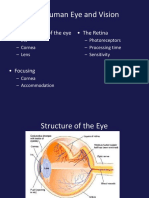
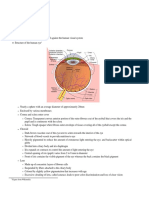
You might also like
- Visual Perception FlashcardsDocument12 pagesVisual Perception FlashcardsfewjkhvbjkhlckvsjdbNo ratings yet
- Syllabus For Organization, Administration and Supervision of Guidance ServicesDocument17 pagesSyllabus For Organization, Administration and Supervision of Guidance ServicesPearl Via Soliven Coballes100% (5)
- WISE Journal Volume 6, No. 1 (Spring, 2017)Document108 pagesWISE Journal Volume 6, No. 1 (Spring, 2017)Vas RaNo ratings yet
- Intro - To - Visual InspectionDocument63 pagesIntro - To - Visual InspectionNoman Saeed100% (1)
- Bridge Engineering by Christian MennDocument446 pagesBridge Engineering by Christian MennSandeep SonyNo ratings yet
- Visual SystemDocument37 pagesVisual Systemmalinda100% (1)
- My Personal SWOT Analysis For The Human Resource ManagerDocument1 pageMy Personal SWOT Analysis For The Human Resource Managerzahur27100% (2)
- Tesco Bank - No Claim Discount 28.11.17Document2 pagesTesco Bank - No Claim Discount 28.11.17eujenio50% (2)
- Chap2 Digital Image FundamentalDocument41 pagesChap2 Digital Image FundamentalTaosiful AkashNo ratings yet
- Lecture 2 Week 2 3 04032023 062027pmDocument39 pagesLecture 2 Week 2 3 04032023 062027pmmuhammad shamimNo ratings yet
- Digital Image Fundamentals - Machine VisionDocument62 pagesDigital Image Fundamentals - Machine VisionDr. Ajay M PatelNo ratings yet
- Lect 1 and 2Document100 pagesLect 1 and 2renmhNo ratings yet
- Module 1:image Representation and ModelingDocument48 pagesModule 1:image Representation and ModelingPaul JoyNo ratings yet
- ME2 Visual PerceptionDocument27 pagesME2 Visual Perceptiondharsana89No ratings yet
- Computer VisionDocument24 pagesComputer VisionMAJIDNo ratings yet
- Unit VI Image Formation and Display: by Ankita TidakeDocument87 pagesUnit VI Image Formation and Display: by Ankita TidakeAnkita BhoyarNo ratings yet
- On: Digital Image ProcessingDocument212 pagesOn: Digital Image Processingstutinmims23No ratings yet
- E A Visual PerceptionDocument59 pagesE A Visual PerceptionvenkygupthaNo ratings yet
- Dip-Ppt 1Document34 pagesDip-Ppt 1Ssd SsdNo ratings yet
- Module DV 1Document120 pagesModule DV 1battutharun04No ratings yet
- DIP ppt1Document156 pagesDIP ppt1Aby MottyNo ratings yet
- On: Digital Image ProcessingDocument212 pagesOn: Digital Image ProcessingSmita SangewarNo ratings yet
- What Is Digital Image?: Remember Digitization Implies That A Digital Image Is An Approximation of A RealDocument7 pagesWhat Is Digital Image?: Remember Digitization Implies That A Digital Image Is An Approximation of A RealBhagyesh ShahNo ratings yet
- SodaPDF-merged-Merging ResultDocument296 pagesSodaPDF-merged-Merging ResultShubham DhundaleNo ratings yet
- DIP Unit 1 (Intro, 2D - Sig+Sys, Convo, Transform)Document128 pagesDIP Unit 1 (Intro, 2D - Sig+Sys, Convo, Transform)Shubham DhundaleNo ratings yet
- Image Processing Image Processing: CSC CSC 447 447 Instructor: Dr. Shereen Aly Instructor: Dr. Shereen AlyDocument32 pagesImage Processing Image Processing: CSC CSC 447 447 Instructor: Dr. Shereen Aly Instructor: Dr. Shereen AlyyahiaNo ratings yet
- Data AnalyticsDocument83 pagesData AnalyticsKannan ThangaveluNo ratings yet
- Human EyeDocument78 pagesHuman Eyenandini bhalekarNo ratings yet
- Unit 1 Digital Image .Document74 pagesUnit 1 Digital Image .Prabhu ShibiNo ratings yet
- 2 Chapter5eyeDocument34 pages2 Chapter5eyeSanjeev KumarNo ratings yet
- 9 CSensory PhotoDocument37 pages9 CSensory PhotoLorsa HughesNo ratings yet
- Unit-I Introduction To Image ProcessingDocument23 pagesUnit-I Introduction To Image ProcessingSiva KumarNo ratings yet
- EE-333 Digital Image ProcessingDocument50 pagesEE-333 Digital Image Processingahad idcNo ratings yet
- Introduction To Light (Notes)Document7 pagesIntroduction To Light (Notes)Shivang GuptaNo ratings yet
- Lighting & Human PerformanceDocument15 pagesLighting & Human Performancepurged_160151093_920No ratings yet
