You might also like
- Cobas 6800 - 8800 - Host Interface Manual1 - 4Document204 pagesCobas 6800 - 8800 - Host Interface Manual1 - 4박수희No ratings yet
- XS-1000 Automated Hematology Analyzer: Small Footprint. Big DifferenceDocument4 pagesXS-1000 Automated Hematology Analyzer: Small Footprint. Big Differencerizal_aspanNo ratings yet
- Ashton Yeo - Siemens Healthineers Blood Gas - Providing End-To-End Blood Gas Testing SolutionsDocument33 pagesAshton Yeo - Siemens Healthineers Blood Gas - Providing End-To-End Blood Gas Testing SolutionsullifannuriNo ratings yet
- AU680/AU480 Online SpecificationsDocument55 pagesAU680/AU480 Online SpecificationsSilvio Luiz SalotiNo ratings yet
- Randoxintl8 PDFDocument23 pagesRandoxintl8 PDFdatitoxNo ratings yet
- Acl 6000-7000Document39 pagesAcl 6000-7000Orelvi SantosNo ratings yet
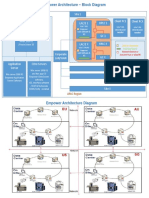
- Empower ArchitectureDocument2 pagesEmpower ArchitecturePinaki ChakrabortyNo ratings yet
- Helena Catalogue EpDocument19 pagesHelena Catalogue EpfelixNo ratings yet
- Vitros x600 LIS Training: Hardware, Software, Testing & Troubleshooting BasicsDocument47 pagesVitros x600 LIS Training: Hardware, Software, Testing & Troubleshooting BasicsRavi ShravgirNo ratings yet
- Cobas Liat User Manual SW 3 2Document196 pagesCobas Liat User Manual SW 3 2Revathy Gunaseelan100% (1)
- Automated Hematology Analyzer XN-L Series ASTM Host Interface SpecificationsDocument78 pagesAutomated Hematology Analyzer XN-L Series ASTM Host Interface SpecificationsSowji P0% (1)
- Capillarys 3 TERA - Service Manual (v1.15P1!22!03-2019)Document120 pagesCapillarys 3 TERA - Service Manual (v1.15P1!22!03-2019)AliNo ratings yet
- Laboratory Execution System Les BrochureDocument4 pagesLaboratory Execution System Les BrochureChRiZtIaN16No ratings yet
- Sample Collection and StorageDocument18 pagesSample Collection and StorageZeeshan YousufNo ratings yet
- LIMS For Lasers 2015 User ManualDocument188 pagesLIMS For Lasers 2015 User Manualcharles_0814No ratings yet
- Set Up FilmArray Torch LIS FTPDocument4 pagesSet Up FilmArray Torch LIS FTPAxel GrullonNo ratings yet
- AU5800 Online Specification For Version 5.0 or LaterDocument61 pagesAU5800 Online Specification For Version 5.0 or LaterRubi Kauneus MørkeNo ratings yet
- UniCel DxI and Access 2 Systems LIS Vendor InformationDocument64 pagesUniCel DxI and Access 2 Systems LIS Vendor Information朱三郎No ratings yet
- Cobas 8000 BrochureDocument20 pagesCobas 8000 BrochureRadu Badoiu100% (1)
- Sop On Lis On Ecl 105 - 412Document8 pagesSop On Lis On Ecl 105 - 412Tejas HankareNo ratings yet
- LIS POCcelerator SetupDocument6 pagesLIS POCcelerator SetupJohnny Tello100% (1)
- E 411 Host Interface ManualDocument142 pagesE 411 Host Interface Manualxeon1976No ratings yet
- Service LIS2-ADocument11 pagesService LIS2-ASmart BiomedicalNo ratings yet
- Sysmex CS 5100Document4 pagesSysmex CS 5100Katamba RogersNo ratings yet
- Smart Lab E BookDocument24 pagesSmart Lab E BookNaveed MubarikNo ratings yet
- 638 DXH 520 Hematology Analyzer Brochure BR 66953 en GLB A4Document12 pages638 DXH 520 Hematology Analyzer Brochure BR 66953 en GLB A4Madness InvokerNo ratings yet
