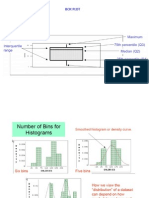
You might also like
- The Practically Cheating Statistics Handbook, The Sequel! (2nd Edition)From EverandThe Practically Cheating Statistics Handbook, The Sequel! (2nd Edition)Rating: 4.5 out of 5 stars4.5/5 (3)
- This is The Statistics Handbook your Professor Doesn't Want you to See. So Easy, it's Practically Cheating...From EverandThis is The Statistics Handbook your Professor Doesn't Want you to See. So Easy, it's Practically Cheating...Rating: 4.5 out of 5 stars4.5/5 (6)
- Point and Interval EstimatesDocument63 pagesPoint and Interval Estimatespkj009No ratings yet
- Final Exam Study GuideDocument11 pagesFinal Exam Study Guidegenius writersNo ratings yet
- Solutions Manual to accompany Introduction to Linear Regression AnalysisFrom EverandSolutions Manual to accompany Introduction to Linear Regression AnalysisRating: 1 out of 5 stars1/5 (1)
- Identifying Plagiarism ActivityDocument2 pagesIdentifying Plagiarism ActivityPedimor Dolor Cabansag0% (1)
- TB Chapter 18 AnswersDocument44 pagesTB Chapter 18 AnswersMahmoudElbehairyNo ratings yet
- 4 Sampling DistributionsDocument30 pages4 Sampling Distributionskristel lina100% (1)
- Unit 3 Z-Scores, Measuring Performance: Learning OutcomeDocument10 pagesUnit 3 Z-Scores, Measuring Performance: Learning OutcomeCheska AtienzaNo ratings yet
- CH 4 - Estimation & Hypothesis One SampleDocument139 pagesCH 4 - Estimation & Hypothesis One SampleDrake AdamNo ratings yet
- 0feaf24f-6a96-4279-97a1-86708e467593 (1)Document7 pages0feaf24f-6a96-4279-97a1-86708e467593 (1)simandharNo ratings yet
- ALEA - Political Science 199.1 Long Exam - October 19, 2022Document11 pagesALEA - Political Science 199.1 Long Exam - October 19, 2022Jon Mikael AleaNo ratings yet
- Sampling and Sampling Distributions (Autosaved)Document74 pagesSampling and Sampling Distributions (Autosaved)Cristina Reynoso Fajardo0% (1)
- IISER BiostatDocument87 pagesIISER BiostatPrithibi Bodle GacheNo ratings yet
- Chem 206 Lab ManualDocument69 pagesChem 206 Lab ManualDouglas DlutzNo ratings yet
- Topic 7Document26 pagesTopic 7Zienab AhmedNo ratings yet
- Chapter 5 Sampling Distributions: InfiniteDocument16 pagesChapter 5 Sampling Distributions: InfiniteNsy noormaeeerNo ratings yet
- Z and T TestsDocument29 pagesZ and T Testscintoy100% (1)
- Confidence Intervals 1Document10 pagesConfidence Intervals 1Elite GroupNo ratings yet
- 4 Sampling Distributions RevisedDocument21 pages4 Sampling Distributions Revisedlogicalbase3498No ratings yet
- Saint Joseph College Senior High School Department Tunga-Tunga, Maasin City, Southern Leyte 6600 PhilippinesDocument11 pagesSaint Joseph College Senior High School Department Tunga-Tunga, Maasin City, Southern Leyte 6600 PhilippinesJimkenneth RanesNo ratings yet
- Chapter 8 Confidence IntervalDocument14 pagesChapter 8 Confidence IntervalFadli Bakhtiar AjiNo ratings yet
- Biometrics 2011 II 7Document16 pagesBiometrics 2011 II 7ESSA GHAZWANINo ratings yet
- Random Variable & Probability DistributionDocument48 pagesRandom Variable & Probability DistributionRISHAB NANGIANo ratings yet
- Week7 Quiz Help 2009Document1 pageWeek7 Quiz Help 2009dtreffnerNo ratings yet
- Formula SheetDocument13 pagesFormula SheetUoloht PutinNo ratings yet
- Normal DistributionDocument45 pagesNormal Distributionvishal yadavNo ratings yet
- UntitledDocument6 pagesUntitledAleesha MontenegroNo ratings yet
- Lecture - 9 EstimationRM (ECON 1005 2011-2012)Document52 pagesLecture - 9 EstimationRM (ECON 1005 2011-2012)Ismadth2918388No ratings yet
- Z and T TestsDocument30 pagesZ and T TestsMohamed NaeimNo ratings yet
- Ken Black QA 5th Chapter 8 SolutionDocument32 pagesKen Black QA 5th Chapter 8 SolutionRushabh VoraNo ratings yet
- PPT08-Confidence Interval EstimationDocument22 pagesPPT08-Confidence Interval Estimationairwan hryNo ratings yet
