You might also like
- Statistics Booklet For NEW A Level AQADocument68 pagesStatistics Booklet For NEW A Level AQAFarhan AktarNo ratings yet
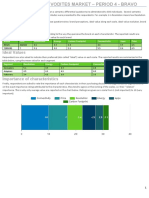
- Vodites - Mds and SemanticDocument5 pagesVodites - Mds and SemanticAnyone SomeoneNo ratings yet
- Advanced Portfolio Management: A Quant's Guide for Fundamental InvestorsFrom EverandAdvanced Portfolio Management: A Quant's Guide for Fundamental InvestorsNo ratings yet
- National Institute of Technology, Tiruchirappalli MBA Trimester Examination, Basic Data Analytic Marathon ExamDocument22 pagesNational Institute of Technology, Tiruchirappalli MBA Trimester Examination, Basic Data Analytic Marathon ExamArjun Jinumon PootharaNo ratings yet
- Lecture1 - How To Choose Your Research TopicDocument37 pagesLecture1 - How To Choose Your Research TopicZakariaHasaneen100% (2)
- BdaDocument24 pagesBdaAbinNo ratings yet
- Logistic Regression: Prof. Andy FieldDocument34 pagesLogistic Regression: Prof. Andy FieldSyedNo ratings yet
- Statistics Booklet For NEW A Level AQADocument66 pagesStatistics Booklet For NEW A Level AQAMurk NiazNo ratings yet
- Stat LAS 8Document6 pagesStat LAS 8aljun badeNo ratings yet
- Lecture 16 - Logistic Regression For Survey DataDocument25 pagesLecture 16 - Logistic Regression For Survey DataChetan AcharyaNo ratings yet
- Let LetDocument29 pagesLet LetIsaac Daplas RosarioNo ratings yet
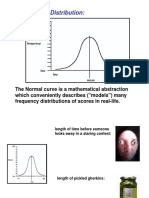
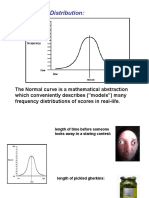
- Normal Distribution 2012Document29 pagesNormal Distribution 2012Isaac Daplas RosarioNo ratings yet
- Chapter 5 HW SolnDocument10 pagesChapter 5 HW SolnthemangoburnerNo ratings yet
- 4.2 StatDocument4 pages4.2 StatrockytokidealsNo ratings yet
- BA20 Session2 MDocument40 pagesBA20 Session2 MAnisha RohatgiNo ratings yet
- Module07 NotesDocument14 pagesModule07 NotesAnonymous na314kKjOANo ratings yet
- Exam 1Document6 pagesExam 1Danien LopesNo ratings yet
- Sampling Distribution and Central Limit Theorem: Session 2Document19 pagesSampling Distribution and Central Limit Theorem: Session 2Anyone SomeoneNo ratings yet
- Statistics 01week 02 PDFDocument35 pagesStatistics 01week 02 PDFAbdullah DsoukyNo ratings yet
- Monte Carlo Simulation: Assignment 1Document13 pagesMonte Carlo Simulation: Assignment 1AmeerUlHaqNo ratings yet
- S Pss by Sajid AlikhanDocument83 pagesS Pss by Sajid AlikhanArsalan TNo ratings yet
- Decision Under UncertanityDocument28 pagesDecision Under UncertanityTheaNo ratings yet
- Simulation and Forecasting Solutions: (From Table) (No. of Cars)Document18 pagesSimulation and Forecasting Solutions: (From Table) (No. of Cars)Debbie DebzNo ratings yet
- Statistical Analysis Using Microsoft ExcelDocument11 pagesStatistical Analysis Using Microsoft ExcelNithi AyyaluNo ratings yet
- Natalie Loxton Data ScreeningDocument36 pagesNatalie Loxton Data ScreeningTuhin DeyNo ratings yet
- QM1 NotesDocument81 pagesQM1 Noteslegion2d4No ratings yet
- Design Space Process Models With Monte Carlo SimulationDocument38 pagesDesign Space Process Models With Monte Carlo Simulationsellerm4c1n2No ratings yet
- Simulation: Intro To Management ScienceDocument29 pagesSimulation: Intro To Management ScienceWaleed AhmadNo ratings yet
- BIDM Session 07-08Document44 pagesBIDM Session 07-08Ajit chowdaryNo ratings yet
- LocationDocument26 pagesLocationChristone “Zuluzulu” ZuluNo ratings yet
- Assignment 6 - Jaime LievanoDocument7 pagesAssignment 6 - Jaime LievanoJaime LievanoNo ratings yet
