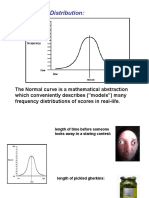
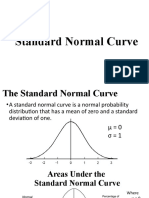
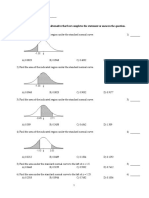
You might also like
- Basic Statistical Descriptions of Data: Dr. Amiya Ranjan PandaDocument35 pagesBasic Statistical Descriptions of Data: Dr. Amiya Ranjan PandaAnu agarwalNo ratings yet
- Variance and Standard DeviationDocument16 pagesVariance and Standard Deviationmehtab sanaNo ratings yet
- Normal Distribution 2012Document29 pagesNormal Distribution 2012Isaac Daplas RosarioNo ratings yet
- Let LetDocument29 pagesLet LetIsaac Daplas RosarioNo ratings yet
- Standard Scores and The Normal Curve: Study GuideDocument51 pagesStandard Scores and The Normal Curve: Study GuideHannah Gliz PantoNo ratings yet
- NormalDistribution2012 PDFDocument29 pagesNormalDistribution2012 PDFElisa Dela Reyna BaladadNo ratings yet
- Everything You Ever Wanted To Know About Statistics: Prof. Andy FieldDocument37 pagesEverything You Ever Wanted To Know About Statistics: Prof. Andy FieldMohan PudasainiNo ratings yet
- Measures of Central Tendency and Dispersion/ VariabilityDocument35 pagesMeasures of Central Tendency and Dispersion/ VariabilitykabaganikassandraNo ratings yet
- Module 2 - Sample - AfterclassDocument36 pagesModule 2 - Sample - AfterclassVanessa WongNo ratings yet
- Chapter 3B - SPECIAL: Probability DistributionDocument28 pagesChapter 3B - SPECIAL: Probability DistributionAhmad AiNo ratings yet
- Measures of VariablityDocument62 pagesMeasures of VariablityArvin CansangNo ratings yet
- Mathematical AnalysisDocument46 pagesMathematical AnalysisGilbert Dwasi100% (1)
- Statistics: Technical Mathematics 2Document11 pagesStatistics: Technical Mathematics 2Curtis MarcelleNo ratings yet
- Normal Distribution 2012Document29 pagesNormal Distribution 2012kya karegaNo ratings yet
- Normal Distribution 2012Document29 pagesNormal Distribution 2012Gabriel LloydNo ratings yet
- Stats Lecture 06. Normal Distribution DataDocument46 pagesStats Lecture 06. Normal Distribution DataShair Muhammad hazaraNo ratings yet
- Mathmetics On Normal DistributionDocument10 pagesMathmetics On Normal DistributionManohar DattNo ratings yet
- FINAL EXAM IN E-WPS OfficeDocument12 pagesFINAL EXAM IN E-WPS OfficeLorwel ReyesNo ratings yet
- Statistics Booklet For NEW A Level AQADocument66 pagesStatistics Booklet For NEW A Level AQAMurk NiazNo ratings yet
- Standard DeviationDocument9 pagesStandard DeviationPresana VisionNo ratings yet
- Statistics and Probability: Normal DistributionDocument40 pagesStatistics and Probability: Normal Distributionmary jane garcinesNo ratings yet
- Statistics Booklet For NEW A Level AQADocument68 pagesStatistics Booklet For NEW A Level AQAFarhan AktarNo ratings yet
- Week 2 Measures of Dispersion IIDocument34 pagesWeek 2 Measures of Dispersion IITildaNo ratings yet
- TEC301 StatisticsDocument22 pagesTEC301 StatisticsTinevimbo MugabeNo ratings yet
- 06a - The Normal DistributionDocument36 pages06a - The Normal DistributionhammadNo ratings yet
- 21 StatsLecture 07Document31 pages21 StatsLecture 07Christian Alfred VillenaNo ratings yet
- KWT 4.ukuran Keragaman Data 2013Document29 pagesKWT 4.ukuran Keragaman Data 2013AndiNo ratings yet
- Standard Deviation: Unit 6Document16 pagesStandard Deviation: Unit 6Kirandeep SinghNo ratings yet
- QA EstimationDocument39 pagesQA EstimationSumit AcharyaNo ratings yet
- Principles of The T-Test and ANOVADocument64 pagesPrinciples of The T-Test and ANOVAsamiamehboob786No ratings yet
- Notes 4 Visualizing Data RJMurden 2021Document48 pagesNotes 4 Visualizing Data RJMurden 2021BenNo ratings yet