- Chapter 5 MicrosDocument51 pagesChapter 5 MicrosNameNo ratings yet
- What Is Digital Image Processing?Document17 pagesWhat Is Digital Image Processing?loya suryaNo ratings yet
- Chapter 5 EyeDocument28 pagesChapter 5 EyeKoushik Roy SwtHrtNo ratings yet
- 3015 Week 1, 2Document18 pages3015 Week 1, 2Sajia Nowshin KhanNo ratings yet
- Introduction To Image File FormatsDocument87 pagesIntroduction To Image File FormatsRajeswari PurushothamNo ratings yet
- Machine VisionDocument18 pagesMachine VisionyokeshNo ratings yet
- Lec 2Document50 pagesLec 2Haisham AliNo ratings yet
- AVR Unit 1 Part 3Document25 pagesAVR Unit 1 Part 3Honey BeeNo ratings yet
- Lenses, Mirror Advance ResearchDocument15 pagesLenses, Mirror Advance ResearchShashank VermaNo ratings yet
- Fundamental in DIPDocument20 pagesFundamental in DIPnandini bhalekarNo ratings yet
- Convolution Neural NetworkDocument66 pagesConvolution Neural NetworkmohithNo ratings yet
- Cell Biology - Light and Electron Microscopes Lecture - Moodle VersionDocument20 pagesCell Biology - Light and Electron Microscopes Lecture - Moodle VersionBurning PhenomNo ratings yet
- EEE6218 Visual Information Processing (VIP) : Topic 01: Digital ImagingDocument71 pagesEEE6218 Visual Information Processing (VIP) : Topic 01: Digital ImagingdialauchennaNo ratings yet
- Light & Eyes: - Vision Begins When Light Comes Into The Eye - LightDocument31 pagesLight & Eyes: - Vision Begins When Light Comes Into The Eye - LightfouadNo ratings yet
- Lectures On Medical Biophysics: Biophysics of Visual PerceptionDocument45 pagesLectures On Medical Biophysics: Biophysics of Visual PerceptionalllexissssNo ratings yet
- Q.1 What Is A Digital Image Processing? Explain in Brief. and Origins of Digital Image ProcessingDocument7 pagesQ.1 What Is A Digital Image Processing? Explain in Brief. and Origins of Digital Image ProcessingSaurabhNo ratings yet
- Digital Image Processing Notes VtuDocument72 pagesDigital Image Processing Notes VtuNikhil KumarNo ratings yet
- Principles of Vision & Colour: Ir Dr. Sam C. M. HuiDocument60 pagesPrinciples of Vision & Colour: Ir Dr. Sam C. M. HuiSam C M HuiNo ratings yet
- SSTDocument2 pagesSSTkWaNgyANo ratings yet
- Resumen Semana 1 Clase de OftalmologiaDocument3 pagesResumen Semana 1 Clase de OftalmologiaIsis MartinezNo ratings yet
- Principles of Vision & Colour: Ir Dr. Sam C. M. HuiDocument60 pagesPrinciples of Vision & Colour: Ir Dr. Sam C. M. HuiSam C M HuiNo ratings yet
- OCT MaculaDocument71 pagesOCT MaculaNasrin sultana rmcNo ratings yet
- VisionDocument57 pagesVisionAynalemNo ratings yet
- Explain About Elements of Visual PerceptionDocument8 pagesExplain About Elements of Visual PerceptionYagneshNo ratings yet
- Psyc 374: Biological Psychology: Vision Instructor: Gözde Özsarfati Spring 2020-2021Document62 pagesPsyc 374: Biological Psychology: Vision Instructor: Gözde Özsarfati Spring 2020-2021Sena MutluNo ratings yet
- Human Eye and Colourful World2Document18 pagesHuman Eye and Colourful World2Kamesh RajputNo ratings yet
- 9 Sensory Organs - Eye and EarDocument41 pages9 Sensory Organs - Eye and Earbabaaijaz01No ratings yet
- Dip NotesDocument57 pagesDip Noteskv6282909No ratings yet
- The Visual Elements—Photography: A Handbook for Communicating Science and EngineeringFrom EverandThe Visual Elements—Photography: A Handbook for Communicating Science and EngineeringNo ratings yet
- Computer Stereo Vision: Exploring Depth Perception in Computer VisionFrom EverandComputer Stereo Vision: Exploring Depth Perception in Computer VisionNo ratings yet
- obeject orineted questio part oneDocument14 pagesobeject orineted questio part oneNatanem YimerNo ratings yet
- OOP Features five - CopyDocument4 pagesOOP Features five - CopyNatanem YimerNo ratings yet
- CH 3Document29 pagesCH 3Natanem YimerNo ratings yet
- obeject orineted questio part oneDocument14 pagesobeject orineted questio part oneNatanem YimerNo ratings yet
- This set of Object Oriented Programming Abstraction - CopyDocument4 pagesThis set of Object Oriented Programming Abstraction - CopyNatanem YimerNo ratings yet