- Tosoh Bio Science - G8 ChromatogramsDocument1 pageTosoh Bio Science - G8 ChromatogramsimrecoNo ratings yet
- Cobas C 311 Brochure Int AgenciesDocument12 pagesCobas C 311 Brochure Int AgenciesadelNo ratings yet
- Lis Vendor Interface - L-005933-Document-Rev-2017Document125 pagesLis Vendor Interface - L-005933-Document-Rev-2017jorgeNo ratings yet
- RS-100457-EBS - Labware Integration PDFDocument20 pagesRS-100457-EBS - Labware Integration PDFkrishnandhanapalNo ratings yet
- OG Operator Guide Advia 2120iDocument470 pagesOG Operator Guide Advia 2120iEstie Kiriwenno100% (1)
- Acl Top Family Brochure - 2.1.2012 - FinalDocument8 pagesAcl Top Family Brochure - 2.1.2012 - Finalpieterinpretoria391No ratings yet
- RocheCobasC111Host Interface Manual - 2.1 - EN - 2 PDFDocument93 pagesRocheCobasC111Host Interface Manual - 2.1 - EN - 2 PDFxeon1976No ratings yet
- Celldyn Emerald-Interface E22ALDocument36 pagesCelldyn Emerald-Interface E22ALgustavodlr100% (1)
- 510703-7EN1 BCI SpecificationsDocument124 pages510703-7EN1 BCI SpecificationsJose VarelaNo ratings yet
- XN-3000 Ifu Na (1211)Document460 pagesXN-3000 Ifu Na (1211)CARLOSNo ratings yet
- RP500 Interfaz LISDocument14 pagesRP500 Interfaz LISJavier Andres leon HigueraNo ratings yet
- 19 - User Roles and Privileges in LC-MS (Labsolutions)Document11 pages19 - User Roles and Privileges in LC-MS (Labsolutions)Dayanidhi dayaNo ratings yet
- IQ200 Family Protocol 300-4941JBDocument90 pagesIQ200 Family Protocol 300-4941JBADI SUSENO100% (1)
- G1969 90006 TOF Maintenance v4Document150 pagesG1969 90006 TOF Maintenance v4Jeramiah SpencerNo ratings yet
- SampleManager Web Client Installation and Configuration GuideDocument24 pagesSampleManager Web Client Installation and Configuration GuideLuis Muchaki100% (1)
- 80000456-102 Alinity ASTM LIS InterfaceDocument76 pages80000456-102 Alinity ASTM LIS InterfacemirceaNo ratings yet
- Astm enDocument10 pagesAstm enkartopolloNo ratings yet
- ADVIA Centaur XPT Brochure - 144375171Document8 pagesADVIA Centaur XPT Brochure - 144375171AlvinNo ratings yet
- Siemens Immulite 1000 LISManual - ADocument107 pagesSiemens Immulite 1000 LISManual - AKinnari BhattNo ratings yet
- Predictive Maintenance - Reduce CostDocument9 pagesPredictive Maintenance - Reduce Costsieged_rj3165No ratings yet
- LIS - Abbott Architect-90937-105Document108 pagesLIS - Abbott Architect-90937-105jyoti ranjan100% (1)
- GEN EXPERT Module-09troubleshootingDocument46 pagesGEN EXPERT Module-09troubleshootingtha_ansNo ratings yet
- Interface g7Document25 pagesInterface g7Jose VarelaNo ratings yet
- Product Support and Service Plan - IMMULITE 2000 XPiDocument13 pagesProduct Support and Service Plan - IMMULITE 2000 XPiОлександрNo ratings yet
- Labmate Lims Erp Product IntroductionDocument45 pagesLabmate Lims Erp Product IntroductionN. K. MandilNo ratings yet
- CA1500 IFU en S00 02 0310Document98 pagesCA1500 IFU en S00 02 0310saminakiianiNo ratings yet
- Skyway LIMS OverviewDocument52 pagesSkyway LIMS OverviewSFC ABHA 1No ratings yet
