You might also like
- Data ManagementDocument44 pagesData ManagementStephen Sumipo BastatasNo ratings yet
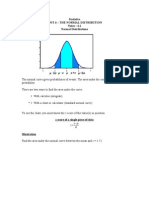
- Statistics For Data Science: What Is Normal Distribution?Document13 pagesStatistics For Data Science: What Is Normal Distribution?Ramesh MudhirajNo ratings yet
- Normal Distribution Guide - Meaning, Examples, Formulas & UsesDocument13 pagesNormal Distribution Guide - Meaning, Examples, Formulas & UsesMarvin Dionel BathanNo ratings yet
- Getting started with descriptive statistics and probability for data scienceDocument7 pagesGetting started with descriptive statistics and probability for data scienceNIKHILESH M NAIK 1827521100% (1)
- Continuous Probability DistributionsDocument8 pagesContinuous Probability DistributionsLupita JiménezNo ratings yet
- Standard Deviation and Its ApplicationsDocument8 pagesStandard Deviation and Its Applicationsanon_882394540100% (1)
- Normal Distribution CurveDocument15 pagesNormal Distribution CurveLoe HiNo ratings yet
- Statistical Analysis of Rainfall DataDocument22 pagesStatistical Analysis of Rainfall DataMomostafaNo ratings yet
- Day 02-Random Variable and Probability - Part (I)Document34 pagesDay 02-Random Variable and Probability - Part (I)Sparsh VijayvargiaNo ratings yet
- Statistics For Management Decisions MG913: Sampling Distributions and Confidence IntervalsDocument31 pagesStatistics For Management Decisions MG913: Sampling Distributions and Confidence IntervalsAshraf SeragNo ratings yet
- PPT+59+ +Ex+11B+Standardisation,+68!95!99.7+RuleDocument23 pagesPPT+59+ +Ex+11B+Standardisation,+68!95!99.7+RuleRalph Rezin MooreNo ratings yet
- Normal Distribution1Document8 pagesNormal Distribution1ely san100% (1)
- Normal Distribution Undergrad 2022Document41 pagesNormal Distribution Undergrad 2022gerwadakasumuni2121No ratings yet
- Bus 173 - 1Document28 pagesBus 173 - 1Mirza Asir IntesarNo ratings yet
- Week 4-Normal Distribution and Empirical RuleDocument27 pagesWeek 4-Normal Distribution and Empirical RuleanushajjNo ratings yet
- Probability NotesDocument8 pagesProbability NotesPrachi TyagiNo ratings yet
- Continuous Probability DistributionDocument53 pagesContinuous Probability Distributionanola prickNo ratings yet
- Maths Section ADocument5 pagesMaths Section AManish KumarNo ratings yet
- Sampling and Statistical Inference: Eg: What Is The Average Income of All Stern Students?Document11 pagesSampling and Statistical Inference: Eg: What Is The Average Income of All Stern Students?Ahmad MostafaNo ratings yet
- Week#7 SIM (Normal Distribution)Document27 pagesWeek#7 SIM (Normal Distribution)Mr.JoJINo ratings yet
- Normal DistributionDocument5 pagesNormal DistributionHarika KalluriNo ratings yet
- Statistics ExamDocument2 pagesStatistics ExamKhanim RzaevaNo ratings yet
- Standard Deviation and VarianceDocument18 pagesStandard Deviation and VarianceIzi100% (3)
- Analysis of Sample MeanDocument43 pagesAnalysis of Sample MeanJabeen JarrarNo ratings yet
- What Is Distribution?Document4 pagesWhat Is Distribution?Navneet LalwaniNo ratings yet
- Confidence Intervals PDFDocument5 pagesConfidence Intervals PDFwolfretonmathsNo ratings yet
- Statistics Unit 6 NotesDocument10 pagesStatistics Unit 6 NotesgopscharanNo ratings yet
- Mathmetics On Normal DistributionDocument10 pagesMathmetics On Normal DistributionManohar DattNo ratings yet
- 3 - Introduction To Inferential StatisticsDocument32 pages3 - Introduction To Inferential StatisticsVishal ShivhareNo ratings yet
- Chapter 04 RDocument31 pagesChapter 04 RAdriancisneros Pel0% (1)
- Binomial Distributions For Sample CountsDocument38 pagesBinomial Distributions For Sample CountsVishnu VenugopalNo ratings yet
- Business Quantitative TechniquesDocument52 pagesBusiness Quantitative TechniquesUzair Zia NagiNo ratings yet
