You might also like
- 032 Measures of PositionDocument13 pages032 Measures of PositionAndy WilliamNo ratings yet
- Measures Dispersion 40Document7 pagesMeasures Dispersion 40Paul SuicoNo ratings yet
- CEMath 2 Lec 4Document22 pagesCEMath 2 Lec 4Chrizkringle Dane Pauline YacapinNo ratings yet
- F) D X A D FD 000' FD: Mean, Since Assumed Mean (Baseline Average) 27,000 Therefore MeanDocument5 pagesF) D X A D FD 000' FD: Mean, Since Assumed Mean (Baseline Average) 27,000 Therefore MeanAlinaitwe GodfNo ratings yet
- Statistic Sample Question IiswbmDocument15 pagesStatistic Sample Question IiswbmMudasarSNo ratings yet
- Measures of Variation StatisticsDocument23 pagesMeasures of Variation StatisticsUpasana Abhishek GuptaNo ratings yet
- Discriptive StatisticsDocument50 pagesDiscriptive StatisticsSwathi JanardhanNo ratings yet
- Numerical Descriptive MeasuresDocument52 pagesNumerical Descriptive MeasureschanlalNo ratings yet
- Measures of Position (Intro-Quartiles)Document17 pagesMeasures of Position (Intro-Quartiles)n3ilkNo ratings yet
- Measure of DispersionDocument25 pagesMeasure of DispersionDan Frederico Pimentel AbaccoNo ratings yet
- Quartile & DeviationDocument31 pagesQuartile & DeviationM Pavan KumarNo ratings yet
- Quartile & DeviationDocument31 pagesQuartile & DeviationM Pavan KumarNo ratings yet
- ANOVA Unit3 BBA504ADocument9 pagesANOVA Unit3 BBA504ADr. Meghdoot GhoshNo ratings yet
- ppt3 Descriptive2Document39 pagesppt3 Descriptive2mark perezNo ratings yet
- Descriptive StatsDocument51 pagesDescriptive StatsElena PinkaNo ratings yet
- ECON1203 PASS Week 3Document4 pagesECON1203 PASS Week 3mothermonkNo ratings yet
- Measures of Central Tendency and Other Positional MeasuresDocument13 pagesMeasures of Central Tendency and Other Positional Measuresbv123bvNo ratings yet
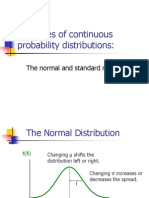
- Examples of Continuous Probability Distributions:: The Normal and Standard NormalDocument57 pagesExamples of Continuous Probability Distributions:: The Normal and Standard NormalPawan JajuNo ratings yet
- Measure Location and Position with FractilesDocument26 pagesMeasure Location and Position with FractilesjowieNo ratings yet
- Data Analysis: Kulwant Singh KapoorDocument60 pagesData Analysis: Kulwant Singh KapoorTripty Khanna KarwalNo ratings yet
- ECON1203/ECON2292 Business and Economic Statistics: Week 2Document10 pagesECON1203/ECON2292 Business and Economic Statistics: Week 2Jason PanNo ratings yet
- Business Statistics Syllabus BreakdownDocument17 pagesBusiness Statistics Syllabus BreakdownKhushbu AroraNo ratings yet
- Week 3 Parameters of A Frequency DistributionDocument36 pagesWeek 3 Parameters of A Frequency DistributionJuliana Alexis MalabadNo ratings yet
- Continuous Probability Distributions and the Normal CurveDocument57 pagesContinuous Probability Distributions and the Normal CurveAkshay VetalNo ratings yet
- Describing Distributions with NumbersDocument16 pagesDescribing Distributions with NumbersZobi NarNo ratings yet
- MCT-Median: Def - Variable Value Which Divides The Total Ordered Observations Into Equal Halves, 50% ObservationsDocument25 pagesMCT-Median: Def - Variable Value Which Divides The Total Ordered Observations Into Equal Halves, 50% Observationsharherron123No ratings yet
- Decsci Reviewer CHAPTER 1: Statistics and DataDocument7 pagesDecsci Reviewer CHAPTER 1: Statistics and DataGabriel Ian ZamoraNo ratings yet
- Statistics and Standard DeviationDocument50 pagesStatistics and Standard DeviationRon April Custodio Frias100% (10)
- Descriptive Statistics (Central Tendency)Document33 pagesDescriptive Statistics (Central Tendency)ZC47No ratings yet
