You might also like
- Saturday Night PDFDocument106 pagesSaturday Night PDFJamie Jones100% (5)
- PL2 2022-23 Handbook Update 09.22Document29 pagesPL2 2022-23 Handbook Update 09.22Soul Central Magazine ExtraNo ratings yet
- Laura Ashley CatalogueDocument9 pagesLaura Ashley Cataloguestephanie_lawso4203No ratings yet
- Into The OddDocument24 pagesInto The OddBrandon E. Paul100% (1)
- Cross Talk 48Document44 pagesCross Talk 48jodiebritt100% (1)
- Englis EssayDocument7 pagesEnglis Essayapi-305189614No ratings yet
- FIFA 19 IDsDocument280 pagesFIFA 19 IDsGaurav BhatiaNo ratings yet
- Title: Data Wrangling (Data Preprocessing) : I. Students' DetailsDocument6 pagesTitle: Data Wrangling (Data Preprocessing) : I. Students' DetailsNguyễn Công HậuNo ratings yet
- Data Wrangling (Data Preprocessing) : Practical Assessment 1Document5 pagesData Wrangling (Data Preprocessing) : Practical Assessment 1Nguyễn Công HậuNo ratings yet
- Sampling TitanicDocument49 pagesSampling TitanicCyd DuqueNo ratings yet
- Far Rockaway Train ScheduleDocument1 pageFar Rockaway Train ScheduleanthonybottanNo ratings yet
- Tugas DS: Nurzulhijjah 4/10/2020Document7 pagesTugas DS: Nurzulhijjah 4/10/2020nurnzhNo ratings yet
- BroomspatialDocument31 pagesBroomspatialHolaq Ola OlaNo ratings yet
- Bulletin 01Document18 pagesBulletin 01slNo ratings yet
- Pda Da 2Document4 pagesPda Da 2karthikwork72No ratings yet
- Obsession Board Game DecksDocument23 pagesObsession Board Game DecksDavid JensenNo ratings yet
- D&D 3.5e - Forgotten Realms - Dragons of Faerun (Wtc953797200)Document160 pagesD&D 3.5e - Forgotten Realms - Dragons of Faerun (Wtc953797200)Arthur Hugen100% (4)
- Kinh tế lượng code RDocument10 pagesKinh tế lượng code RNgọc Quỳnh Anh NguyễnNo ratings yet
- Home 18 Knittable Projects To Keep You ComfyDocument100 pagesHome 18 Knittable Projects To Keep You ComfyRoxana Popa100% (3)
- The Cove Crochet Blanket UK Terms: A pick your path pattern inspired by coastal adventuresFrom EverandThe Cove Crochet Blanket UK Terms: A pick your path pattern inspired by coastal adventuresNo ratings yet
- Marek Kwiatkowski - 100 Polish Threemovers (1893-1992)Document37 pagesMarek Kwiatkowski - 100 Polish Threemovers (1893-1992)Ian SantiniNo ratings yet
- King Arthur SpamalotDocument15 pagesKing Arthur Spamalotsasavujisic100% (1)
- Seguimiento de JugadoresDocument9 pagesSeguimiento de Jugadoresrafaelzarate7No ratings yet
- Hardest User Coins LeaderboardDocument45 pagesHardest User Coins LeaderboardBeikeiNo ratings yet
- # Setting The Working Directory: Root - DirDocument9 pages# Setting The Working Directory: Root - Dirapi-602248023No ratings yet
- BlazeDocument7 pagesBlazeAll Super FactsNo ratings yet
- Export Holdem Manager 2.0 08192016072104Document325 pagesExport Holdem Manager 2.0 08192016072104mrNo ratings yet
- ? Bear Bruno ?Document18 pages? Bear Bruno ?Mitzy Zubía100% (1)
- Virtual Impuzzibilities Jim SteinmeyerDocument41 pagesVirtual Impuzzibilities Jim SteinmeyerVeit Schäfermeier100% (2)
- Tugas 4Document1,104 pagesTugas 4MaysiraitNo ratings yet
- PROBLEMAS Abril 2023Document32 pagesPROBLEMAS Abril 2023Gustavo TriviñoNo ratings yet
- C2COceanWavesCrochetPattern-PixelCrochet 1709271121898Document9 pagesC2COceanWavesCrochetPattern-PixelCrochet 1709271121898pearl ikebuakuNo ratings yet
- ClassesDocument1 pageClassesEtienne de GrootNo ratings yet
- Sample Basic HoroscopeDocument15 pagesSample Basic HoroscopePrasannaNo ratings yet
- Bracket & Corbel DesignDocument11 pagesBracket & Corbel DesignSYED FAROOQUDDINNo ratings yet
- Soccer News 1948 July 3Document4 pagesSoccer News 1948 July 3markboricNo ratings yet
- Livshitz August Test Your Chess Iq Grandmaster ChallengeDocument139 pagesLivshitz August Test Your Chess Iq Grandmaster ChallengeTickle AccountNo ratings yet
- (D (KK) % (XF - KR) : Lkeku Funsz'K %Document8 pages(D (KK) % (XF - KR) : Lkeku Funsz'K %tax kumarNo ratings yet
- 1989 Duke OffenseDocument212 pages1989 Duke Offensepaakk100% (1)
- Careless NavigatorDocument1 pageCareless NavigatorcanterburyparkNo ratings yet
- Doc154705823 625439058Document20 pagesDoc154705823 625439058Carlos MarquezNo ratings yet
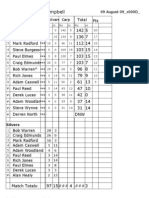
