faculty of Social Science and Humanity Department of Public AdministrationDocument47 pagesPunjabi University Faculty of Social Science and Humanity Department of Public AdministrationwondemNo ratings yet
- Sampling and Sampling DistributionsDocument44 pagesSampling and Sampling Distributionskunal kabraNo ratings yet
- A.Bhargavi Synergy School of BusinessDocument25 pagesA.Bhargavi Synergy School of BusinessSravan KumarNo ratings yet
- SAMPLINGDocument19 pagesSAMPLINGseenubarman12No ratings yet
- Research Population, Sample Size & Sampling Methods - Quantitative ResearchDocument22 pagesResearch Population, Sample Size & Sampling Methods - Quantitative ResearchJanelle DuranNo ratings yet
- Lecture 3 Sampling and Sampling Distribution - Probability and Non-Probability SamplingDocument16 pagesLecture 3 Sampling and Sampling Distribution - Probability and Non-Probability SamplingAfaq ZaimNo ratings yet
- Statistics and Probability Module 3 ModifiedDocument16 pagesStatistics and Probability Module 3 ModifiedUsman DitucalanNo ratings yet
- Name: Pangilinan, Maria Angela Q. Section: BSMT1-1D Biostatistics Activity n0.2Document3 pagesName: Pangilinan, Maria Angela Q. Section: BSMT1-1D Biostatistics Activity n0.2Mira Swan100% (1)
- Lecture 4Document23 pagesLecture 4thomasNo ratings yet
- Data Management Plan Sampling DesignDocument30 pagesData Management Plan Sampling DesignDhruvil GosaliaNo ratings yet
- RM Unit 2Document52 pagesRM Unit 2mayankjain08248No ratings yet
- Sampling MethodsDocument6 pagesSampling Methods'Sari' Siti Khadijah HapsariNo ratings yet
- Probability SamplingDocument22 pagesProbability Samplingbasaallen566No ratings yet
- Sampling Techniques TULIO JO GABRIELDocument35 pagesSampling Techniques TULIO JO GABRIELIVY FAULVENo ratings yet
- Business StatisticsDocument114 pagesBusiness Statisticstarekegn gezahegnNo ratings yet
- Sampling TechniquesDocument8 pagesSampling TechniquesMARIA ABIGAIL PAMAHOYNo ratings yet
- Chapter 7 - Sampling DistributionsDocument82 pagesChapter 7 - Sampling DistributionsLauren MichelleNo ratings yet
- Unit IiiDocument45 pagesUnit Iii05Bala SaatvikNo ratings yet
- Sampling Fundamentals ModifiedDocument48 pagesSampling Fundamentals ModifiedAniket PuriNo ratings yet
- Sampling and Sampling DistributionDocument46 pagesSampling and Sampling DistributionMaria Loida Veronica NaborNo ratings yet
- SamplingDocument5 pagesSamplingkeniviha goodingNo ratings yet
- Presentation On Sampling: Group MembersDocument42 pagesPresentation On Sampling: Group MembersShahid Ali DurraniNo ratings yet
- Random Sampling, Parameter and Statistics, Sampling Distribution of StatisticsDocument26 pagesRandom Sampling, Parameter and Statistics, Sampling Distribution of StatisticsMary Grace Manzano AdevaNo ratings yet
- Module 3# SamplingDocument24 pagesModule 3# SamplingPratik BhudkeNo ratings yet
- Sampling Methods - Probability SamplingDocument7 pagesSampling Methods - Probability SamplingjoelNo ratings yet
- Statistics Assignment: by Vuyyuri Sujith Varma REG - NO: 17010141138 Bba Sec (A) Sem-2Document20 pagesStatistics Assignment: by Vuyyuri Sujith Varma REG - NO: 17010141138 Bba Sec (A) Sem-2Ritik SharmaNo ratings yet
- SAMPLING DISTRIBUTION 1autorecovered 310922401106253550Document92 pagesSAMPLING DISTRIBUTION 1autorecovered 310922401106253550Joshua barriosNo ratings yet
- Stats Definitions-1Document4 pagesStats Definitions-1nimrashahidcommerceicomNo ratings yet
- JD EconomistDocument1 pageJD EconomistLakhan Subhash TrivediNo ratings yet
- Am JobdescriptionDocument1 pageAm JobdescriptionLakhan Subhash TrivediNo ratings yet
- MKTG MGMT - Sem 2 - Lec 6 - Product Service PackagingDocument5 pagesMKTG MGMT - Sem 2 - Lec 6 - Product Service PackagingLakhan Subhash TrivediNo ratings yet
- Lec 6 Political and Legal Business EnvironmentDocument18 pagesLec 6 Political and Legal Business EnvironmentLakhan Subhash TrivediNo ratings yet