- Discussion1 SolutionDocument5 pagesDiscussion1 Solutionana_paciosNo ratings yet
- Inferences Based On A Single Sample: Confidence Intervals and Tests of Hypothesis (9 Hours)Document71 pagesInferences Based On A Single Sample: Confidence Intervals and Tests of Hypothesis (9 Hours)Kato AkikoNo ratings yet
- Module 7 Sampling DistributionDocument22 pagesModule 7 Sampling DistributionvanessaNo ratings yet
- Graded Homework 11 1Document19 pagesGraded Homework 11 1Hunter ChastainNo ratings yet
- 10 Estimation 21022024 081610pmDocument50 pages10 Estimation 21022024 081610pmTehreem BukhariNo ratings yet
- Interval Estimation: ASW, Chapter 8Document23 pagesInterval Estimation: ASW, Chapter 8justinepaz1984No ratings yet
- Margin of ErrorDocument6 pagesMargin of ErrorFaith Febe AustriaNo ratings yet
- Estimation at Confidence Intervals For One Population MeanDocument24 pagesEstimation at Confidence Intervals For One Population MeanMohd Nazri OthmanNo ratings yet
- CH 8-Statistical Inference Estimation For Single PopulationDocument42 pagesCH 8-Statistical Inference Estimation For Single PopulationVishal Limbachiya50% (2)
- Chapter 07Document59 pagesChapter 07Osama SamhaNo ratings yet
- PT Module5Document30 pagesPT Module5Venkat BalajiNo ratings yet
- Sampling TheoryDocument22 pagesSampling TheorySHAIK MAHAMMED RAFFINo ratings yet
- Estimation 1Document35 pagesEstimation 1Fun Toosh345No ratings yet
- Statistical Analysis (T-Test)Document61 pagesStatistical Analysis (T-Test)Symoun BontigaoNo ratings yet
- Seatwork 3Document2 pagesSeatwork 3ranezaliakayeNo ratings yet
- 4 - Statistik DeskriptifDocument33 pages4 - Statistik DeskriptifDhe NurNo ratings yet
- Estimation of ParametersDocument87 pagesEstimation of ParametersAlfredNo ratings yet
- GRMD2102 - Homework 3 - With - AnswerDocument5 pagesGRMD2102 - Homework 3 - With - Answerluk.wingwing620No ratings yet
- L5 Sample Size CalculationDocument23 pagesL5 Sample Size CalculationMarshet SetegnNo ratings yet
- Sampling and EstimationDocument36 pagesSampling and EstimationKUA JIEN BINNo ratings yet
- Statistics ReviewerDocument5 pagesStatistics ReviewerMav CastilloNo ratings yet
- Sample Size DeterminationDocument20 pagesSample Size DeterminationSamrat Chowdhury100% (1)
- MATH 52540 (CHAPTERS 10-12 Worksheet)Document6 pagesMATH 52540 (CHAPTERS 10-12 Worksheet)sarkarigamingytNo ratings yet
- Lc07 SL Estimation - PPT - 0Document48 pagesLc07 SL Estimation - PPT - 0Deni ChanNo ratings yet
- Ch04le 1Document59 pagesCh04le 1Jose TrianoNo ratings yet
- Confidence IntervalDocument20 pagesConfidence IntervalriganNo ratings yet
- Confidence Interval EstimationDocument62 pagesConfidence Interval EstimationVikrant LadNo ratings yet
- Sampling Distribution Revised For IBS 2020 BatchDocument48 pagesSampling Distribution Revised For IBS 2020 Batchnandini swamiNo ratings yet
- Sampling DistributionDocument13 pagesSampling DistributionBilal AliNo ratings yet
- Dear Professor SmithDocument1 pageDear Professor SmithIdris IbrahimovNo ratings yet
- Describe A Film or TV Show That Made You LaughDocument1 pageDescribe A Film or TV Show That Made You LaughIdris IbrahimovNo ratings yet
- Environmental Pollution and Waste Management: January 2015Document10 pagesEnvironmental Pollution and Waste Management: January 2015Idris IbrahimovNo ratings yet
- Do People Like Comedy?Document1 pageDo People Like Comedy?Idris IbrahimovNo ratings yet
- Ielts 1Document1 pageIelts 1Idris IbrahimovNo ratings yet
- Ielts 12Document1 pageIelts 12Idris IbrahimovNo ratings yet
- Worksheet - Skills, Interests and Values Matching Idris IbrahimovDocument6 pagesWorksheet - Skills, Interests and Values Matching Idris IbrahimovIdris IbrahimovNo ratings yet
- Dear Professor SmithDocument1 pageDear Professor SmithIdris IbrahimovNo ratings yet
