You might also like
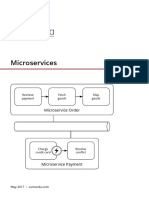
- Microservices Niram PDFDocument6 pagesMicroservices Niram PDFnniram sugriyaaaNo ratings yet
- Why Event-Driven Microservices - Building Event-Driven MicroservicesDocument7 pagesWhy Event-Driven Microservices - Building Event-Driven MicroservicesChandra Sekhar DNo ratings yet
- WP Microservices in The Apache Kafka EcosystemDocument6 pagesWP Microservices in The Apache Kafka EcosystemfwwumffpmsunbgtsfeNo ratings yet
- 22mis0037 VL2023240503321 DaDocument14 pages22mis0037 VL2023240503321 DaPrarthana SNo ratings yet
- Borderless InnovationsDocument3 pagesBorderless InnovationsChristine Jan Dela VegaNo ratings yet
- Pso 2300Document35 pagesPso 2300cool dude911No ratings yet
- Virtual Platform TechnologiesDocument11 pagesVirtual Platform TechnologiesLouie TiroNo ratings yet
- 5Cztxs Microservices 2017 enDocument18 pages5Cztxs Microservices 2017 enManuel VegaNo ratings yet
- PWC Cloud Computing and Revenue Recognition Whitepaper PDFDocument14 pagesPWC Cloud Computing and Revenue Recognition Whitepaper PDFwclonnNo ratings yet
- Network as Code Architecture Cross-BG Presentation-1(1)Document10 pagesNetwork as Code Architecture Cross-BG Presentation-1(1)Upma GandhiNo ratings yet
- WP RedisLabs Microservices Kubernetes 1560870546484Document6 pagesWP RedisLabs Microservices Kubernetes 1560870546484Ion PostolacheNo ratings yet
- Survey on Virtualization Levels and TechnologiesDocument12 pagesSurvey on Virtualization Levels and TechnologiestamernadeemNo ratings yet
- Ebook How To Build and Scale With MicroservicesDocument17 pagesEbook How To Build and Scale With MicroservicesRahul KadamNo ratings yet
- VMware Automation Presentation enDocument22 pagesVMware Automation Presentation enSuRiUNo ratings yet
- IBM Cloud - Microservices Point of View Guide PDFDocument35 pagesIBM Cloud - Microservices Point of View Guide PDFThermionNo ratings yet
- Unveiling The Hardware and Software Implications of Microservices in Cloud and Edge SystemsDocument10 pagesUnveiling The Hardware and Software Implications of Microservices in Cloud and Edge SystemsTheWhiteNo ratings yet
- Pitfalls and Challenges Faced During A Microservices Architecture Implementation Codex5066Document21 pagesPitfalls and Challenges Faced During A Microservices Architecture Implementation Codex5066Sravan TNo ratings yet
- Hunt, Flynn, Smith - 2019 - The Substation of The Future Moving Toward A Digital SolutionDocument9 pagesHunt, Flynn, Smith - 2019 - The Substation of The Future Moving Toward A Digital SolutionErick CapusNo ratings yet
- Virtualization and Its Role in Cloud Computing EnvironmentDocument7 pagesVirtualization and Its Role in Cloud Computing EnvironmentNehal GuptaNo ratings yet
- the-essential-guide-to-modern-apmDocument10 pagesthe-essential-guide-to-modern-apmKunto UtoroNo ratings yet
- Comparison of Biometric and Non-Biometric Security Techniques in Mobile Cloud ComputingDocument5 pagesComparison of Biometric and Non-Biometric Security Techniques in Mobile Cloud ComputingMartin Cardenas MorenoNo ratings yet
- Migrating Enterprise Legacy Source Code To Microservices: On Multi-Tenancy, Statefulness and Data ConsistencyDocument7 pagesMigrating Enterprise Legacy Source Code To Microservices: On Multi-Tenancy, Statefulness and Data ConsistencyRejnis SpahoNo ratings yet
- System Observability and Monitoring For Multi Cloud Native Network Service Based FunctionDocument9 pagesSystem Observability and Monitoring For Multi Cloud Native Network Service Based FunctionIJRASETPublicationsNo ratings yet