- Measusres of LocationsDocument52 pagesMeasusres of LocationsSubashDahalNo ratings yet
- 10 STAT Per Comb ProbDocument34 pages10 STAT Per Comb ProbMonic RomeroNo ratings yet
- TA5 SolDocument3 pagesTA5 SolReyansh SharmaNo ratings yet
- An Introduction To Statistics: Keone HonDocument14 pagesAn Introduction To Statistics: Keone HonArjhay GironellaNo ratings yet
- EFM 515 Stats Lecture NotesDocument104 pagesEFM 515 Stats Lecture NotesKuda Keith MavhungaNo ratings yet
- ch7 Statistics NotesDocument44 pagesch7 Statistics Notesdukefvr41No ratings yet
- Data Organization and Presentation-1Document30 pagesData Organization and Presentation-1MA. CRISTINA DUPAGANNo ratings yet
- Measures of Dispersion TendencyDocument7 pagesMeasures of Dispersion Tendencyashraf helmyNo ratings yet
- 2 Mean Median Mode VarianceDocument29 pages2 Mean Median Mode VarianceBonita Mdoda-ArmstrongNo ratings yet
- Measures of Dispersion - Docx4.18.23Document3 pagesMeasures of Dispersion - Docx4.18.23Jericho TumazarNo ratings yet
- Business StatisticsDocument16 pagesBusiness StatisticssmilesamNo ratings yet
- Handout - Measures of Central Tendencyt - GroupedDocument5 pagesHandout - Measures of Central Tendencyt - GroupedSyElfredGNo ratings yet
- Calculate quartiles using SAS, Minitab, ExcelDocument13 pagesCalculate quartiles using SAS, Minitab, ExcelHenry TeepohNo ratings yet
- Basic 1Document60 pagesBasic 1Rajesh DwivediNo ratings yet
- Basic StatisticsDocument31 pagesBasic StatisticsStudyLaw pendialaNo ratings yet
- Intro to Basic Statistics ConceptsDocument27 pagesIntro to Basic Statistics ConceptsBliss ManNo ratings yet
- 5-MEASURES of DISPERSION-02-Aug-2019Material I 02-Aug-2019 Exp. No. 1 - Measures of Central Tendency Dispersion Skewness and KurtosiDocument10 pages5-MEASURES of DISPERSION-02-Aug-2019Material I 02-Aug-2019 Exp. No. 1 - Measures of Central Tendency Dispersion Skewness and Kurtosisahale sheraNo ratings yet
- Statistical Concepts BasicsDocument17 pagesStatistical Concepts BasicsVeeresha YrNo ratings yet
- Measures of DispersionDocument79 pagesMeasures of DispersionfeminaNo ratings yet
- Examples of Continuous Probability Distributions:: The Normal and Standard NormalDocument57 pagesExamples of Continuous Probability Distributions:: The Normal and Standard NormalkethavarapuramjiNo ratings yet
- Elementary StatisticsDocument73 pagesElementary StatisticsDeepak GoyalNo ratings yet
- Ed105 ADocument14 pagesEd105 Aapi-268563289No ratings yet
- IISER BiostatDocument87 pagesIISER BiostatPrithibi Bodle GacheNo ratings yet
- FormulasDocument11 pagesFormulasPhạm Ngọc Thanh ThuỳNo ratings yet
- Final Module in Assessment 1Document23 pagesFinal Module in Assessment 1Sheena LiagaoNo ratings yet
- Measure of Position For Ingrouped DataDocument19 pagesMeasure of Position For Ingrouped DataRavie Acuna DiongsonNo ratings yet
- GCSE Maths Revision: Cheeky Revision ShortcutsFrom EverandGCSE Maths Revision: Cheeky Revision ShortcutsRating: 3.5 out of 5 stars3.5/5 (2)
- Applications of Derivatives Errors and Approximation (Calculus) Mathematics Question BankFrom EverandApplications of Derivatives Errors and Approximation (Calculus) Mathematics Question BankNo ratings yet
- Learn Statistics Fast: A Simplified Detailed Version for StudentsFrom EverandLearn Statistics Fast: A Simplified Detailed Version for StudentsNo ratings yet
- AD 251 - Equivalent Uniform Moment Factor, M (Italic)Document1 pageAD 251 - Equivalent Uniform Moment Factor, M (Italic)symon ellimacNo ratings yet
- CA-Endevor Quick EditDocument31 pagesCA-Endevor Quick Editmariela mmascelloniNo ratings yet
- Sight Reduction Tables For Marine Navigation: B, R - D, D. SDocument12 pagesSight Reduction Tables For Marine Navigation: B, R - D, D. SGeani MihaiNo ratings yet