- Foundation of EconomicsDocument19 pagesFoundation of EconomicsHussainNo ratings yet
- Lec 9 National IncomeDocument65 pagesLec 9 National IncomeLakhan Subhash TrivediNo ratings yet
- Chapter 5 ProbabilityDocument58 pagesChapter 5 ProbabilityLakhan Subhash TrivediNo ratings yet
- Chapter 9 One Sample Hypothesis TestingDocument25 pagesChapter 9 One Sample Hypothesis TestingLakhan Subhash TrivediNo ratings yet
- FM - ReportDocument9 pagesFM - ReportPyar Paolo dela CruzNo ratings yet
- Stress Intensity of A Nursing Students Regarding ToDocument10 pagesStress Intensity of A Nursing Students Regarding ToRajaAnantaNo ratings yet
- Chap 7 Bodie 9eDocument13 pagesChap 7 Bodie 9eChristan LambertNo ratings yet
- 2.4 the Binomial Distribution 習題Document5 pages2.4 the Binomial Distribution 習題sandywu930510No ratings yet
- Or 5081Document3 pagesOr 5081Sahar DesokeyNo ratings yet
- The Satisfaction With Work Scale (SWWS)Document10 pagesThe Satisfaction With Work Scale (SWWS)AleCsss123No ratings yet
- Art Biomateriales DentalesDocument4 pagesArt Biomateriales Dentalesjavierobandoceron90No ratings yet
- Quantitative MethodsDocument36 pagesQuantitative MethodsMatthew KiraNo ratings yet
- PSI 2 Course Material v2.2Document41 pagesPSI 2 Course Material v2.2sreenathNo ratings yet
- Cost Benefit Analysis in T & DDocument18 pagesCost Benefit Analysis in T & DDarshan Patil100% (5)
- ASTM G 16 - 95 r99 - Rze2ltk1ujk5rteDocument14 pagesASTM G 16 - 95 r99 - Rze2ltk1ujk5rteCordova RaphaelNo ratings yet
- Chapter8 StudentDocument60 pagesChapter8 StudentsanjayNo ratings yet
- Homework Discrete Random VariablesDocument13 pagesHomework Discrete Random Variablespiyush raghavNo ratings yet
- Crystal Ball TutorialDocument39 pagesCrystal Ball Tutorialsaher8901100% (1)
- Chapter 3Document81 pagesChapter 3Afifa SuibNo ratings yet
- Stroking Characteristics in Freestyle SwimmingDocument10 pagesStroking Characteristics in Freestyle SwimmingAndica DiamantaNo ratings yet
- StatDocument10 pagesStatJun Rex SaloNo ratings yet
- II - MD (Hom) Materia Medica - SyllabusDocument43 pagesII - MD (Hom) Materia Medica - SyllabusDr. Bhumika NarvaneNo ratings yet
- Phys 151LDocument224 pagesPhys 151LAbigaleFernandezNo ratings yet
- Business Analytics Data Analysis and Decision Making 6th Edition Albright Solutions Manual DownloadDocument56 pagesBusiness Analytics Data Analysis and Decision Making 6th Edition Albright Solutions Manual DownloadHeather Williams100% (26)
- Confidence IntervalsDocument6 pagesConfidence Intervalsandrew22No ratings yet
- BS Masterfile - Latest - April 29thDocument110 pagesBS Masterfile - Latest - April 29thRahul HansNo ratings yet
- Using Significant Digits in Test Data To Determine Conformance With Specifications'Document5 pagesUsing Significant Digits in Test Data To Determine Conformance With Specifications'José de Paula MoreiraNo ratings yet
- Appendix ComputationDocument20 pagesAppendix Computationgirlwithglasses50% (4)
- Effect of Heat and Air On A Moving Film of Asphalt (Rolling Thin-Film Oven Test)Document6 pagesEffect of Heat and Air On A Moving Film of Asphalt (Rolling Thin-Film Oven Test)ROBERTO MIRANDANo ratings yet
- Introductory Econometrics Asia Pacific 1St Edition Wooldridge Test Bank Full Chapter PDFDocument26 pagesIntroductory Econometrics Asia Pacific 1St Edition Wooldridge Test Bank Full Chapter PDFmrissaancun100% (7)
- Homework 2 PURBADocument4 pagesHomework 2 PURBAArdyanthaSivadaberthPurbaNo ratings yet
- ASTM C 1437 - Flow of MortarsDocument2 pagesASTM C 1437 - Flow of MortarsWan T Trianto80% (5)
- Early Stiffening of Hydraulic Cement (Paste Method) : Standard Test Method ForDocument3 pagesEarly Stiffening of Hydraulic Cement (Paste Method) : Standard Test Method ForINARQ1979No ratings yet
- Leapfrog Filer CircuitDocument6 pagesLeapfrog Filer CircuitmailmadoNo ratings yet