You might also like
- Factor Analysis T. RamayahDocument29 pagesFactor Analysis T. RamayahAmir AlazhariyNo ratings yet
- Consumer Behavior Towards Ayurvedic ProductsDocument5 pagesConsumer Behavior Towards Ayurvedic ProductsVikrant AryaNo ratings yet
- Capital Structure and Firm Size On Firm Value Moderated by ProfitabilityDocument18 pagesCapital Structure and Firm Size On Firm Value Moderated by Profitabilityrahmat fajarNo ratings yet
- Evolution of Banking SectorDocument16 pagesEvolution of Banking SectorNaishrati SoniNo ratings yet
- On Organistaion BehaviourDocument31 pagesOn Organistaion Behaviourvanishachhabra5008100% (1)
- Presented by Group 18: Neha Srivastava Sneha Shivam Garg TarunaDocument41 pagesPresented by Group 18: Neha Srivastava Sneha Shivam Garg TarunaNeha SrivastavaNo ratings yet
- Unit 2 Consumer As An IndividualDocument17 pagesUnit 2 Consumer As An IndividualRuhit SKNo ratings yet
- IIMBx BusMgmtMM AAMP FAQ v3 PDFDocument2 pagesIIMBx BusMgmtMM AAMP FAQ v3 PDFAnirudh AgarwallaNo ratings yet
- Airtel Brandanalysis 130214081214 Phpapp02Document57 pagesAirtel Brandanalysis 130214081214 Phpapp02Aditi BhagwatNo ratings yet
- Quality of Work LifeDocument1 pageQuality of Work LifeIndranil SarkarNo ratings yet
- Macroeconomic Analysis and Policies PDFDocument3 pagesMacroeconomic Analysis and Policies PDFRKNo ratings yet
- Corporate Legal Framework - 425 PDFDocument66 pagesCorporate Legal Framework - 425 PDFAashi PatelNo ratings yet
- Hypothesis Testing Sept 2016Document54 pagesHypothesis Testing Sept 2016Somil GuptaNo ratings yet
- Mahindra & Mahindra - PGDM 39Document4 pagesMahindra & Mahindra - PGDM 39jagdish_tNo ratings yet
- asset-v1-IIMBx ST101x 3T2017 Type@asset Block@w04 - C09Document4 pagesasset-v1-IIMBx ST101x 3T2017 Type@asset Block@w04 - C09Rahul YuvarajNo ratings yet
- History and Evolution of BanksDocument10 pagesHistory and Evolution of Bankssakshisrivastava100% (1)
- Iimbx Busmgtmm Aamp Faq v4Document2 pagesIimbx Busmgtmm Aamp Faq v4Sandra GilbertNo ratings yet
- 13 Macroeconomic Analysis of India's Inclusive Growth - Sunil Bhardwaj - GM012Document9 pages13 Macroeconomic Analysis of India's Inclusive Growth - Sunil Bhardwaj - GM012Muhammad Sohail100% (1)
- Factor AnalysisDocument3 pagesFactor Analysissweta_starNo ratings yet
- 2 Puffery-in-AdvertisementDocument9 pages2 Puffery-in-AdvertisementHarmeet KaurNo ratings yet
- Case Analysis Sheet: Group DetailsDocument7 pagesCase Analysis Sheet: Group DetailspriyanshaNo ratings yet
- Operations StartegyDocument27 pagesOperations StartegySaloni BishnoiNo ratings yet
- Factor AnalysisDocument11 pagesFactor AnalysisGeetika VermaNo ratings yet
- Business Enviornment: PREPARED BY:alokvyas SemDocument15 pagesBusiness Enviornment: PREPARED BY:alokvyas SemAlok VyasNo ratings yet
- Factor and Cluster AnalysisDocument14 pagesFactor and Cluster Analysisbodhraj91No ratings yet
- Research AptitudeDocument4 pagesResearch AptitudeAman Khera86% (7)
- CRY Annual Report 2019 20Document41 pagesCRY Annual Report 2019 20OmkkarNo ratings yet
- An Introduction To Factor Analysis: Philip HylandDocument34 pagesAn Introduction To Factor Analysis: Philip HylandAtiqah NizamNo ratings yet
- Factor Analysis Spss NotesDocument4 pagesFactor Analysis Spss NotesgauravibsNo ratings yet
- Introduction To Factor Analysis (Compatibility Mode) PDFDocument20 pagesIntroduction To Factor Analysis (Compatibility Mode) PDFchaitukmrNo ratings yet
- Analysing Consumer MarketDocument24 pagesAnalysing Consumer Marketabhi4u.kumarNo ratings yet
- Monmeet Instrumentation MMDTDocument18 pagesMonmeet Instrumentation MMDTMonmeet MallickNo ratings yet
- CCMM Zomato (Original Deck)Document39 pagesCCMM Zomato (Original Deck)Sidharth SoniNo ratings yet
- Factorial DesignDocument4 pagesFactorial DesignPatriciaIvanaAbiogNo ratings yet
- PerceptionDocument33 pagesPerceptionapi-3803716100% (3)
