You might also like
- Service Setup Manual: Svmim-M3Document18 pagesService Setup Manual: Svmim-M3lucio ruiz jrNo ratings yet
- Service Setup Manual: Svmim-M3Document18 pagesService Setup Manual: Svmim-M3lucio ruiz jrNo ratings yet
- Appendix 2: For Inspection Purposes OnlyDocument32 pagesAppendix 2: For Inspection Purposes Onlylucio ruiz jrNo ratings yet
- Case Study No 1 PDFDocument8 pagesCase Study No 1 PDFlucio ruiz jrNo ratings yet
- Appendix 2: For Inspection Purposes OnlyDocument32 pagesAppendix 2: For Inspection Purposes Onlylucio ruiz jrNo ratings yet
- Field Duct Sizing Chart: Round Duct Size EstimateDocument1 pageField Duct Sizing Chart: Round Duct Size EstimateKhadija MirajNo ratings yet
- Case Study No 3Document8 pagesCase Study No 3lucio ruiz jrNo ratings yet
- Svmpc1: Installation ManualDocument8 pagesSvmpc1: Installation Manuallucio ruiz jrNo ratings yet
- Psych Ro Metric InfoDocument5 pagesPsych Ro Metric Infoforevertay2000No ratings yet
- Split Type Air Conditioners: DC Inverter Control 50 HZDocument4 pagesSplit Type Air Conditioners: DC Inverter Control 50 HZlucio ruiz jrNo ratings yet
- VRV - Minor Change PCVPH1617aprvDocument52 pagesVRV - Minor Change PCVPH1617aprvlucio ruiz jrNo ratings yet
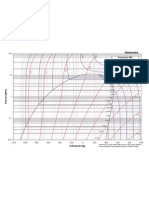
- Ammonia P-H ChartDocument1 pageAmmonia P-H Chartalimkali86% (7)
- Material List: 2.1. Table of AbbreviationsDocument7 pagesMaterial List: 2.1. Table of Abbreviationslucio ruiz jrNo ratings yet
- HVAC Engineer Interview 70 Question Answers (Mechanical Engineer) PDFDocument11 pagesHVAC Engineer Interview 70 Question Answers (Mechanical Engineer) PDFChahbi Ramzi100% (1)
- Cryogenic Energy StorageDocument17 pagesCryogenic Energy Storagelucio ruiz jrNo ratings yet
- Ruiz.l - Quiz 2Document3 pagesRuiz.l - Quiz 2lucio ruiz jrNo ratings yet
- Manulife VRV System Selection for Philippines OfficeDocument7 pagesManulife VRV System Selection for Philippines Officelucio ruiz jrNo ratings yet
- Material List: 2.1. Table of AbbreviationsDocument24 pagesMaterial List: 2.1. Table of Abbreviationslucio ruiz jrNo ratings yet
- Dmahu Summary Report: Unit and Components SpecificationDocument10 pagesDmahu Summary Report: Unit and Components Specificationlucio ruiz jrNo ratings yet
- Dmahu Summary Report: Unit and Components SpecificationDocument10 pagesDmahu Summary Report: Unit and Components Specificationlucio ruiz jrNo ratings yet
- Board of Master Plumber-SBDocument7 pagesBoard of Master Plumber-SBdereckaNo ratings yet
- Ca-Fcu H-201707Document33 pagesCa-Fcu H-201707lucio ruiz jrNo ratings yet
- Second Floor Air Conditioning Plan: A B C D E F G H I J K L MDocument1 pageSecond Floor Air Conditioning Plan: A B C D E F G H I J K L Mlucio ruiz jrNo ratings yet
- Material List: 2.1. Table of AbbreviationsDocument18 pagesMaterial List: 2.1. Table of Abbreviationslucio ruiz jrNo ratings yet
- Daikin Presentation - Chiller SystemDocument112 pagesDaikin Presentation - Chiller Systemlucio ruiz jr100% (1)
- Installation Manual for iTM plus adaptor Model DCM601A52Document36 pagesInstallation Manual for iTM plus adaptor Model DCM601A52lucio ruiz jrNo ratings yet
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (73)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2219)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (119)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- India: 1UBK7-470E1Document67 pagesIndia: 1UBK7-470E1harish kumar100% (1)