- Emerging Trends in Safety Issues in Cloud: The Potentials of Threat ModelDocument4 pagesEmerging Trends in Safety Issues in Cloud: The Potentials of Threat ModelRahul SharmaNo ratings yet
- Unifi Ed Monitoring™: A Business PerspectiveDocument11 pagesUnifi Ed Monitoring™: A Business Perspectiveamitkjain_hotmailNo ratings yet
- Accelerating Microservices Design and Development Codex2533Document11 pagesAccelerating Microservices Design and Development Codex2533OrlandoUtreraNo ratings yet
- Nguyen and Debroy - 2022 - Moving Target Defense-Based Denial-of-Service MitiDocument24 pagesNguyen and Debroy - 2022 - Moving Target Defense-Based Denial-of-Service MitiprathamgunjNo ratings yet
- Microras CRDocument11 pagesMicroras CRFlashclassroomNo ratings yet
- Cloud ComputingDocument37 pagesCloud ComputingLuis Fernando Quintero HenaoNo ratings yet
- Microservice Architecture For The Enterprise PDFDocument14 pagesMicroservice Architecture For The Enterprise PDFaldan63No ratings yet
- leanIX Whitepaper Microservices EN-6Document8 pagesleanIX Whitepaper Microservices EN-6Jesus BelloNo ratings yet
- Application-Centric Networking: The Art ofDocument4 pagesApplication-Centric Networking: The Art ofmd ShabirNo ratings yet
- Dzone Refcard295 Microseviceswithredis0408Document7 pagesDzone Refcard295 Microseviceswithredis0408EduardoNo ratings yet
- Special Feature - Microservices r2Document28 pagesSpecial Feature - Microservices r2abura1No ratings yet
- Server Less in Digital LandscapeDocument20 pagesServer Less in Digital LandscapeVictor GonzalezNo ratings yet
- IEEE Draft CodingHashirasDocument9 pagesIEEE Draft CodingHashiraswebsurfer2002No ratings yet
- 5 TH Paper AaqibDocument7 pages5 TH Paper AaqibHafedh JouiniNo ratings yet
- Cloud 101: Tools and Strategies For Evaluating Cloud ServicesDocument61 pagesCloud 101: Tools and Strategies For Evaluating Cloud ServicesManish AgarwalNo ratings yet
- Reimagining Service Assurance For NFV, SDN and 5G: Anil RaoDocument16 pagesReimagining Service Assurance For NFV, SDN and 5G: Anil RaomeetsudharNo ratings yet
- Architecture Decision On Using Microservices or Serverless Functions With ContainersDocument7 pagesArchitecture Decision On Using Microservices or Serverless Functions With Containershassanbenz1986No ratings yet
- Unit 1 Cloud ComputingDocument59 pagesUnit 1 Cloud Computingsushil@irdNo ratings yet
- Paper 4Document6 pagesPaper 41977amNo ratings yet
- Online Machine Learning For Cloud Resource Provisioning of Microservice Backend SystemsDocument9 pagesOnline Machine Learning For Cloud Resource Provisioning of Microservice Backend Systemsaden dargeNo ratings yet
- Redistributed Self Adjustment System For Service Supported Application in The CloudDocument4 pagesRedistributed Self Adjustment System For Service Supported Application in The Cloudijbui iirNo ratings yet
- A Study of Virtualization Techniques Applied in Cloud Computing EnvironmentDocument8 pagesA Study of Virtualization Techniques Applied in Cloud Computing EnvironmentIJRASETPublicationsNo ratings yet
- Microservice or Microservice Architecture (Part 1) – All You Want To KnowDocument3 pagesMicroservice or Microservice Architecture (Part 1) – All You Want To KnowvicsukNo ratings yet
- Db2 On KubernetesDocument70 pagesDb2 On KubernetesJenny Bosch100% (1)
- An Adaptive Priority Approach For Effective Problem Resolution in ITSMDocument12 pagesAn Adaptive Priority Approach For Effective Problem Resolution in ITSMProdapt Solutions100% (1)
- Analysis of Various Virtual Machine Attacks in Cloud ComputingDocument4 pagesAnalysis of Various Virtual Machine Attacks in Cloud ComputingVINOD DADASO SALUNKHE 20PHD0400No ratings yet
