You might also like
- Building the Internet of Things with IPv6 and MIPv6: The Evolving World of M2M CommunicationsFrom EverandBuilding the Internet of Things with IPv6 and MIPv6: The Evolving World of M2M CommunicationsNo ratings yet
- Fog Computing ReportDocument38 pagesFog Computing Reportosama ahmed100% (1)
- Edge Computing SeminarDocument24 pagesEdge Computing SeminarNitin RanjanNo ratings yet
- Seminar Report PDFDocument27 pagesSeminar Report PDFsanjay100% (1)
- Unit 1 - Computing ParadigmsDocument31 pagesUnit 1 - Computing ParadigmsDr.Ramesh Babu PittalaNo ratings yet
- Intrusion Detection Techniques in Mobile NetworksDocument8 pagesIntrusion Detection Techniques in Mobile NetworksInternational Organization of Scientific Research (IOSR)No ratings yet
- Cloud Data Storage With Secure Deduplication at Resource Side - PublicationDocument86 pagesCloud Data Storage With Secure Deduplication at Resource Side - PublicationVamsi SakhamuriNo ratings yet
- IOT Networks and ProtocolsDocument27 pagesIOT Networks and Protocolsfaisul faryNo ratings yet
- CDD reduces interference in cellular systems by less than 40 charactersDocument19 pagesCDD reduces interference in cellular systems by less than 40 charactersNitin SakpalNo ratings yet
- Wimax - Presentation - Case StudyDocument22 pagesWimax - Presentation - Case StudyOcira OyaroNo ratings yet
- Internet of Things (Iot) : A Survey On Architecture, Enabling Technologies, Applications and ChallengesDocument12 pagesInternet of Things (Iot) : A Survey On Architecture, Enabling Technologies, Applications and ChallengesayadmanNo ratings yet
- Enterprise Database Security & Monitoring: Alfred Horng IBM Software GroupDocument19 pagesEnterprise Database Security & Monitoring: Alfred Horng IBM Software GroupSean LamNo ratings yet
- Security Issues & Threats in IoT InfrastructureDocument5 pagesSecurity Issues & Threats in IoT InfrastructureIjaems JournalNo ratings yet
- Seminar ReportDocument11 pagesSeminar ReportShivam Singh100% (1)
- Seminar Report - 4g Wireless TechnologyDocument35 pagesSeminar Report - 4g Wireless TechnologyAbdul WadoodNo ratings yet
- Wireless Internet SecurityDocument24 pagesWireless Internet SecurityParvathi GoudNo ratings yet
- Edge Computing: BY Beerappa R NaikDocument8 pagesEdge Computing: BY Beerappa R NaikBeerappa RamakrishnaNo ratings yet
- SeminarDocument12 pagesSeminarNAVEEN KUMAR100% (1)
- Cordect: Wireless Access SystemDocument24 pagesCordect: Wireless Access Systemarjun c chandrathil100% (1)
- A Review of Network Traffic Analysis and Prediction TechniquesDocument22 pagesA Review of Network Traffic Analysis and Prediction TechniquesPatrick GelardNo ratings yet
- Challenges in Mobile SecurityDocument8 pagesChallenges in Mobile SecurityGyhgy EwfdewNo ratings yet
- Seminar ReportDocument9 pagesSeminar ReportVaibhav BaluniNo ratings yet
- Seminar CyberDocument20 pagesSeminar Cyberyasaswi sonyNo ratings yet
- Mobile Computing: A Seminar Report OnDocument32 pagesMobile Computing: A Seminar Report OnTushar Tyagi100% (1)
- M.Sc. in Computer Science: Advanced NetworkingDocument20 pagesM.Sc. in Computer Science: Advanced NetworkingJetmir Sadiku100% (1)
- Seminar Report (Networking)Document17 pagesSeminar Report (Networking)jbhamarNo ratings yet
- XMPP Presentation 160108105545 PDFDocument17 pagesXMPP Presentation 160108105545 PDFRiska AANo ratings yet
- Networking ReportDocument25 pagesNetworking ReportyogeshNo ratings yet
- POV-Internet of Things Nirmal Nag: Design Authority, SAP Enterprise ApplicationDocument20 pagesPOV-Internet of Things Nirmal Nag: Design Authority, SAP Enterprise ApplicationNirmal NagNo ratings yet