- Advanced Analysis of Engineering Data: IENG Course ProjectDocument22 pagesAdvanced Analysis of Engineering Data: IENG Course ProjectAbdu AbdoulayeNo ratings yet
- Course: MVDA (Assignment 3) Submitted To: Sir Qalandar Hayat Submitted By: Asif Akbar Roll No: 13254 Class: MBA 6 (Afternoon)Document26 pagesCourse: MVDA (Assignment 3) Submitted To: Sir Qalandar Hayat Submitted By: Asif Akbar Roll No: 13254 Class: MBA 6 (Afternoon)Assi AsifNo ratings yet
- Session 13 - Wednesday 19th OctoberDocument37 pagesSession 13 - Wednesday 19th OctoberSana SoomroNo ratings yet
- Tutorial 1 SolutionsDocument3 pagesTutorial 1 SolutionsBochra SassiNo ratings yet
- Ids Final SolDocument16 pagesIds Final SolHumayun RazaNo ratings yet
- PB0003 Statistics For Management (3 Credits) Assignment 1Document5 pagesPB0003 Statistics For Management (3 Credits) Assignment 1juanda poNo ratings yet
- FT Mba Section 4b Probability SvaDocument26 pagesFT Mba Section 4b Probability Svacons theNo ratings yet
- Everything You Ever Wanted To Know About Statistics: Prof. Andy FieldDocument37 pagesEverything You Ever Wanted To Know About Statistics: Prof. Andy FieldMohan PudasainiNo ratings yet
- Students T-TestDocument3 pagesStudents T-Test이승빈No ratings yet
- Logistic RegressionDocument41 pagesLogistic RegressionMonica100% (1)
- M1112SP IIIb 3Document4 pagesM1112SP IIIb 3Aljon Domingo TabuadaNo ratings yet
- Tutorial Sheet ENDocument29 pagesTutorial Sheet ENValentinNo ratings yet
- Classical Item and Test Analysis Report Hasil Run Kelompok 6Document20 pagesClassical Item and Test Analysis Report Hasil Run Kelompok 6Khinasih NoerwotoNo ratings yet
- M1112SP IIIb 3Document4 pagesM1112SP IIIb 3ALJON TABUADANo ratings yet
- Module10-Hypothesis Testing and Statistical Tools (Business)Document18 pagesModule10-Hypothesis Testing and Statistical Tools (Business)CIELICA BURCANo ratings yet
- Advanced Capital Budgeting 3 CWDocument3 pagesAdvanced Capital Budgeting 3 CWsairad1999No ratings yet
- Practice Exam Paper 1 - SolutionsDocument14 pagesPractice Exam Paper 1 - SolutionsMarcel JonathanNo ratings yet
- 21 StatsLecture 07Document31 pages21 StatsLecture 07Christian Alfred VillenaNo ratings yet
- Assignment #2 - For Statistical SoftwareDocument4 pagesAssignment #2 - For Statistical SoftwareNhatty WeroNo ratings yet
- Session 3 DistribtionDocument61 pagesSession 3 DistribtionSriya Aishwarya TataNo ratings yet
- Tutorial 1 QuestionsDocument7 pagesTutorial 1 Questions马小禾No ratings yet
- Supply & Demand 2Document27 pagesSupply & Demand 2mgpchangNo ratings yet
- Normal Distribution 2012Document29 pagesNormal Distribution 2012kya karegaNo ratings yet
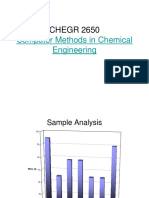
- CHEGR 2650: Computer Methods in Chemical EngineeringDocument27 pagesCHEGR 2650: Computer Methods in Chemical EngineeringNebojsa MihajlovicNo ratings yet
- Sikap KorupsiDocument5 pagesSikap KorupsiRisyah Iriansyah100% (1)
- SM BinningDocument12 pagesSM BinningMerry PurbaNo ratings yet
- Logistic Regression and PyTorch For Deep LearningDocument43 pagesLogistic Regression and PyTorch For Deep LearningHaiping LuNo ratings yet
- Logit, Probit and Multinomial Logit Models in R: Oscar Torres-ReynaDocument27 pagesLogit, Probit and Multinomial Logit Models in R: Oscar Torres-ReynaEsperanzaDazaNo ratings yet
- Bolted Joint 070506Document146 pagesBolted Joint 070506vijay10484No ratings yet