- Mentoring Cia Final DTDocument17 pagesMentoring Cia Final DTNOWRIN A H 2228344No ratings yet
- A Robust Security Framework For Cloud-Based Logistics Services-Kathiravan2018Document4 pagesA Robust Security Framework For Cloud-Based Logistics Services-Kathiravan2018saniya shaikhNo ratings yet
- 10 1109iceca 2018 8474838Document4 pages10 1109iceca 2018 8474838Sagittarius BNo ratings yet
- U6 - M2 - L5 - Microservice Architecture - Early Industry Adopters - Annotated - TaggedDocument18 pagesU6 - M2 - L5 - Microservice Architecture - Early Industry Adopters - Annotated - TaggedMarwan cleancodeNo ratings yet
- 1021833ijaas202107002Document7 pages1021833ijaas202107002CARLOS ALEXIS ALVARADO SILVANo ratings yet
- Cloud Computing Revolutionizes ITDocument22 pagesCloud Computing Revolutionizes ITkarthikajoyNo ratings yet
- Microservices Workflow Engines 2Document6 pagesMicroservices Workflow Engines 2Ashutosh GuptaNo ratings yet
- 1 1499237951 - 05-07-2017 PDFDocument5 pages1 1499237951 - 05-07-2017 PDFEditor IJRITCCNo ratings yet
- Cloud Computing: Harnessing the Power of the Digital Skies: The IT CollectionFrom EverandCloud Computing: Harnessing the Power of the Digital Skies: The IT CollectionNo ratings yet
- GET - Hands-On RESTful Web Services With Go - Second Edition PDFDocument1 pageGET - Hands-On RESTful Web Services With Go - Second Edition PDFChandra Sekhar DNo ratings yet
- The REST API - Hands-On RESTful Web Services With Go - Second EditionDocument1 pageThe REST API - Hands-On RESTful Web Services With Go - Second EditionChandra Sekhar DNo ratings yet
- Characteristics of REST Services - Hands-On RESTful Web Services With Go - Second EditionDocument1 pageCharacteristics of REST Services - Hands-On RESTful Web Services With Go - Second EditionChandra Sekhar DNo ratings yet
- REST Verbs and Status Codes - Hands-On RESTful Web Services With Go - Second EditionDocument1 pageREST Verbs and Status Codes - Hands-On RESTful Web Services With Go - Second EditionChandra Sekhar DNo ratings yet
- Characteristics of REST Services - Hands-On RESTful Web Services With Go - Second EditionDocument1 pageCharacteristics of REST Services - Hands-On RESTful Web Services With Go - Second EditionChandra Sekhar DNo ratings yet
- Types of Web Services - Hands-On RESTful Web Services With Go - Second EditionDocument1 pageTypes of Web Services - Hands-On RESTful Web Services With Go - Second EditionChandra Sekhar DNo ratings yet
- REST Verbs and Status Codes - Hands-On RESTful Web Services With Go - Second EditionDocument1 pageREST Verbs and Status Codes - Hands-On RESTful Web Services With Go - Second EditionChandra Sekhar DNo ratings yet
- Technical Requirements - Hands-On RESTful Web Services With Go - Second EditionDocument1 pageTechnical Requirements - Hands-On RESTful Web Services With Go - Second EditionChandra Sekhar DNo ratings yet
- Working With Shared Libraries - Beginning Jenkins Blue Ocean - Create Elegant Pipelines With EaseDocument11 pagesWorking With Shared Libraries - Beginning Jenkins Blue Ocean - Create Elegant Pipelines With EaseChandra Sekhar DNo ratings yet
- Communication and Data Contracts - Building Event-Driven MicroservicesDocument5 pagesCommunication and Data Contracts - Building Event-Driven MicroservicesChandra Sekhar DNo ratings yet
- The Slow Query Log - MySQL 8 Query Performance Tuning - A Systematic Method For Improving Execution SpeedsDocument6 pagesThe Slow Query Log - MySQL 8 Query Performance Tuning - A Systematic Method For Improving Execution SpeedsChandra Sekhar DNo ratings yet