- SPREADDocument19 pagesSPREADJustine joy cruzNo ratings yet
- The Binomial Expansion The Binomial and Normal Distribution: ObjectivesDocument38 pagesThe Binomial Expansion The Binomial and Normal Distribution: ObjectivesRafJanuaBercasioNo ratings yet
- Bioepi Lesson 6. Descriptive StatisticsDocument38 pagesBioepi Lesson 6. Descriptive StatisticsKhelly Joshua UyNo ratings yet
- Calculating The Mean Given A Frequency Distribution TableDocument16 pagesCalculating The Mean Given A Frequency Distribution TableJezreel G. DiazNo ratings yet
- Lecture 8 STA 103Document8 pagesLecture 8 STA 103kennedyNo ratings yet
- Estrellado Rommel E. - Activity 5Document11 pagesEstrellado Rommel E. - Activity 5CBME STRATEGIC MANAGEMENTNo ratings yet
- Statical Data 1Document32 pagesStatical Data 1Irma Estela Marie EstebanNo ratings yet
- Normal Distribution: It Can Be Spread Out More On The Left or More On The RightDocument10 pagesNormal Distribution: It Can Be Spread Out More On The Left or More On The Righteinz82No ratings yet
- 4 Sampling Distributions RevisedDocument21 pages4 Sampling Distributions Revisedlogicalbase3498No ratings yet
- 21MDS13 7. Measures of Central TendencyDocument30 pages21MDS13 7. Measures of Central TendencyshanmugapriyaaNo ratings yet
- Probability and Statistics in EngineeringDocument24 pagesProbability and Statistics in EngineeringasadNo ratings yet
- BS-chapter2-2022-Skewness & Kertosis-Graphical Rep-Spss-22Document40 pagesBS-chapter2-2022-Skewness & Kertosis-Graphical Rep-Spss-22ShayanNo ratings yet
- Variance and Standard DeviationDocument15 pagesVariance and Standard DeviationSrikirupa V Muraly100% (3)
- Measures of Shape: Skewness and KurtosisDocument13 pagesMeasures of Shape: Skewness and KurtosisPriscilla Rachel MeganathanNo ratings yet
- Topic 19 Identifying The Appropriate Rejection Region For A Given Level of SignificanceDocument8 pagesTopic 19 Identifying The Appropriate Rejection Region For A Given Level of SignificancePrincess VernieceNo ratings yet
- Measures of Central TendencyDocument39 pagesMeasures of Central TendencyShivam SrivastavaNo ratings yet
- Statistics in Education: DistributionDocument79 pagesStatistics in Education: DistributionLawanya LetchumananNo ratings yet
- Think Tank: Normal DistributionDocument19 pagesThink Tank: Normal DistributionNikki AlquinoNo ratings yet
- Research Notes (Chapter 3-5)Document14 pagesResearch Notes (Chapter 3-5)Joong SeoNo ratings yet
- Basic Statistics: Techniques of Observational Astronomy AST3722CDocument6 pagesBasic Statistics: Techniques of Observational Astronomy AST3722Cskp23No ratings yet
- Chapter 4 The Normal DistributionDocument12 pagesChapter 4 The Normal Distributionleonessa jorban cortesNo ratings yet
- Activity 4 Mean Median and Mode 1Document8 pagesActivity 4 Mean Median and Mode 1Valerie MarasiganNo ratings yet
- Week 11 Probability and StatisticsDocument27 pagesWeek 11 Probability and StatisticsRamenKing12No ratings yet
- Lec.3 Measures of Spread (1) .Document15 pagesLec.3 Measures of Spread (1) .Zainab Jamal SiddiquiNo ratings yet
- Errors Eng 1 - Part5Document4 pagesErrors Eng 1 - Part5awrr qrq2rNo ratings yet
- Chapter 3Document23 pagesChapter 3MomedNo ratings yet
- GCSE Maths Revision: Cheeky Revision ShortcutsFrom EverandGCSE Maths Revision: Cheeky Revision ShortcutsRating: 3.5 out of 5 stars3.5/5 (2)
- More Minute Math Drills, Grades 3 - 6: Multiplication and DivisionFrom EverandMore Minute Math Drills, Grades 3 - 6: Multiplication and DivisionRating: 5 out of 5 stars5/5 (1)