- AP Biology Name - Date - : ActivityDocument4 pagesAP Biology Name - Date - : ActivityIdris IbrahimovNo ratings yet
- Dove CaseDocument2 pagesDove CaseAmeya0% (1)
- 1) Hi Everyone. Today We Start A New Chapter Which Is Dedicated To Pumps. in ThisDocument4 pages1) Hi Everyone. Today We Start A New Chapter Which Is Dedicated To Pumps. in ThisIdris IbrahimovNo ratings yet
- Research Questions: Academic Writing Dr. Vafa YunusovaDocument12 pagesResearch Questions: Academic Writing Dr. Vafa YunusovaIdris IbrahimovNo ratings yet
- $RRJT833Document14 pages$RRJT833Idris IbrahimovNo ratings yet
- Metric Basic Units and Prefixes: Example Exercise 2.1Document42 pagesMetric Basic Units and Prefixes: Example Exercise 2.1Idris Ibrahimov100% (1)
- Present in The Environment. Natural Gases Global Warming: Quick Summarywith StoriesDocument2 pagesPresent in The Environment. Natural Gases Global Warming: Quick Summarywith StoriesIdris IbrahimovNo ratings yet
- Leadership 1Document1 pageLeadership 1Idris IbrahimovNo ratings yet
- Classification Essay (Idris Ibrahimov)Document3 pagesClassification Essay (Idris Ibrahimov)Idris IbrahimovNo ratings yet
- Part A: Rows Will Represent Fund Type and Columns Will Show 5 Year Average Return, AccordinglyDocument7 pagesPart A: Rows Will Represent Fund Type and Columns Will Show 5 Year Average Return, AccordinglyIdris IbrahimovNo ratings yet
- How To Write Analysis Paper?: Agenda HousekeepingDocument13 pagesHow To Write Analysis Paper?: Agenda HousekeepingIdris IbrahimovNo ratings yet
- HODocument3 pagesHOIdris IbrahimovNo ratings yet
- Guest Registration FormDocument1 pageGuest Registration FormIdris IbrahimovNo ratings yet
- Dialnet TheImpactOfUsingSocialMediaOnAcademicAchievementAn 6233578 PDFDocument8 pagesDialnet TheImpactOfUsingSocialMediaOnAcademicAchievementAn 6233578 PDFIdris IbrahimovNo ratings yet
- Holistic Participation RubricDocument2 pagesHolistic Participation RubricIdris IbrahimovNo ratings yet
- Evaluating SourcesDocument1 pageEvaluating SourcesIdris IbrahimovNo ratings yet
- $RVM7ZD6Document2 pages$RVM7ZD6Idris IbrahimovNo ratings yet
- Unit 2 Material AcademicDocument31 pagesUnit 2 Material AcademicIdris IbrahimovNo ratings yet
- Argumentative Essay 2Document4 pagesArgumentative Essay 2Idris IbrahimovNo ratings yet
- Impact of CSR-Relevant News On Stock Prices of Companies Listed in The Austrian Traded Index (ATX)Document18 pagesImpact of CSR-Relevant News On Stock Prices of Companies Listed in The Austrian Traded Index (ATX)Idris IbrahimovNo ratings yet
- Impact of Social Media On Students' Academic Performance & Generation Gap: A Study of Public Sector University in PunjabDocument7 pagesImpact of Social Media On Students' Academic Performance & Generation Gap: A Study of Public Sector University in PunjabIdris IbrahimovNo ratings yet
- Metode Analisis Perencanaan I (MAP I) : Fika Febi Novianti (2018280030)Document6 pagesMetode Analisis Perencanaan I (MAP I) : Fika Febi Novianti (2018280030)fika febiNo ratings yet
- Analysis of VarianceDocument18 pagesAnalysis of Variancemia farrowNo ratings yet
- Quantitaive Research PaperDocument21 pagesQuantitaive Research PaperLenox LopezNo ratings yet
- Chapter 17 Correlation and RegressionDocument16 pagesChapter 17 Correlation and RegressionKANIKA GORAYANo ratings yet
- The Aligned Rank Transform For Nonparametric Factorial Analyses Using Only A NOVA ProceduresDocument4 pagesThe Aligned Rank Transform For Nonparametric Factorial Analyses Using Only A NOVA ProceduresAsura NephilimNo ratings yet
- ME Project: Price Elasticity of Sugar Industry AND ITS Implication ON Total RevenueDocument26 pagesME Project: Price Elasticity of Sugar Industry AND ITS Implication ON Total RevenueAshutosh BurnwalNo ratings yet