- Network Document: Benefits and TypesDocument9 pagesNetwork Document: Benefits and TypesPranav ShandilNo ratings yet
- CSE Database Management SystemDocument23 pagesCSE Database Management SystemAKHIL RAJNo ratings yet
- Net-Centric Past Questions AnswersDocument7 pagesNet-Centric Past Questions Answersaltair001No ratings yet
- HTTP and FTP Chapter ProblemsDocument10 pagesHTTP and FTP Chapter ProblemsFarhan Sheikh MuhammadNo ratings yet
- Wireless Lan PresentationDocument19 pagesWireless Lan Presentationapi-3765549No ratings yet
- Cloud Computing: Sharad Singh Abhishek Sinha Austin Rodrigues Arun GuptaDocument26 pagesCloud Computing: Sharad Singh Abhishek Sinha Austin Rodrigues Arun Guptasharadsingh23No ratings yet
- GSM Home Automation System ReportDocument29 pagesGSM Home Automation System ReportSubham PalNo ratings yet
- Internet of ThingsDocument25 pagesInternet of ThingssofimukhtarNo ratings yet
- Network Intrusion Simulation Using OPNETDocument5 pagesNetwork Intrusion Simulation Using OPNETyzho100% (1)
- Traceback of DDoS Attacks Using Entropy Variations AbstractDocument3 pagesTraceback of DDoS Attacks Using Entropy Variations AbstractJason StathamNo ratings yet
- Jazan University Cloud Computing SecurityDocument9 pagesJazan University Cloud Computing SecurityManal FaluojiNo ratings yet
- Mobile COMPUTINGDocument169 pagesMobile COMPUTINGNPMYS23No ratings yet
- 5G WirelessDocument25 pages5G WirelessShailendra Singh100% (1)
- CND Practical 1 To 12Document26 pagesCND Practical 1 To 12PALLAV MANDVENo ratings yet
- Computer Network Design For Universities in Developing CountriesDocument88 pagesComputer Network Design For Universities in Developing CountriesAhmed JahaNo ratings yet
- Seminar ReportDocument19 pagesSeminar ReportSahil Sethi100% (1)
- Chapter Two (Network Thesis Book)Document16 pagesChapter Two (Network Thesis Book)Latest Tricks100% (1)
- Security System For DNS Using CryptographyDocument7 pagesSecurity System For DNS Using CryptographyAbhinavSinghNo ratings yet
- Prepare A Report On Smart City 'Document12 pagesPrepare A Report On Smart City 'Ringtones WorldsNo ratings yet
- Approaches To Green ComputingDocument3 pagesApproaches To Green Computingshukriali100% (1)
- Seminar Report TemplateDocument31 pagesSeminar Report TemplateSubin M MadhuNo ratings yet
- IOT ReportDocument20 pagesIOT ReportChaithu GowdruNo ratings yet
- Cyber Threats and SecurityDocument17 pagesCyber Threats and Securityno OneNo ratings yet
- Voice Browser OriginalDocument27 pagesVoice Browser OriginalakhilsajeedranNo ratings yet
- Submitted By-Suprava Bastia Branch - Entc REGDN NO - 1801206207Document22 pagesSubmitted By-Suprava Bastia Branch - Entc REGDN NO - 1801206207suprava bastiaNo ratings yet
- Firewalls PresentationDocument24 pagesFirewalls PresentationDhritimanChakrabortyNo ratings yet
- Ip Spoofing Seminar ReportDocument38 pagesIp Spoofing Seminar ReportVishnu RaviNo ratings yet
- Network Installation at Arsi UniversityDocument21 pagesNetwork Installation at Arsi UniversityMilion NugusieNo ratings yet
- Survey On Child Safety Wearable Device Using IoT Sensors and Cloud ComputingDocument8 pagesSurvey On Child Safety Wearable Device Using IoT Sensors and Cloud ComputingInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Daknet TechnologyDocument8 pagesDaknet TechnologyAkshitSanghaviNo ratings yet
- A ULTIMA ReleaseNotesAxiomV PDFDocument38 pagesA ULTIMA ReleaseNotesAxiomV PDFIVANALTAMARNo ratings yet
- TILE FIXING GUIDEDocument1 pageTILE FIXING GUIDEStavros ApostolidisNo ratings yet