- The Practically Cheating Statistics Handbook, The Sequel! (2nd Edition)From EverandThe Practically Cheating Statistics Handbook, The Sequel! (2nd Edition)Rating: 4.5 out of 5 stars4.5/5 (3)
- WFP Sses 2014 127705 Jasaan Cs SchoolDocument6 pagesWFP Sses 2014 127705 Jasaan Cs SchoolRey Marion CabagNo ratings yet
- Book 1Document2 pagesBook 1Rey Marion CabagNo ratings yet
- Work and Financial Plan Template 1Document4 pagesWork and Financial Plan Template 1Auvie Mjei TalosigNo ratings yet
- SBFP WFP 2020Document8 pagesSBFP WFP 2020Rey Marion Cabag100% (1)
- Financial Plan Template 5Document4 pagesFinancial Plan Template 5Rey Marion CabagNo ratings yet
- m2 2 Variation Z ScoresDocument18 pagesm2 2 Variation Z ScoresRey Marion CabagNo ratings yet
- Introduction To Linear Algebra: Mark Goldman Emily MackeviciusDocument110 pagesIntroduction To Linear Algebra: Mark Goldman Emily MackeviciusRey Marion CabagNo ratings yet
- Introduction To Vectors: March 2, 2010Document14 pagesIntroduction To Vectors: March 2, 2010Rey Marion CabagNo ratings yet
- Basic Math: Vectors and Scalars Addition/Subtraction of Vectors Unit Vectors Dot ProductDocument9 pagesBasic Math: Vectors and Scalars Addition/Subtraction of Vectors Unit Vectors Dot ProductAjay Mohan MNo ratings yet
- Aata 20150812Document352 pagesAata 20150812tbrackman99No ratings yet
- Abstract Algebra - Schaum PDFDocument314 pagesAbstract Algebra - Schaum PDFJose Alejandro ListaNo ratings yet
- Science, Technology, and SocietyDocument22 pagesScience, Technology, and SocietyRey Marion CabagNo ratings yet
- Applications of Linear Algebra: A Group I Project byDocument35 pagesApplications of Linear Algebra: A Group I Project byShashwat SrivastavaNo ratings yet
- Physics 121: Electricity & Magnetism - Lecture 1: Dale E. Gary Wenda CaoDocument32 pagesPhysics 121: Electricity & Magnetism - Lecture 1: Dale E. Gary Wenda CaoRey Marion CabagNo ratings yet
- ST112: Science, Technology and SocietyDocument18 pagesST112: Science, Technology and SocietyAbby Umali-HernandezNo ratings yet
- Introduction To Vectors: March 2, 2010Document14 pagesIntroduction To Vectors: March 2, 2010Rey Marion CabagNo ratings yet
- Linear Algebra - UniversiDocument29 pagesLinear Algebra - UniversiPuja KumariNo ratings yet
- STS SyllabusDocument12 pagesSTS SyllabusStephanie Ann Marie Dueñas100% (4)
- STS SyllabusDocument12 pagesSTS SyllabusStephanie Ann Marie Dueñas100% (4)
- Physics 121: Electricity & Magnetism - Lecture 1: Dale E. Gary Wenda CaoDocument32 pagesPhysics 121: Electricity & Magnetism - Lecture 1: Dale E. Gary Wenda CaoRey Marion CabagNo ratings yet
- Science, Technology and SocietyDocument11 pagesScience, Technology and SocietyAurfeliNo ratings yet
- Science Technology and SocietyDocument38 pagesScience Technology and SocietyAntonio Capao50% (2)
- Science Technology and SocietyDocument38 pagesScience Technology and SocietyAntonio Capao50% (2)
- Basic Math: Vectors and Scalars Addition/Subtraction of Vectors Unit Vectors Dot ProductDocument9 pagesBasic Math: Vectors and Scalars Addition/Subtraction of Vectors Unit Vectors Dot ProductAjay Mohan MNo ratings yet
- Syllabus - Science, Technology, and SocietyDocument9 pagesSyllabus - Science, Technology, and SocietyMoises A. Almendares80% (5)
- Lecture Notes On Introduction To Science, Technology and SocietyDocument16 pagesLecture Notes On Introduction To Science, Technology and Societyedwineiou90% (77)
- SP-Chapter 14 PresentationDocument83 pagesSP-Chapter 14 PresentationManu SinghNo ratings yet
- Science, Technology, and SocietyDocument22 pagesScience, Technology, and SocietyRey Marion CabagNo ratings yet