- Automated Packaging Systems Autolabel Pi-4000 In-Line, Programmable, Thermal Transfer PrinterDocument2 pagesAutomated Packaging Systems Autolabel Pi-4000 In-Line, Programmable, Thermal Transfer PrinterEdgar HoowerNo ratings yet
- AU Series 25 - LIS - COM - LAN - AU - NewDocument108 pagesAU Series 25 - LIS - COM - LAN - AU - NewBereket TeketelNo ratings yet
- Tecan Genesis FE500 Interface Reference GuideDocument16 pagesTecan Genesis FE500 Interface Reference GuideChris BradleyNo ratings yet
- AU Chemistry Quick Reference Guide (OUS) MUL A4 CT 48004 enDocument76 pagesAU Chemistry Quick Reference Guide (OUS) MUL A4 CT 48004 enIsmail Alami Marrouni100% (1)
- Urinalysis Workarea Information Management System U-WAM ASTM Host Online Specifications Revision 18Document149 pagesUrinalysis Workarea Information Management System U-WAM ASTM Host Online Specifications Revision 18ОлександрNo ratings yet
- Prism - Composite Application Guidance: ©2010 Brian Noyes, Idesign Inc. All Rights ReservedDocument12 pagesPrism - Composite Application Guidance: ©2010 Brian Noyes, Idesign Inc. All Rights ReservedhillyrbNo ratings yet
- Indian History PDFDocument42 pagesIndian History PDFRaovarinder SinghNo ratings yet
- CancerDocument18 pagesCancerAtul SharmaNo ratings yet
- CancerDocument18 pagesCancerAtul SharmaNo ratings yet
- Banking Awareness Question PDFDocument122 pagesBanking Awareness Question PDFSelvaraj VillyNo ratings yet
- Probe Labeling1Document24 pagesProbe Labeling1Atul SharmaNo ratings yet
- Tissue EngineeringDocument15 pagesTissue Engineeringbogdan6No ratings yet
- Macro LabDocument208 pagesMacro LabAtmira Nurandarini Utomo100% (2)
- Syllabus For Biotechnology (BT) : Linear AlgebraDocument3 pagesSyllabus For Biotechnology (BT) : Linear AlgebraSuresh ChaluvadiNo ratings yet
- Lab Manual 2008Document50 pagesLab Manual 2008Atul SharmaNo ratings yet
- Hemocytometer: Navigation Search Improve This Article Reliable Sources Challenged RemovedDocument3 pagesHemocytometer: Navigation Search Improve This Article Reliable Sources Challenged RemovedGaurav DarochNo ratings yet
- Plant TransformationDocument22 pagesPlant TransformationAtul SharmaNo ratings yet
- Probe Labeling1Document24 pagesProbe Labeling1Atul SharmaNo ratings yet
- Maths - Prof TestDocument20 pagesMaths - Prof TestAnonymous rePT5rCrNo ratings yet
- Types of Media For MicrobiologyDocument2 pagesTypes of Media For MicrobiologyThulasi Devadoss100% (1)
- Tangent GalvanometerDocument5 pagesTangent GalvanometerAtul SharmaNo ratings yet
- Tangent GalvanometerDocument5 pagesTangent GalvanometerAtul SharmaNo ratings yet
- Haemophillus InfluenzaeDocument6 pagesHaemophillus InfluenzaeAtul SharmaNo ratings yet
- XXCCCDocument17 pagesXXCCCwendra adi pradanaNo ratings yet
- Why Islam Is The True Religion in Light of The Quran and SunnahDocument7 pagesWhy Islam Is The True Religion in Light of The Quran and SunnahAsmau DaboNo ratings yet
- AWS Cloud Practicioner Exam Examples 0Document110 pagesAWS Cloud Practicioner Exam Examples 0AnataTumonglo100% (3)
- Oracle Unified Method (OUM) White Paper - Oracle's Full Lifecycle Method For Deploying Oracle-Based Business Solutions - GeneralDocument17 pagesOracle Unified Method (OUM) White Paper - Oracle's Full Lifecycle Method For Deploying Oracle-Based Business Solutions - GeneralAndreea Mirosnicencu100% (1)