- Early Diabetic Risk Prediction Using Machine Learning Classification TechniquesDocument6 pagesEarly Diabetic Risk Prediction Using Machine Learning Classification TechniquesInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- SHORT STORY Manhood by John Wain - Lindsay RossouwDocument17 pagesSHORT STORY Manhood by John Wain - Lindsay RossouwPrincess67% (3)
- Structural IfpDocument4 pagesStructural IfpDanny NguyenNo ratings yet
- Power Team PE55 ManualDocument13 pagesPower Team PE55 ManualTitanplyNo ratings yet
- OPHTHALDocument8 pagesOPHTHALVarun ChandiramaniNo ratings yet
- Reference - Unit-V PDFDocument128 pagesReference - Unit-V PDFRamesh BalakrishnanNo ratings yet
- Administracion Una Perspectiva Global Y Empresarial Resumen Por CapitulosDocument7 pagesAdministracion Una Perspectiva Global Y Empresarial Resumen Por Capitulosafmqqaepfaqbah100% (1)
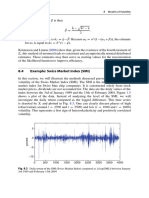
- 8.4 Example: Swiss Market Index (SMI) : 188 8 Models of VolatilityDocument3 pages8.4 Example: Swiss Market Index (SMI) : 188 8 Models of VolatilityNickesh ShahNo ratings yet
- Presepsi Khalayak Terhadap Program Acara Televise Reality Show "Jika Aku Menjadi" Di Trans TVDocument128 pagesPresepsi Khalayak Terhadap Program Acara Televise Reality Show "Jika Aku Menjadi" Di Trans TVAngga DianNo ratings yet
- Financial Accounting IFRS 3rd Edition Weygandt Solutions Manual 1Document8 pagesFinancial Accounting IFRS 3rd Edition Weygandt Solutions Manual 1jacob100% (34)
- Request For Proposal Construction & Phase 1 OperationDocument116 pagesRequest For Proposal Construction & Phase 1 Operationsobhi100% (2)
- Admisibility To Object EvidenceDocument168 pagesAdmisibility To Object EvidenceAnonymous 4WA9UcnU2XNo ratings yet
- Geometric Sculpture From 72 PencilsDocument5 pagesGeometric Sculpture From 72 PencilsHugo Iván Gonzalez CruzNo ratings yet
- Casestudy3 Hbo MaDocument2 pagesCasestudy3 Hbo Ma132345usdfghjNo ratings yet
- Quality Improvement Reading Material1Document10 pagesQuality Improvement Reading Material1Paul Christopher PinedaNo ratings yet
- Project Wise CSR Expenditure FY202223Document15 pagesProject Wise CSR Expenditure FY202223gowowor677No ratings yet
- Ahu, Chiller, Fcu Technical Bid TabulationDocument15 pagesAhu, Chiller, Fcu Technical Bid TabulationJohn Henry AsuncionNo ratings yet
- Friction, Gravity and Energy TransformationsDocument12 pagesFriction, Gravity and Energy TransformationsDaiserie LlanezaNo ratings yet
- AWS Cloud Practicioner Exam Examples 0Document110 pagesAWS Cloud Practicioner Exam Examples 0AnataTumonglo100% (3)
- KingmakerDocument5 pagesKingmakerIan P RiuttaNo ratings yet
- Travis Walton Part 1 MUFON Case FileDocument346 pagesTravis Walton Part 1 MUFON Case FileClaudio Silva100% (1)
- Interesting Facts (Compiled by Andrés Cordero 2023)Document127 pagesInteresting Facts (Compiled by Andrés Cordero 2023)AndresCorderoNo ratings yet
- One - Pager - SOGEVAC SV 320 BDocument2 pagesOne - Pager - SOGEVAC SV 320 BEOLOS COMPRESSORS LTDNo ratings yet
- Cyber Security 2017Document8 pagesCyber Security 2017Anonymous i1ClcyNo ratings yet
- Grace Lipsini1 2 3Document4 pagesGrace Lipsini1 2 3api-548923370No ratings yet
- 266 009-336Document327 pages266 009-336AlinaE.BarbuNo ratings yet
- Inspection and Acceptance Report: Stock No. Unit Description QuantityDocument6 pagesInspection and Acceptance Report: Stock No. Unit Description QuantityAnj LeeNo ratings yet
- Membandingkan Recall 24 Jam Nutri Survey Dengan TkpiDocument7 pagesMembandingkan Recall 24 Jam Nutri Survey Dengan TkpiFransisca SihotangNo ratings yet