- The REST API - Hands-On RESTful Web Services With Go - Second EditionDocument1 pageThe REST API - Hands-On RESTful Web Services With Go - Second EditionChandra Sekhar DNo ratings yet
- Types of Web Services - Hands-On RESTful Web Services With Go - Second EditionDocument1 pageTypes of Web Services - Hands-On RESTful Web Services With Go - Second EditionChandra Sekhar DNo ratings yet
- SHOW Statements - MySQL 8 Query Performance Tuning - A Systematic Method For Improving Execution SpeedsDocument6 pagesSHOW Statements - MySQL 8 Query Performance Tuning - A Systematic Method For Improving Execution SpeedsChandra Sekhar DNo ratings yet
- Getting Started With REST API Development - Hands-On RESTful Web Services With Go - Second EditionDocument1 pageGetting Started With REST API Development - Hands-On RESTful Web Services With Go - Second EditionChandra Sekhar DNo ratings yet
- The Slow Query Log - MySQL 8 Query Performance Tuning - A Systematic Method For Improving Execution SpeedsDocument6 pagesThe Slow Query Log - MySQL 8 Query Performance Tuning - A Systematic Method For Improving Execution SpeedsChandra Sekhar DNo ratings yet
- The Information Schema - MySQL 8 Query Performance Tuning - A Systematic Method For Improving Execution SpeedsDocument12 pagesThe Information Schema - MySQL 8 Query Performance Tuning - A Systematic Method For Improving Execution SpeedsChandra Sekhar DNo ratings yet
- Query Tuning Methodology - MySQL 8 Query Performance Tuning - A Systematic Method For Improving Execution SpeedsDocument4 pagesQuery Tuning Methodology - MySQL 8 Query Performance Tuning - A Systematic Method For Improving Execution SpeedsChandra Sekhar DNo ratings yet
- SHOW Statements - MySQL 8 Query Performance Tuning - A Systematic Method For Improving Execution SpeedsDocument6 pagesSHOW Statements - MySQL 8 Query Performance Tuning - A Systematic Method For Improving Execution SpeedsChandra Sekhar DNo ratings yet
- The Sys Schema - MySQL 8 Query Performance Tuning - A Systematic Method For Improving Execution SpeedsDocument5 pagesThe Sys Schema - MySQL 8 Query Performance Tuning - A Systematic Method For Improving Execution SpeedsChandra Sekhar DNo ratings yet
- AdministrationDocument112 pagesAdministrationkumara0303100% (1)
- Aviatrix User VPN On The Aws Cloud PDFDocument26 pagesAviatrix User VPN On The Aws Cloud PDFChandra Sekhar DNo ratings yet
- Rsyslog Centralized Logging Ebook PDFDocument30 pagesRsyslog Centralized Logging Ebook PDFChandra Sekhar DNo ratings yet
- Untitled Diagram PDFDocument6 pagesUntitled Diagram PDFChandra Sekhar DNo ratings yet
- Aviatrix User VPN On The Aws Cloud PDFDocument26 pagesAviatrix User VPN On The Aws Cloud PDFChandra Sekhar DNo ratings yet
- MySQL Performance Tuning - MySQL 8 Query Performance Tuning - A Systematic Method For Improving Execution SpeedsDocument3 pagesMySQL Performance Tuning - MySQL 8 Query Performance Tuning - A Systematic Method For Improving Execution SpeedsChandra Sekhar DNo ratings yet
- K8 Stateful APP LaunchingStep 1 - Deploy NFS ServerDocument11 pagesK8 Stateful APP LaunchingStep 1 - Deploy NFS ServerChandra Sekhar DNo ratings yet
- Rsyslog Centralized Logging Ebook PDFDocument30 pagesRsyslog Centralized Logging Ebook PDFChandra Sekhar DNo ratings yet
- Grating Catalog MeiserDocument136 pagesGrating Catalog MeiserAdrian Leonas IonitaNo ratings yet
- How Contextual Factors Influenced Rapid Uptake of Mobile Money in KenyaDocument19 pagesHow Contextual Factors Influenced Rapid Uptake of Mobile Money in KenyafadelNo ratings yet
- Harrod Domar ModelDocument2 pagesHarrod Domar ModelTechnical AwanNo ratings yet