- Types of Research MethodsDocument18 pagesTypes of Research MethodsYanna Marie Porlucas MacaraegNo ratings yet
- ASTM E 876 - 89 R94 - SPfor Use of Statistics in The Evaluation of Spectrometric DataDocument17 pagesASTM E 876 - 89 R94 - SPfor Use of Statistics in The Evaluation of Spectrometric DataAndreea Bratu100% (1)
- Financial Performance of Tancem Cement Company in Tamil Nadu - A StudyDocument8 pagesFinancial Performance of Tancem Cement Company in Tamil Nadu - A StudyIAEME PublicationNo ratings yet
- Random Motors BriefingDocument43 pagesRandom Motors BriefingAndy KumarNo ratings yet
- II IDocument74 pagesII IJM pajenagoNo ratings yet
- Bootstrapping The Autoregressive Distributed Lag Test For Cointegration Bootstrapping The Autoregressive Distributed Lag Test For CointegrationDocument15 pagesBootstrapping The Autoregressive Distributed Lag Test For Cointegration Bootstrapping The Autoregressive Distributed Lag Test For CointegrationsamueljlNo ratings yet
- Methods of Research Calmorin Chapter 4 Part IIDocument62 pagesMethods of Research Calmorin Chapter 4 Part IIPeter GonzagaNo ratings yet
- Teaching Competency of Nursing Educators and Caring Attitude of Nursing Students in A Philippine UniversityDocument65 pagesTeaching Competency of Nursing Educators and Caring Attitude of Nursing Students in A Philippine UniversityJaine NicolleNo ratings yet
- Nama: Inneke Ariesta Wardhani NIM: 2015031233 Supevisor: Dr. Choirul Anwar, MBA, MAFIS, MCIS, CPADocument18 pagesNama: Inneke Ariesta Wardhani NIM: 2015031233 Supevisor: Dr. Choirul Anwar, MBA, MAFIS, MCIS, CPAinneke ariestaNo ratings yet
- To Run ANOVADocument2 pagesTo Run ANOVAalohaNo ratings yet
- Regression Model For Bearing Capacity of A Square Footing On Reinforced Pond AshDocument25 pagesRegression Model For Bearing Capacity of A Square Footing On Reinforced Pond Ashsudhakar mNo ratings yet
- Ebook PDF Understanding Business Statistics 1st Edition PDFDocument41 pagesEbook PDF Understanding Business Statistics 1st Edition PDFrichard.rogers744100% (30)
- Exercises Chapter 2Document8 pagesExercises Chapter 2Zyad SayarhNo ratings yet
- Factors Responsible For Students' Lateness To School As Expressed by Nigerian Teachers in Elementary SchoolsDocument13 pagesFactors Responsible For Students' Lateness To School As Expressed by Nigerian Teachers in Elementary SchoolsCarlo SanchezNo ratings yet
- THESIS SUMMARY - Akhsa Sinaga - 008201400007Document15 pagesTHESIS SUMMARY - Akhsa Sinaga - 008201400007Andreas SebastianNo ratings yet
- Application of Smooth Transition Autoregressive (STAR) Models For Exchange RateDocument10 pagesApplication of Smooth Transition Autoregressive (STAR) Models For Exchange Ratedecker4449No ratings yet
- Stat 5 T Test F Test Z Test Chi Square Test PDFDocument20 pagesStat 5 T Test F Test Z Test Chi Square Test PDFRavi Kumar100% (1)
- ECO 231 Empirical Project Mets AttendanceDocument21 pagesECO 231 Empirical Project Mets Attendancemulcahk1No ratings yet
- Factors Influencing Unemployment Rate A ComparisonDocument9 pagesFactors Influencing Unemployment Rate A ComparisongalihNo ratings yet
- Market Research Project Report: Footwear Industry DifferentiationDocument40 pagesMarket Research Project Report: Footwear Industry Differentiationmahtaabk90% (10)
- Ombc 106 Research Methodologies J 22Document27 pagesOmbc 106 Research Methodologies J 22Celsozeca2011No ratings yet
- Body-Piercing-and-Tattoos-Survey-on-peoples-Health-Risk-and-perception-in-Body-arts (Recent)Document84 pagesBody-Piercing-and-Tattoos-Survey-on-peoples-Health-Risk-and-perception-in-Body-arts (Recent)Lala LaurNo ratings yet
- Discovering Statistics Using Ibm Spss Statistics Field 4th Edition Test BankDocument36 pagesDiscovering Statistics Using Ibm Spss Statistics Field 4th Edition Test Bankstevenleexofjbnszet100% (25)