- Normal Distribution Nov 2021 - FinalDocument36 pagesNormal Distribution Nov 2021 - FinalmussaNo ratings yet
- Normal Distribution MeaningDocument6 pagesNormal Distribution MeaningBhuv SharmaNo ratings yet
- Mids UnitDocument13 pagesMids Unit2344Atharva PatilNo ratings yet
- Frequency DistributionDocument35 pagesFrequency DistributionVivek AgrahariNo ratings yet
- Applications of ProbabilityDocument11 pagesApplications of ProbabilityJeffreyReyesNo ratings yet
- Chapter 6Document7 pagesChapter 6storkyddNo ratings yet
- Spss Training MaterialDocument117 pagesSpss Training MaterialSteve ElroyNo ratings yet
- Confidence Interval Sample SizeDocument6 pagesConfidence Interval Sample SizeegcaldwellNo ratings yet
- Assignment 2 State ArmanDocument9 pagesAssignment 2 State ArmanM.NadeemNo ratings yet
- Normal Distribution ExplainedDocument7 pagesNormal Distribution Explainedsunita45100% (1)
- Review Empirical Rule, Normality, Decision MakingDocument19 pagesReview Empirical Rule, Normality, Decision Makinglance WuNo ratings yet
- Interview MLDocument24 pagesInterview MLRitwik Gupta (RA1911003010405)No ratings yet
- Theoretical DistributionsDocument46 pagesTheoretical DistributionsNoopur ChauhanNo ratings yet
- Normal DistributionDocument25 pagesNormal DistributionMina BhattaNo ratings yet
- The Binomial Expansion The Binomial and Normal Distribution: ObjectivesDocument38 pagesThe Binomial Expansion The Binomial and Normal Distribution: ObjectivesRafJanuaBercasioNo ratings yet
- Analysis Interpretation and Use of Test DataDocument50 pagesAnalysis Interpretation and Use of Test DataJayson EsperanzaNo ratings yet
- PME-lec8-ch4-bDocument50 pagesPME-lec8-ch4-bnaba.jeeeNo ratings yet
- Statistical Concepts ExplainedDocument27 pagesStatistical Concepts ExplainedAqsa IjazNo ratings yet
- Chapter 3 Normal DistributionDocument21 pagesChapter 3 Normal DistributionChaman SidhuNo ratings yet
- Normal Distribution & CLTDocument3 pagesNormal Distribution & CLTAasim Bin BakrNo ratings yet
- Review: - Measures of Central Tendency - Measures of VariationDocument28 pagesReview: - Measures of Central Tendency - Measures of VariationEjazriazvirkNo ratings yet
- Inference For Numerical Data - Stats 250Document18 pagesInference For Numerical Data - Stats 250Oliver BarrNo ratings yet
- Assignment 9 Nomor 1Document2 pagesAssignment 9 Nomor 1Alexander Steven ThemasNo ratings yet
- 6.2 Confidence IntervalsDocument5 pages6.2 Confidence IntervalsentropyNo ratings yet
- SP-Q3 Note#5 Normal Random VariableDocument2 pagesSP-Q3 Note#5 Normal Random VariablePaulo Amposta CarpioNo ratings yet
- This is The Statistics Handbook your Professor Doesn't Want you to See. So Easy, it's Practically Cheating...From EverandThis is The Statistics Handbook your Professor Doesn't Want you to See. So Easy, it's Practically Cheating...Rating: 4.5 out of 5 stars4.5/5 (6)
- CortexM Registers 2Document27 pagesCortexM Registers 2Sai Mohnish MuralidharanNo ratings yet
- CortexM RegistersDocument12 pagesCortexM RegistersSai Mohnish MuralidharanNo ratings yet
- Session 9 - Thumb ModeDocument27 pagesSession 9 - Thumb ModeSai Mohnish MuralidharanNo ratings yet
- Session 10 - AMBA-busDocument35 pagesSession 10 - AMBA-busSai Mohnish MuralidharanNo ratings yet
- Research On Clock Synchronization Mechanism of Distributed Simulation System Based On DDSDocument6 pagesResearch On Clock Synchronization Mechanism of Distributed Simulation System Based On DDSSai Mohnish MuralidharanNo ratings yet
- 19CSE211 Endian IC Exec DetailsDocument29 pages19CSE211 Endian IC Exec DetailsSai Mohnish MuralidharanNo ratings yet
- Digital Image Processing Question Answer BankDocument69 pagesDigital Image Processing Question Answer Bankkarpagamkj759590% (72)