- Lecture 4 - Inferential Statistics - Diff - MeansPart1Document61 pagesLecture 4 - Inferential Statistics - Diff - MeansPart1efkjhNo ratings yet
- Theory of Preliminary Test and Stein-Type Estimation with ApplicationsFrom EverandTheory of Preliminary Test and Stein-Type Estimation with ApplicationsNo ratings yet
- CV PDFDocument1 pageCV PDFAnyone SomeoneNo ratings yet
- CV PDFDocument1 pageCV PDFAnyone SomeoneNo ratings yet
- CV PDFDocument1 pageCV PDFAnyone SomeoneNo ratings yet
- Education Indian School of Business - : IPL FranchiseDocument1 pageEducation Indian School of Business - : IPL FranchiseAnyone SomeoneNo ratings yet
- CV PDFDocument1 pageCV PDFAnyone SomeoneNo ratings yet
- Markstrat Pointers 2 Market AnalysisDocument1 pageMarkstrat Pointers 2 Market AnalysisAnyone SomeoneNo ratings yet
- Amex Discounted PDFDocument2 pagesAmex Discounted PDFAnyone SomeoneNo ratings yet
- Markstrat Pointers 1 Breakeven AnalysisDocument1 pageMarkstrat Pointers 1 Breakeven AnalysisAnyone SomeoneNo ratings yet
- Contact Information and Office HoursDocument4 pagesContact Information and Office HoursAnyone SomeoneNo ratings yet
- The Importance of Self-Esteem: - A Popular Management IdeaDocument4 pagesThe Importance of Self-Esteem: - A Popular Management IdeaAnyone SomeoneNo ratings yet
- Course Objectives: Through People, Using Conceptual Knowledge, Case Studies, andDocument4 pagesCourse Objectives: Through People, Using Conceptual Knowledge, Case Studies, andAnyone SomeoneNo ratings yet
- With The The: A-Lzots / I IB Government of India Niti New DatedDocument2 pagesWith The The: A-Lzots / I IB Government of India Niti New DatedAnyone SomeoneNo ratings yet
- Jeff Immelt, CEO, General ElectricDocument4 pagesJeff Immelt, CEO, General ElectricAnyone SomeoneNo ratings yet
- Q. No. Question Stem Ans Key AnswerDocument1 pageQ. No. Question Stem Ans Key AnswerAnyone SomeoneNo ratings yet
- YP Guidelines 2018 PDFDocument14 pagesYP Guidelines 2018 PDFAnyone SomeoneNo ratings yet
- Management of OrganizationsDocument4 pagesManagement of OrganizationsAnyone SomeoneNo ratings yet
- Apple TNC PDFDocument174 pagesApple TNC PDFAnyone SomeoneNo ratings yet
- Practice QuestionsDocument4 pagesPractice QuestionsAnyone SomeoneNo ratings yet
- AnnualFee PDFDocument1 pageAnnualFee PDFAnyone SomeoneNo ratings yet
- Ahmedabad: City Terminal Lounge Name Discounted Access (In INR) Complimentary AccessDocument2 pagesAhmedabad: City Terminal Lounge Name Discounted Access (In INR) Complimentary AccessAnyone SomeoneNo ratings yet
- Apple TNC PDFDocument174 pagesApple TNC PDFAnyone SomeoneNo ratings yet
- Session2 Demand v2Document61 pagesSession2 Demand v2Anyone SomeoneNo ratings yet
- Financial Accounting For Decision Making (FADM) : ISB 2020-21 Additional Problems For Sessions 1-5Document32 pagesFinancial Accounting For Decision Making (FADM) : ISB 2020-21 Additional Problems For Sessions 1-5Anyone SomeoneNo ratings yet
- Session3 SupplyandcostsDocument74 pagesSession3 SupplyandcostsAnyone SomeoneNo ratings yet
- Government Intervention: MGEC Post Session 3Document42 pagesGovernment Intervention: MGEC Post Session 3Anyone SomeoneNo ratings yet
- Session1 Practice Problems AkDocument2 pagesSession1 Practice Problems AkAnyone SomeoneNo ratings yet
- Questions For Review: Managerial Economics Digital Headstart ModuleDocument1 pageQuestions For Review: Managerial Economics Digital Headstart ModuleAnyone SomeoneNo ratings yet
- Fadm ExamDocument2 pagesFadm ExamAnyone SomeoneNo ratings yet