- Lecture Notes On Introduction To Science, Technology and SocietyDocument16 pagesLecture Notes On Introduction To Science, Technology and Societyedwineiou90% (77)
- Week1 - Central Limit TheoremDocument23 pagesWeek1 - Central Limit TheoremBenedick CruzNo ratings yet
- Management Science L5Document11 pagesManagement Science L5Santos JewelNo ratings yet
- Module Week-7Document24 pagesModule Week-7aybi pearlNo ratings yet
- Lesson 4 - Standard Normal DistributionDocument26 pagesLesson 4 - Standard Normal Distributionktamog16No ratings yet
- Statistics and Probability Q3M3: The Normal DistributionDocument69 pagesStatistics and Probability Q3M3: The Normal DistributionDharyl BallartaNo ratings yet
- Normal Distribution WorksheetDocument1 pageNormal Distribution WorksheetcmisaacNo ratings yet
- Identifying-Regions-Under-Normal-Curve .Document34 pagesIdentifying-Regions-Under-Normal-Curve .RHEMSON GAMINGNo ratings yet
- Standard Normal TableDocument1 pageStandard Normal TablePriyaa Tharasini A/p MurugiahNo ratings yet
- Z - Table (Standardized Normal Distribution) :: Z X X SDocument1 pageZ - Table (Standardized Normal Distribution) :: Z X X SrnlpzcyNo ratings yet
- Normal Curve Distribution IIIf-2-3 Chapter 2 Lesson 1Document20 pagesNormal Curve Distribution IIIf-2-3 Chapter 2 Lesson 1CHARLYN JOY SUMALINOGNo ratings yet
- 2 Normal DistributionDocument39 pages2 Normal DistributionDANELYN PINGKIANNo ratings yet
- Stat and Prob Q3 Week 5 Mod5 Carla CatherineDocument20 pagesStat and Prob Q3 Week 5 Mod5 Carla CatherineCharlene Binasahan100% (2)
- Z TableDocument1 pageZ TablekennethNo ratings yet
- Statistics For ManagememtDocument152 pagesStatistics For Managememttowfik sefaNo ratings yet
- Lesson 2.3 Standard Normal Curve and Z ScoresDocument18 pagesLesson 2.3 Standard Normal Curve and Z ScoresKlarence Timothy Pineda BundangNo ratings yet
- CPM Statistics 5-3Document17 pagesCPM Statistics 5-3qiuzimingfrank2025No ratings yet
- Stat-Prob Q3 Week4Document18 pagesStat-Prob Q3 Week4arfredbileg08No ratings yet
- L3-GEC410-S. O. Edeki - Module-1Document45 pagesL3-GEC410-S. O. Edeki - Module-1PreciousNo ratings yet
- Application of Normal DistributionDocument6 pagesApplication of Normal DistributionRochelle Catherine Serrano CiprianoNo ratings yet
- Normal Distrib PRENHALL Public PDFDocument34 pagesNormal Distrib PRENHALL Public PDFSriniwas JhaNo ratings yet
- Lesson 2.3 Standard Normal Curve and Z ScoresDocument19 pagesLesson 2.3 Standard Normal Curve and Z ScoresKlarence Timothy Pineda BundangNo ratings yet
- G11 STATPRB Q3 Module4 W4Document24 pagesG11 STATPRB Q3 Module4 W4Dylan Federico BonoanNo ratings yet
- MULTIPLE CHOICE. Choose The One Alternative That Best Completes The Statement or Answers The Question. Provide An Appropriate ResponseDocument15 pagesMULTIPLE CHOICE. Choose The One Alternative That Best Completes The Statement or Answers The Question. Provide An Appropriate ResponsePratyush Goel100% (1)
- Chapter 7Document32 pagesChapter 7Hasan HubailNo ratings yet
- ?Q3 Statistics and Probability ReviewerDocument6 pages?Q3 Statistics and Probability Reviewerjustindimaandal8No ratings yet
- Normal Probability DistributionsDocument104 pagesNormal Probability DistributionsArfi SamboraNo ratings yet
- CMMW ReviewerDocument11 pagesCMMW ReviewerHoward ValenciaNo ratings yet
- Standard Normal DistributionDocument25 pagesStandard Normal DistributionMarcy BoralNo ratings yet
- SND AuDocument5 pagesSND AuMark Jayson Almoite YadaoNo ratings yet
- BS UNIT 2 Normal Distribution NewDocument41 pagesBS UNIT 2 Normal Distribution NewSherona ReidNo ratings yet