- Measures of CentralityDocument13 pagesMeasures of CentralityPRAGASM PROGNo ratings yet
- Product Manual 82434 (Revision C) : Generator Loading ControlDocument26 pagesProduct Manual 82434 (Revision C) : Generator Loading ControlAUGUSTA WIBI ARDIKTANo ratings yet
- Current Developments in Testing Item Response Theory (IRT) : Prepared byDocument32 pagesCurrent Developments in Testing Item Response Theory (IRT) : Prepared byMalar VengadesNo ratings yet
- 740 (Q50, V40, Awa 4Document10 pages740 (Q50, V40, Awa 4rawat2583No ratings yet
- Intraoperative Nursing Care GuideDocument12 pagesIntraoperative Nursing Care GuideDarlyn AmplayoNo ratings yet
- Figures of Speech ExplainedDocument5 pagesFigures of Speech ExplainedDarenJayBalboa100% (1)
- English For Academic Purposes (EAP) : Lecture 5: Past SimpleDocument11 pagesEnglish For Academic Purposes (EAP) : Lecture 5: Past Simplealmastar officeNo ratings yet
- Rethinking Classification and Localization For Object DetectionDocument13 pagesRethinking Classification and Localization For Object DetectionShah Nawaz KhanNo ratings yet
- PPC2000 Association of Consultant Architects Standard Form of Project Partnering ContractDocument5 pagesPPC2000 Association of Consultant Architects Standard Form of Project Partnering ContractJoy CeeNo ratings yet
- 7 Tools for Continuous ImprovementDocument202 pages7 Tools for Continuous Improvementvivekanand bhartiNo ratings yet
- Kanavos Pharmaceutical Distribution Chain 2007 PDFDocument121 pagesKanavos Pharmaceutical Distribution Chain 2007 PDFJoao N Da SilvaNo ratings yet
- My Son The Fanatic, Short StoryDocument4 pagesMy Son The Fanatic, Short StoryScribdAddict100% (2)
- Ceeshsworkingstudents Abm Group2Document18 pagesCeeshsworkingstudents Abm Group2kzz9c5hqrwNo ratings yet
- 1 - Gear Seminar ManualDocument125 pages1 - Gear Seminar Manualgustool7100% (1)
- Administrations whose CoCs are accepted for CECDocument1 pageAdministrations whose CoCs are accepted for CECGonçalo CruzeiroNo ratings yet
- Health Optimizing Physical Education: Learning Activity Sheet (LAS) Quarter 4Document7 pagesHealth Optimizing Physical Education: Learning Activity Sheet (LAS) Quarter 4John Wilfred PegranNo ratings yet
- S4 - SD - HOTS in Practice - EnglishDocument65 pagesS4 - SD - HOTS in Practice - EnglishIries DanoNo ratings yet
- Pmls 1 Final Exam Reviewer: Clinical Chemistry ContDocument14 pagesPmls 1 Final Exam Reviewer: Clinical Chemistry ContPlant in a PotNo ratings yet
- Lab Report AcetaminophenDocument5 pagesLab Report Acetaminophenapi-487596846No ratings yet
- Prodelin 1385Document33 pagesProdelin 1385bebebrenda100% (1)
- Recent Developments in Ultrasonic NDT Modelling in CIVADocument7 pagesRecent Developments in Ultrasonic NDT Modelling in CIVAcal2_uniNo ratings yet
- Statement Bank MBBDocument11 pagesStatement Bank MBBminyak bidara01No ratings yet
- Asian Studies For Filipinos The Philippines in The Asian CenturyDocument15 pagesAsian Studies For Filipinos The Philippines in The Asian CenturyGlaizza QuintonNo ratings yet
- Assignment of A Glass Transition Temperature Using Thermomechanical Analysis: Tension MethodDocument4 pagesAssignment of A Glass Transition Temperature Using Thermomechanical Analysis: Tension MethodEric GozzerNo ratings yet
- Youre The Inspiration CRDDocument3 pagesYoure The Inspiration CRDjonjammyNo ratings yet
- OM - Rieter - UNIMix A76Document321 pagesOM - Rieter - UNIMix A76Phineas FerbNo ratings yet
- Elective Course (2) - Composite Materials MET 443Document16 pagesElective Course (2) - Composite Materials MET 443يوسف عادل حسانينNo ratings yet