- Sample Midterm ExamDocument14 pagesSample Midterm ExamAnyone SomeoneNo ratings yet
- (RestoDent) Pathophysiology of CariesDocument30 pages(RestoDent) Pathophysiology of CariesZara Sebastianne Garcia100% (1)
- Seminar Assignment+Presentation Topics - Romeo and JulietDocument4 pagesSeminar Assignment+Presentation Topics - Romeo and JulietfefgheteNo ratings yet
- Reading LatinDocument20 pagesReading LatinJosh GâteauNo ratings yet
- Free State Psychiatric ComplexDocument3 pagesFree State Psychiatric ComplexIce Blade (IceBlade)No ratings yet
- Nail Designing Tools: Grade 10 - Tle Beauty/Nail Care ServicesDocument28 pagesNail Designing Tools: Grade 10 - Tle Beauty/Nail Care ServicesPrecious Joy Torayno BayawaNo ratings yet
- Rising Rates of Divorce in IndiaDocument27 pagesRising Rates of Divorce in IndiaAyushi AgrawalNo ratings yet
- The Nirma StoryDocument15 pagesThe Nirma StoryAnubhav SinghNo ratings yet
- PM-Assignment 4Document23 pagesPM-Assignment 4raheel iqbalNo ratings yet
- IB Physics Topic 2-4 Paper 1 ProblemsDocument20 pagesIB Physics Topic 2-4 Paper 1 Problemswonjunlim0819No ratings yet
- Cash & Cash Equivalents, Lecture &exercisesDocument16 pagesCash & Cash Equivalents, Lecture &exercisesDessa Garong100% (1)
- Grijalva-Lopez v. United States, 543 U.S. 1114 (2005)Document1 pageGrijalva-Lopez v. United States, 543 U.S. 1114 (2005)Scribd Government DocsNo ratings yet
- Understand Your Child's Anxiety: What Is Worry?Document8 pagesUnderstand Your Child's Anxiety: What Is Worry?Sanja ZupaničNo ratings yet
- Gr-12-U-1-L-4-Separation of SpousesDocument5 pagesGr-12-U-1-L-4-Separation of SpouseskawsarNo ratings yet
- Aqa Ms Ss1a W QP Jun13Document20 pagesAqa Ms Ss1a W QP Jun13prsara1975No ratings yet
- ISM400 DatasheetDocument14 pagesISM400 Datasheetankurshah1986No ratings yet
- Respondent MemoDocument34 pagesRespondent Memotanmaya_purohitNo ratings yet
- Aurora N. de Pedro v. Romasan Development CorporationDocument5 pagesAurora N. de Pedro v. Romasan Development CorporationSarah Jane Fabricante BehigaNo ratings yet
- PAST SIMPLE Vs PRESENT PERFECTDocument3 pagesPAST SIMPLE Vs PRESENT PERFECTJosseline HerreraNo ratings yet
- How To Configure PfBlocker - An IP Block List and Country Block Package For PfSenseDocument5 pagesHow To Configure PfBlocker - An IP Block List and Country Block Package For PfSensevalchuks2k1No ratings yet
- Antibiotic Guidelines For AdultsDocument9 pagesAntibiotic Guidelines For AdultsVarshini Tamil SelvanNo ratings yet
- The Transgender Community Living in District Kamber Shahdadkot SindhDocument7 pagesThe Transgender Community Living in District Kamber Shahdadkot SindhnhussainmagsiNo ratings yet
- JNTUK - List of Ratified Principals & Faculty - 10-12 July, 2015Document30 pagesJNTUK - List of Ratified Principals & Faculty - 10-12 July, 2015anon_93356806067% (3)
- Change Your Breakfast Change Your Life PDFDocument189 pagesChange Your Breakfast Change Your Life PDFDrUmeshSharmaNo ratings yet
- Role of Culture in Eyes Open: Ben GoldsteinDocument1 pageRole of Culture in Eyes Open: Ben GoldsteinEkaterinaNo ratings yet
- Aileron Market Balance: Issue 15.1Document1 pageAileron Market Balance: Issue 15.1Dan ShyNo ratings yet
- Need AssesmentDocument15 pagesNeed AssesmentHossain SumonNo ratings yet
- Activity #2Document2 pagesActivity #2ryan rossNo ratings yet
- Vivel - Brand EquityDocument13 pagesVivel - Brand EquityShivkarVishalNo ratings yet
- DesignDocument6 pagesDesignvg_vvg100% (1)