- Key Formulation Challenges of Protein (Mab) Drugs: Sandeep Nema, PHD PfizerDocument56 pagesKey Formulation Challenges of Protein (Mab) Drugs: Sandeep Nema, PHD PfizerMAHESHNo ratings yet
- Types of Interviews - HRMDocument19 pagesTypes of Interviews - HRMhaseebNo ratings yet
- Organization Behavior Solved Subjective QuestionsDocument6 pagesOrganization Behavior Solved Subjective QuestionsRaheel KhanNo ratings yet
- Individual and GroupDocument14 pagesIndividual and GroupSarita yadavNo ratings yet
- New Age Business ModelsDocument15 pagesNew Age Business ModelsAnil SoniNo ratings yet
- Nomothetic Vs IdiographicDocument9 pagesNomothetic Vs IdiographicBhupesh ManoharanNo ratings yet
- Pt1 Simple Linear RegressionDocument77 pagesPt1 Simple Linear RegressionradhicalNo ratings yet
- Marketing Research - Malhotra CH 3Document28 pagesMarketing Research - Malhotra CH 3Barun GuptaNo ratings yet
- R-13, Trading Traveling Time For Gasoline Consumption On The Nation's Highways Application of Isoquant Curves and Isocost LineDocument7 pagesR-13, Trading Traveling Time For Gasoline Consumption On The Nation's Highways Application of Isoquant Curves and Isocost LineMisha GargNo ratings yet
- Harvard SPSS Tutorial PDFDocument84 pagesHarvard SPSS Tutorial PDFsunilgenius@gmail.comNo ratings yet
- Operations ResearchDocument185 pagesOperations ResearchriddhiNo ratings yet
- Corporate Finance: Course SyllabusDocument6 pagesCorporate Finance: Course SyllabusKhandaker Amir Entezam100% (1)
- Chapter 2 - Thinking Like An EconomistDocument3 pagesChapter 2 - Thinking Like An EconomistMaura AdeliaNo ratings yet
- Parable of SadhuDocument11 pagesParable of SadhuHimesh AnandNo ratings yet
- Man - Invest Chap 006Document34 pagesMan - Invest Chap 006yolaNo ratings yet
- Amity - Business Communication 2Document27 pagesAmity - Business Communication 2Raghav MarwahNo ratings yet
- Zeus Asset Management Inc. - Team 1 - Investment ManagementDocument4 pagesZeus Asset Management Inc. - Team 1 - Investment ManagementVvb SatyanarayanaNo ratings yet
- Intelligent InstrumentsDocument6 pagesIntelligent InstrumentsJarvis MNo ratings yet
- Emotions & Attitude PresentationDocument26 pagesEmotions & Attitude Presentationkanhaiya.manda100% (1)
- Determining The Sample Size (Continuous Data)Document4 pagesDetermining The Sample Size (Continuous Data)Surbhi Jain100% (1)
- Market ResearchDocument127 pagesMarket Researchsang kumarNo ratings yet
- Ch9-Factor Analysis ModelDocument44 pagesCh9-Factor Analysis ModelarakazajeandavidNo ratings yet
- Brake Design ReportDocument27 pagesBrake Design ReportK.Kiran KumarNo ratings yet
- Module 6 RM: Advanced Data Analysis TechniquesDocument23 pagesModule 6 RM: Advanced Data Analysis TechniquesEm JayNo ratings yet
- Factor Analysis GlossaryDocument7 pagesFactor Analysis GlossaryZorz112No ratings yet
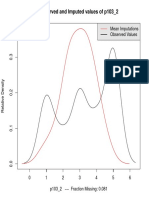
- Observed and Imputed Values of p103 - 2Document1 pageObserved and Imputed Values of p103 - 2waldemarclausNo ratings yet
- Banyay, Irene Kardos-The History of The Hungarian MusicDocument301 pagesBanyay, Irene Kardos-The History of The Hungarian MusicwaldemarclausNo ratings yet
- Handbook On Prisons. Willan Publishing, Collumpton: 471-495Document2 pagesHandbook On Prisons. Willan Publishing, Collumpton: 471-495waldemarclausNo ratings yet
- Chambliss StateorgcrimeDocument26 pagesChambliss StateorgcrimewaldemarclausNo ratings yet
- Illegal Markets Protection Rackets and O PDFDocument19 pagesIllegal Markets Protection Rackets and O PDFwaldemarclausNo ratings yet
- Crime Handbook Final PDFDocument62 pagesCrime Handbook Final PDFwaldemarclausNo ratings yet
- Unidimensional ScalingDocument8 pagesUnidimensional ScalingwaldemarclausNo ratings yet
- Staff Prisoner Relations WhitemoorDocument201 pagesStaff Prisoner Relations WhitemoorwaldemarclausNo ratings yet
- Tait CareandtheprisonDocument9 pagesTait CareandtheprisonwaldemarclausNo ratings yet
- Moe-The Positive Theory of Public BureaucracyDocument14 pagesMoe-The Positive Theory of Public BureaucracywaldemarclausNo ratings yet