- Computer Science Quizzes - EbookDocument2 pagesComputer Science Quizzes - EbookNatanem YimerNo ratings yet
- Computer Science Quiz - Ebook1Document2 pagesComputer Science Quiz - Ebook1Natanem YimerNo ratings yet
- 134520081906Document8 pages134520081906Natanem YimerNo ratings yet
- Chapter 2Document25 pagesChapter 2Natanem YimerNo ratings yet
- Assignment Applied I For Computer ScienceDocument1 pageAssignment Applied I For Computer ScienceNatanem YimerNo ratings yet
- Mo 2019Document21 pagesMo 2019Natanem YimerNo ratings yet
- FOR BOOK STORE (Autosaved)Document6 pagesFOR BOOK STORE (Autosaved)Natanem YimerNo ratings yet
- GenralDocument26 pagesGenralNatanem YimerNo ratings yet
- Super Shop Website - For MergeDocument77 pagesSuper Shop Website - For MergeNatanem YimerNo ratings yet
- Healthmedicinet I 2017 2Document598 pagesHealthmedicinet I 2017 2tuni santeNo ratings yet
- Ghid Redactare Teza de DoctoratDocument189 pagesGhid Redactare Teza de DoctoratAlexandru VladNo ratings yet
- Chapter 8Document38 pagesChapter 8kavitasuren100% (3)
- Shivam 5555@yahoo Dotco DotinDocument3 pagesShivam 5555@yahoo Dotco DotinsupriyaNo ratings yet
- Letter of Recommendation: Graduate Admissions OfficeDocument2 pagesLetter of Recommendation: Graduate Admissions OfficeChedeng KumaNo ratings yet
- FirewallDocument12 pagesFirewallHarpreetNo ratings yet
- Dynamic Performance Analysis of Permanent Magnet Hybrid Stepper Motor by Transfer Function Model For Different Design TopologiesDocument7 pagesDynamic Performance Analysis of Permanent Magnet Hybrid Stepper Motor by Transfer Function Model For Different Design TopologiesEEEENo ratings yet
- Wande Coal - Mushin 2 Mo HitsDocument3 pagesWande Coal - Mushin 2 Mo HitsOye Akideinde100% (2)
- Literature Component Captain Nobody English SPM PDFDocument11 pagesLiterature Component Captain Nobody English SPM PDFmeshal retteryNo ratings yet
- Saarrthi Sovereign Pune - 0Document1 pageSaarrthi Sovereign Pune - 0rajat charayaNo ratings yet
- The Seventh Spark Knights of The TrinityDocument57 pagesThe Seventh Spark Knights of The TrinityNetNo ratings yet
- Chapter1 - Transient Analysis in Time DomainDocument72 pagesChapter1 - Transient Analysis in Time DomainTrần Anh KhoaNo ratings yet
- News Letter Philips Sod87 (200912)Document2 pagesNews Letter Philips Sod87 (200912)sole_zemunNo ratings yet
- Icao Manual of Civil Medicine 8984 - Cons - enDocument580 pagesIcao Manual of Civil Medicine 8984 - Cons - enSankr SankrNo ratings yet
- TLE G9 Q2 Module 1 Beauty Care - Nail Care NCII Foot Spa Tools and EquipmentDocument14 pagesTLE G9 Q2 Module 1 Beauty Care - Nail Care NCII Foot Spa Tools and EquipmentmelindacchavezNo ratings yet
- Ind. Eng. Chem. Prod. Res. Dev. Vol. 18 - No. 2 - 1979 135Document8 pagesInd. Eng. Chem. Prod. Res. Dev. Vol. 18 - No. 2 - 1979 135Lindsey BondNo ratings yet
- The Real Business Cycle Model: Quantitative MacroeconomicsDocument36 pagesThe Real Business Cycle Model: Quantitative MacroeconomicsAmil MusovicNo ratings yet
- Cat. 6 4x2x267 AWG SFTP Work Area PVC - 9828026107 - V - 1 - R - 2Document2 pagesCat. 6 4x2x267 AWG SFTP Work Area PVC - 9828026107 - V - 1 - R - 2Inɡ Elvis RodríguezNo ratings yet
- Cell FlexDocument2 pagesCell Flexandrewb2005No ratings yet
- Sbo43sp2 Whats New enDocument14 pagesSbo43sp2 Whats New enPierreNo ratings yet
- Difference Between OSI and TCPIP ModelsDocument2 pagesDifference Between OSI and TCPIP ModelsSami khan orakzai83% (6)
- Sheet Metal Nesting Report For Plasma and Laser CuttingDocument1 pageSheet Metal Nesting Report For Plasma and Laser CuttingcititorulturmentatNo ratings yet
- JD - Chief Manager Recon and ARDocument4 pagesJD - Chief Manager Recon and ARVineet SharmaNo ratings yet
- Determine The Equivalent Spring Constant of SystemDocument8 pagesDetermine The Equivalent Spring Constant of SystemKornwipa MongkonkehaNo ratings yet
- Pathfit 3 Module Chapter 2Document18 pagesPathfit 3 Module Chapter 2Marc BorcilloNo ratings yet