- InteliLite AMF20-25Document2 pagesInteliLite AMF20-25albertooliveira100% (2)
- Advanced Presentation Skills: Creating Effective Presentations with Visuals, Simplicity and ClarityDocument15 pagesAdvanced Presentation Skills: Creating Effective Presentations with Visuals, Simplicity and ClarityGilbert TamayoNo ratings yet
- CBT QuestionsDocument20 pagesCBT Questionsmohammed amjad ali100% (1)
- Astm D 664 - 07Document8 pagesAstm D 664 - 07Alfonso MartínezNo ratings yet
- Decembermagazine 2009Document20 pagesDecembermagazine 2009maria_diyah4312No ratings yet
- Sonigra Manav Report Finle-Converted EDITEDDocument50 pagesSonigra Manav Report Finle-Converted EDITEDDABHI PARTHNo ratings yet
- Lineapelle: Leather & Non-LeatherDocument16 pagesLineapelle: Leather & Non-LeatherShikha BhartiNo ratings yet
- Victor Mejia ResumeDocument1 pageVictor Mejia Resumeapi-510300922No ratings yet
- Siga-Cc1 12-22-2010Document6 pagesSiga-Cc1 12-22-2010Felipe LozanoNo ratings yet
- District Wise List of Colleges Under The Juridiction of MRSPTU BathindaDocument13 pagesDistrict Wise List of Colleges Under The Juridiction of MRSPTU BathindaGurpreet SandhuNo ratings yet
- Understanding 2006 PSAT-NMSQT ScoresDocument8 pagesUnderstanding 2006 PSAT-NMSQT ScorestacobeoNo ratings yet
- Google Search StringsDocument12 pagesGoogle Search StringsPrashant Sawnani100% (1)
- LogDocument119 pagesLogcild MonintjaNo ratings yet
- Week 1 Gec 106Document16 pagesWeek 1 Gec 106Junjie FuentesNo ratings yet
- Virtio-Fs - A Shared File System For Virtual MachinesDocument21 pagesVirtio-Fs - A Shared File System For Virtual MachinesLeseldelaterreNo ratings yet
- Travis Walton Part 1 MUFON Case FileDocument346 pagesTravis Walton Part 1 MUFON Case FileClaudio Silva100% (1)
- AIOUDocument2 pagesAIOUHoorabwaseemNo ratings yet
- Technical Description: BoilerDocument151 pagesTechnical Description: BoilerÍcaro VianaNo ratings yet
- EST I - Literacy Test I (Language)Document20 pagesEST I - Literacy Test I (Language)Mohammed Abdallah100% (1)
- Vincent Ira B. Perez: Barangay Gulod, Calatagan, BatangasDocument3 pagesVincent Ira B. Perez: Barangay Gulod, Calatagan, BatangasJohn Ramsel Boter IINo ratings yet
- Characteristics and Guidelines of PublicspaceDocument3 pagesCharacteristics and Guidelines of PublicspaceJanani SurenderNo ratings yet
- Types of Speech StylesDocument31 pagesTypes of Speech StylesRomnick BistayanNo ratings yet
- How Do I Prepare For Public Administration For IAS by Myself Without Any Coaching? Which Books Should I Follow?Document3 pagesHow Do I Prepare For Public Administration For IAS by Myself Without Any Coaching? Which Books Should I Follow?saiviswanath0990100% (1)
- ACL GRC Risk Manager - Usage Guide V1.1Document28 pagesACL GRC Risk Manager - Usage Guide V1.1Rohit ShettyNo ratings yet
- Moon Fast Schedule 2024Document1 pageMoon Fast Schedule 2024mimiemendoza18No ratings yet
- Managing Post COVID SyndromeDocument4 pagesManaging Post COVID SyndromeReddy VaniNo ratings yet