- Managing The Dilemma: Occupational Culture and Identity Among Prison OfficersDocument1 pageManaging The Dilemma: Occupational Culture and Identity Among Prison OfficerswaldemarclausNo ratings yet
- 6 F608 D 01Document64 pages6 F608 D 01waldemarclausNo ratings yet
- 4 Laporan Harian k3Document2 pages4 Laporan Harian k3M Azhar0% (1)
- Streets and Roads (Draft) : Sustrans Design Manual Chapter 4Document95 pagesStreets and Roads (Draft) : Sustrans Design Manual Chapter 4Aulannisa IsthafiNo ratings yet
- Toyo - Soal Dasar Akuntansi UTS - Gasal 2122Document2 pagesToyo - Soal Dasar Akuntansi UTS - Gasal 2122Dita nNo ratings yet
- Termina Details 5 21Document17 pagesTermina Details 5 21Harikesh YadavNo ratings yet
- CFA Level 2 - 2020 Curriculum Changes (300hours) PDFDocument1 pageCFA Level 2 - 2020 Curriculum Changes (300hours) PDFJOAONo ratings yet
- EDPS - (Guidelines) On Processing PI in Whistleblowing Procedure A 17-12-19Document16 pagesEDPS - (Guidelines) On Processing PI in Whistleblowing Procedure A 17-12-19Mario Gomez100% (1)
- Properties of Laplace Transform - ROCDocument5 pagesProperties of Laplace Transform - ROCrachit guptaNo ratings yet
- Quadratic EquationsDocument29 pagesQuadratic EquationsKristine Joyce ArinaboNo ratings yet
- Sexual HarassmentDocument11 pagesSexual HarassmentKrip KNo ratings yet
- Kuwait Anti Money Laundering (2013/106)Document21 pagesKuwait Anti Money Laundering (2013/106)Social Media Exchange Association100% (1)
- SECTION 2.5:: Special Services For Construction ProjectsDocument7 pagesSECTION 2.5:: Special Services For Construction ProjectsHeart DaclitanNo ratings yet
- LM123/LM223 LM323: Three-Terminal 3A-5V Positive Voltage RegulatorsDocument8 pagesLM123/LM223 LM323: Three-Terminal 3A-5V Positive Voltage Regulatorscarrasquel0No ratings yet
- Home About Us Executive Body Bar Council Contact UsDocument5 pagesHome About Us Executive Body Bar Council Contact UsT v subbareddyNo ratings yet
- Ubuntu Originally, According To The Company Website Is A DebianDocument5 pagesUbuntu Originally, According To The Company Website Is A DebianmikesenseiNo ratings yet
- Argan Oil TDSDocument3 pagesArgan Oil TDSgabriela_moron_aNo ratings yet
- Air Pollution EcologyDocument4 pagesAir Pollution EcologyCharlemyne Quevedo LachanceNo ratings yet
- Note How To File An AnswerDocument5 pagesNote How To File An AnswerAbc FghNo ratings yet
- MAXIMUS - 516 руководство пользователя - 1Document214 pagesMAXIMUS - 516 руководство пользователя - 1MMM-MMM100% (1)
- Microstructure & Mechanical Characterization of Modified Aluminium 6061Document14 pagesMicrostructure & Mechanical Characterization of Modified Aluminium 6061Dinesh DhaipulleNo ratings yet
- Capacitors HandoutDocument4 pagesCapacitors HandoutAi LynNo ratings yet
- Chapter 2 SynthesisDocument2 pagesChapter 2 SynthesisjonaNo ratings yet
- x4640 Server ArchitectureDocument44 pagesx4640 Server ArchitecturesandeepkoppisettigmaNo ratings yet
- SS 551-2009 - PreviewDocument12 pagesSS 551-2009 - PreviewRichard LeongNo ratings yet
- Society & Culture With Family Planning PrelimDocument2 pagesSociety & Culture With Family Planning PrelimKent LNo ratings yet
- Raytek TX DatasheetDocument4 pagesRaytek TX DatasheetM. Reza FahlefiNo ratings yet
- CDVR CommissioningDocument47 pagesCDVR CommissioningZamani MahdiNo ratings yet
- Artigo - Doll e Torkzadeh 1988 - The Mesurement of End-User Computing SatisfactionDocument17 pagesArtigo - Doll e Torkzadeh 1988 - The Mesurement of End-User Computing Satisfactiondtdesouza100% (1)
- OpenSSH - 7.4 Multiple Vulnerabilities - Nessus - InfosecMatterDocument1 pageOpenSSH - 7.4 Multiple Vulnerabilities - Nessus - InfosecMatterdrgyyNo ratings yet
- PCST - MODULE - 0.2 Process Control Systems Technician ProgramDocument15 pagesPCST - MODULE - 0.2 Process Control Systems Technician Programkali bangonNo ratings yet
- ICDL Module 1 FinalDocument131 pagesICDL Module 1 Finalyousef100% (1)