- Sampling and Sampling DistributionDocument48 pagesSampling and Sampling DistributionSai Mohnish MuralidharanNo ratings yet
- Curve Fitting Techniques for Interpolation and ApproximationDocument38 pagesCurve Fitting Techniques for Interpolation and ApproximationYash MangeNo ratings yet
- Error Correction ModelDocument37 pagesError Correction ModelRollins JohnNo ratings yet
- Recommended Books For RBI Grade B Exam With Bonus Online MaterialDocument15 pagesRecommended Books For RBI Grade B Exam With Bonus Online MaterialrahulNo ratings yet
- E 141 - 91 R03 - Rte0mqDocument6 pagesE 141 - 91 R03 - Rte0mqGiorgos SiorentasNo ratings yet
- Understanding the Bias-Variance Tradeoff in Machine Learning ModelsDocument11 pagesUnderstanding the Bias-Variance Tradeoff in Machine Learning ModelsBalaganesh NallathambiNo ratings yet
- POM - Assignment 2 - Nov 2015Document10 pagesPOM - Assignment 2 - Nov 2015Saima JafariNo ratings yet
- Tugas 2Document15 pagesTugas 2Ari JwNo ratings yet
- Skittles AssignmentDocument8 pagesSkittles Assignmentapi-291800396No ratings yet
- Emp Code First Name Last Name Department Region Branch SalaryDocument14 pagesEmp Code First Name Last Name Department Region Branch SalaryRASHI SETHI-IBNo ratings yet
- A Performance Comparison of Multi-Objective Optimization-BasedDocument13 pagesA Performance Comparison of Multi-Objective Optimization-Basedmeysam_gholampoorNo ratings yet
- Fires in Protected Areas Reveal Unforeseen Costs of Colombian PeaceDocument4 pagesFires in Protected Areas Reveal Unforeseen Costs of Colombian PeaceLa Silla VacíaNo ratings yet
- Imm5702 PDFDocument0 pagesImm5702 PDFLeandro MeiliNo ratings yet
- Econometric SDocument1,103 pagesEconometric SCesar MonterrosoNo ratings yet
- Economics 717 IV Lecture SummaryDocument30 pagesEconomics 717 IV Lecture SummaryHarrison NgNo ratings yet
- Non-linear equations steady-state solutionsDocument56 pagesNon-linear equations steady-state solutionsOayes MiddaNo ratings yet
- Refined Model of Maslow's Needs Theory in Internet EraDocument11 pagesRefined Model of Maslow's Needs Theory in Internet Era2PA06Indira Salsabila JastinNo ratings yet
- Elias Blue Journal 02Document26 pagesElias Blue Journal 02María Alejandra Zapata MendozaNo ratings yet
- Week 13 Tutorial - Sample Solutions - Chapter 14-MYLOVJune2020S1Document5 pagesWeek 13 Tutorial - Sample Solutions - Chapter 14-MYLOVJune2020S1maria akshathaNo ratings yet
- 2021 CFA LII MockExamB-AMDocument71 pages2021 CFA LII MockExamB-AMClareNo ratings yet
- Chapter 07 Functional Form ECO545Document26 pagesChapter 07 Functional Form ECO545Nur Adriana binti Abdul AzizNo ratings yet
- ECONOMICS SEM 4 Notes SakshiDocument10 pagesECONOMICS SEM 4 Notes SakshiSakshi MutturNo ratings yet
- SPSS Uber OutputDocument12 pagesSPSS Uber OutputMuhammad Towfiqul IslamNo ratings yet
- 06 03 Linear RegressionDocument13 pages06 03 Linear RegressionJohn Bofarull GuixNo ratings yet
- Problem IDocument10 pagesProblem Imgharba123No ratings yet
- An Empirical Analysis of Impulsive Buying BehaviorDocument12 pagesAn Empirical Analysis of Impulsive Buying BehaviorAnh Nguyễn ĐứcNo ratings yet
- Problems On Confidence IntervalDocument6 pagesProblems On Confidence Intervalrangoli maheshwariNo ratings yet
- TutorialDocument3 pagesTutorialSivanesh KumarNo ratings yet
- ECE 3040 Lecture 18: Curve Fitting by Least-Squares-Error RegressionDocument38 pagesECE 3040 Lecture 18: Curve Fitting by Least-Squares-Error RegressionKen ZhengNo ratings yet
- 3 Ways To Calculate The Sum of Squares For Error (SSE) - WikiHowDocument4 pages3 Ways To Calculate The Sum of Squares For Error (SSE) - WikiHowJuan CarNo ratings yet
- System: Thi Nhu Ngoc Truong, Chuang WangDocument10 pagesSystem: Thi Nhu Ngoc Truong, Chuang Wangthienphuc1996No ratings yet