- Combined Assurance: Overcoming Common ChallengesDocument18 pagesCombined Assurance: Overcoming Common ChallengesWM4scribdNo ratings yet
- Rapid Developer - Module 1Document11 pagesRapid Developer - Module 1junemrsNo ratings yet
- EGPC PSM GL 004 Layout and Facility Siting GuidelineDocument42 pagesEGPC PSM GL 004 Layout and Facility Siting Guidelinekhaled faragNo ratings yet
- Prefabricated StructureDocument129 pagesPrefabricated Structureemraan Khan100% (1)
- Cccu Babs l5 t1 DB Assignment 202304Document14 pagesCccu Babs l5 t1 DB Assignment 202304Dinu Anna-MariaNo ratings yet
- Penko FLEX SeriesDocument9 pagesPenko FLEX SeriesMario vd HeuvelNo ratings yet
- G.R. No. 154493 December 6, 2006 REYNALDO VILLANUEVA, Petitioner, Philippine National Bank (PNB), RespondentDocument3 pagesG.R. No. 154493 December 6, 2006 REYNALDO VILLANUEVA, Petitioner, Philippine National Bank (PNB), RespondentGennard Michael Angelo AngelesNo ratings yet
- Declaration Under para 2 (B) of Finance Deptt Memo. No. 6038-F Dated 22.05.84 Read With Memo. Nos. 1925-F, Dated 21.10.1984 and 46-F, Dt. 9.1.75Document2 pagesDeclaration Under para 2 (B) of Finance Deptt Memo. No. 6038-F Dated 22.05.84 Read With Memo. Nos. 1925-F, Dated 21.10.1984 and 46-F, Dt. 9.1.75Sayani NandyNo ratings yet
- Business Models For Geographic Information: January 2018Document23 pagesBusiness Models For Geographic Information: January 2018Bala RaoNo ratings yet
- Class 7 - Social Science - C6. Understanding Media - NotesDocument3 pagesClass 7 - Social Science - C6. Understanding Media - NotesDiya shivNo ratings yet
- Karnataka Land Grant Rules, 1969Document20 pagesKarnataka Land Grant Rules, 1969Ramanan SelvamNo ratings yet
- Advance Chapter 1Document16 pagesAdvance Chapter 1abel habtamuNo ratings yet
- Waste To Energy Incineration-Basic Guide 2020Document45 pagesWaste To Energy Incineration-Basic Guide 2020SRINIVASAN TNo ratings yet
- Polaroid - Process and Quality Control Case Study: Preparation by Presentation byDocument6 pagesPolaroid - Process and Quality Control Case Study: Preparation by Presentation byVinit Vijay SankheNo ratings yet
- MBA Research Proposal 2011Document12 pagesMBA Research Proposal 2011Obert Sanyambe100% (1)
- Thesis Fulltext01Document81 pagesThesis Fulltext01Chandra manandharNo ratings yet
- Common Reporting Standard (CRS) FactsheetDocument2 pagesCommon Reporting Standard (CRS) FactsheetFelix ChanNo ratings yet
- Accounting For Investment in Associates (Part 4) : Helping Our Clients Increase ValueDocument2 pagesAccounting For Investment in Associates (Part 4) : Helping Our Clients Increase ValueNguyen Binh MinhNo ratings yet
- Georgia Minibus Workers Organize Despite ObstaclesDocument2 pagesGeorgia Minibus Workers Organize Despite ObstaclesZainNo ratings yet
- Statement Period: Primary Savings (ID 00)Document5 pagesStatement Period: Primary Savings (ID 00)Mark Williams100% (1)
- Cse Dec 21 Free Mock Test Series Subject: Setting Up of Business Entities and ClosureDocument5 pagesCse Dec 21 Free Mock Test Series Subject: Setting Up of Business Entities and ClosureSimran TrehanNo ratings yet
- CRM Practice MCQ 2020Document2 pagesCRM Practice MCQ 202027-MOKSH JAINNo ratings yet
- Sample of Project Charter For Solar PanelDocument10 pagesSample of Project Charter For Solar PanelAZLAN AIYUBNo ratings yet
- Problem 1Document4 pagesProblem 1Live LoveNo ratings yet
- Chapter 4 Accounts ReceivableDocument12 pagesChapter 4 Accounts Receivableweddiemae villariza50% (2)
- Foreign Tax Form W-8BEN GuideDocument1 pageForeign Tax Form W-8BEN Guidehector100% (1)