- Campbell AugDocument2 pagesCampbell AugpsvfishingNo ratings yet
- RM - 40 June 2010Document12 pagesRM - 40 June 2010Anonymous kdqf49qbNo ratings yet
- Celik Cekme BoruDocument14 pagesCelik Cekme BorugrtryuNo ratings yet
- LuluthefoxenglishpatternDocument19 pagesLuluthefoxenglishpatternkerryrobsonstevensonNo ratings yet
- What Are Decision Trees?Document9 pagesWhat Are Decision Trees?eng_mahesh1012No ratings yet
- Beatlesguitar 140122060256 Phpapp01 PDFDocument211 pagesBeatlesguitar 140122060256 Phpapp01 PDFDfm Marco100% (3)
- Pokédex: Lilian Besson January 12, 2018Document159 pagesPokédex: Lilian Besson January 12, 2018Justine DominicNo ratings yet
- Forest OracleDocument36 pagesForest OracleNick Jenkins100% (11)
- 175 Chess BrillianciesDocument210 pages175 Chess BrillianciesManijak999No ratings yet
- True Crime With Aphrodite Jones S3 Ep 03 930057TXDocument66 pagesTrue Crime With Aphrodite Jones S3 Ep 03 930057TXpianinocskaNo ratings yet
- 6 Themepark Lab DDLDocument16 pages6 Themepark Lab DDLNUR AININ SOFIYA OMARNo ratings yet
- Coding AnDocument19 pagesCoding AnDimas D. WijayantoNo ratings yet
- List - Jenna.500 Film ++Document12 pagesList - Jenna.500 Film ++Rahadian AldyNo ratings yet
- Mermaid Puppy - Pattern by La Pandustria©Document6 pagesMermaid Puppy - Pattern by La Pandustria©FlorelisaNo ratings yet
- Sting TarotDocument10 pagesSting TarotbaaacccddNo ratings yet
- Peppers PrideDocument1 pagePeppers PridecanterburyparkNo ratings yet
- Waldorf PatternsDocument10 pagesWaldorf PatternstamaraiivanaNo ratings yet
- Pages From B651640001A-Tasman Sea 21-79 - REV120711Document1 pagePages From B651640001A-Tasman Sea 21-79 - REV120711Marko BrnasNo ratings yet
- Permutation Reso SheetDocument66 pagesPermutation Reso SheetAshwani Kumar Singh100% (1)
- I L I T I 1 : M FS April200SDocument31 pagesI L I T I 1 : M FS April200SAnonymous kprzCiZNo ratings yet
- ES Technical MasterclassDocument33 pagesES Technical MasterclassChris Holt100% (2)
- Postcode Guide Great LondonDocument2 pagesPostcode Guide Great LondonnotadosNo ratings yet
- Football Tips Today's Football Betting TipsDocument1 pageFootball Tips Today's Football Betting TipsjohnNo ratings yet
- EFL League OneDocument9 pagesEFL League OneSashimiTourloublancNo ratings yet
- EPL Fixtures1314Document15 pagesEPL Fixtures1314praneeshobNo ratings yet
- Burnley: PREMIER LEAGUE 2019/2020Document16 pagesBurnley: PREMIER LEAGUE 2019/2020Daniel RhodesNo ratings yet
- Week 31Document1 pageWeek 31igbafaraphaelNo ratings yet
- Derby FCDocument20 pagesDerby FChbNo ratings yet
- Non League Paper Fantasy FootballDocument1 pageNon League Paper Fantasy FootballEastleigh FCNo ratings yet
- Sheffield United FCDocument18 pagesSheffield United FCDaniel RhodesNo ratings yet
- MPDFDocument7 pagesMPDFYves galor OkogoNo ratings yet
- Bet9ja Nigeria Sport Betting, Premier League Odds, Casino, Bet 3Document1 pageBet9ja Nigeria Sport Betting, Premier League Odds, Casino, Bet 3gabrielwantu37No ratings yet
- 98-99 EplDocument9 pages98-99 EplChristos CharalampousNo ratings yet
- BETWGB Pool CodeDocument1 pageBETWGB Pool CodeAkande JoshuaNo ratings yet
- Map TeamsDocument9 pagesMap Teamsfruters.bayuNo ratings yet
- LiverpoolDocument16 pagesLiverpoolLasc Roxana100% (1)
- Manchester United-Kevin BrophyDocument23 pagesManchester United-Kevin BrophyAhmed AljohaniNo ratings yet
- 1ptv x114Document63 pages1ptv x114Carlos Corredor ZapataNo ratings yet
- History of Football in EnglandDocument17 pagesHistory of Football in EnglandAndrei ZvoNo ratings yet
- FbaDocument6 pagesFbaMeshach SamuelNo ratings yet
- 93-94 EplDocument8 pages93-94 EplChristos CharalampousNo ratings yet
- Premier League: I. A Short BriefDocument6 pagesPremier League: I. A Short BriefBăng Thiên NguyệtNo ratings yet
- ITV Map SOUTH EAST MACRODocument1 pageITV Map SOUTH EAST MACROMihoviikNo ratings yet
- Aston VilaDocument3 pagesAston VilaMehaNo ratings yet
- Div Date Time Hometeam Awayteam FTHG Ftag FTR HTHG Htag HTRDocument18 pagesDiv Date Time Hometeam Awayteam FTHG Ftag FTR HTHG Htag HTRakshay guptaNo ratings yet
- Feb 2012Document7 pagesFeb 2012Paul CookNo ratings yet
- SUBOTA 26.09.2015: NogometDocument56 pagesSUBOTA 26.09.2015: NogometDaniel VuletaNo ratings yet