- SD Card Formatter 5.01 User's Manual: July 15, 2021Document11 pagesSD Card Formatter 5.01 User's Manual: July 15, 2021Alexis GutierrezNo ratings yet
- Candidate Workshop ManualDocument45 pagesCandidate Workshop ManualMark Brewer100% (1)
- YASHICA MAT-124 User's ManualDocument34 pagesYASHICA MAT-124 User's Manuallegrandew100% (1)
- Planning River Intake Structure DesignDocument43 pagesPlanning River Intake Structure DesignSandhiya saravanan100% (1)
- Frontal - Cortex Assess Battery FAB - ScaleDocument2 pagesFrontal - Cortex Assess Battery FAB - Scalewilliamsa01No ratings yet
- Anis MahmudahDocument14 pagesAnis MahmudahAlim ZainulNo ratings yet
- Fault Code 498 Engine Oil Level Sensor Circuit - Voltage Above Normal, or Shorted To High SourceDocument13 pagesFault Code 498 Engine Oil Level Sensor Circuit - Voltage Above Normal, or Shorted To High SourceAhmedmah100% (1)
- Analysis of Wood Bending PropertiesDocument11 pagesAnalysis of Wood Bending Propertiesprasanna020391100% (1)
- TH - TB Series (Helical GearBox Catalog)Document94 pagesTH - TB Series (Helical GearBox Catalog)poorianaNo ratings yet
- Sem 656DDocument1 pageSem 656DCarlos Arturo AcevedoNo ratings yet
- Object Oriented Programming (OOPS) : Java Means Durga SirDocument2 pagesObject Oriented Programming (OOPS) : Java Means Durga SirROHIT JAINNo ratings yet
- Employees Management On Sport DevelopmenDocument7 pagesEmployees Management On Sport DevelopmenBeky AbrahamNo ratings yet
- A Treatise On Physical GeographyDocument441 pagesA Treatise On Physical Geographyramosbrunoo8933No ratings yet
- Crane Company Within SingaporeDocument4 pagesCrane Company Within SingaporeRash AcidNo ratings yet
- Kollmorgen S300 Servo Drive ManualDocument134 pagesKollmorgen S300 Servo Drive ManualCarlos SalazarNo ratings yet
- Paper ESEE2017 CLJLand MLDocument12 pagesPaper ESEE2017 CLJLand MLMatheus CardimNo ratings yet
- COMPUTER NETWORKS-3, Nitheesh.T, 21MIS0401Document23 pagesCOMPUTER NETWORKS-3, Nitheesh.T, 21MIS0401nitheeshNo ratings yet
- Walsh, S. (2006)Document10 pagesWalsh, S. (2006)ratu erlindaNo ratings yet
- 01 LANG Forgiarini Low Energy EmulsificationDocument8 pages01 LANG Forgiarini Low Energy EmulsificationDuvánE.DueñasLópezNo ratings yet
- TS4F01-1 Unit 4 - Document ControlDocument66 pagesTS4F01-1 Unit 4 - Document ControlLuki1233332No ratings yet
- Test Bank For The Human Body in Health and Disease 7th Edition by PattonDocument11 pagesTest Bank For The Human Body in Health and Disease 7th Edition by PattonLaurence Pence100% (23)
- NSTP Law and ROTC RequirementsDocument47 pagesNSTP Law and ROTC RequirementsJayson Lucena82% (17)
- A Knowledge Management Approach To Organizational Competitive Advantage Evidence From The Food SectorDocument13 pagesA Knowledge Management Approach To Organizational Competitive Advantage Evidence From The Food SectorJack WenNo ratings yet
- Class Note 2 - Rain GaugesDocument6 pagesClass Note 2 - Rain GaugesPrakash PatelNo ratings yet
- Unleashing Learner PowerDocument188 pagesUnleashing Learner PowerEka MeilinaNo ratings yet
- DLP November 7 11 2022Document11 pagesDLP November 7 11 2022Harvey RabinoNo ratings yet
- Technical Card: Information OnlyDocument1 pageTechnical Card: Information OnlyBhuvnesh VermaNo ratings yet
- CHAPTER 9 Microsoft Excel 2016 Back ExerciseDocument3 pagesCHAPTER 9 Microsoft Excel 2016 Back ExerciseGargi SinghNo ratings yet
- Pre-Admission Interview Slip TemplateDocument1 pagePre-Admission Interview Slip TemplateLeaniel SilvaNo ratings yet