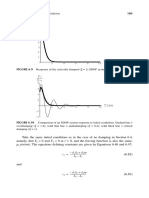
You might also like
- ECES521 Fall2022 Weber Lecture1WDocument6 pagesECES521 Fall2022 Weber Lecture1WthejeshNo ratings yet
- ProbabilityDocument42 pagesProbabilitysalehNo ratings yet
- Stat230 Chapter03Document30 pagesStat230 Chapter03Maya Abdul HusseinNo ratings yet
- Discrete Mathematics, Second Edition: Jean GallierDocument39 pagesDiscrete Mathematics, Second Edition: Jean GallierSihabSahariarSizanNo ratings yet
- Seeing TheoryDocument66 pagesSeeing TheoryJohn AvgerinosNo ratings yet
- Handouts Probability IitDocument9 pagesHandouts Probability IitAnanya SinghNo ratings yet
- PagbasaDocument6 pagesPagbasaMichael Angelo Baldosano VocalNo ratings yet
- Basic ProbabilityDocument16 pagesBasic ProbabilityganeshNo ratings yet
- MIT18 05S14 Reading2Document6 pagesMIT18 05S14 Reading2Jesha Carl JotojotNo ratings yet
- Chapter 5Document33 pagesChapter 5aisyahazaliNo ratings yet
- Basic ProbabilityDocument14 pagesBasic Probabilityzhilmil guptaNo ratings yet
- Probability Theory: Probability Spaces and EventsDocument16 pagesProbability Theory: Probability Spaces and EventsrasaramanNo ratings yet
- Probability Theory: 1. Probability Spaces and EventsDocument15 pagesProbability Theory: 1. Probability Spaces and EventsHasssanNo ratings yet
- Probabilities and Random Variables: 1 The Probability SpaceDocument8 pagesProbabilities and Random Variables: 1 The Probability SpaceilhammkaNo ratings yet
- ProbabilityDocument34 pagesProbabilityTom Harvey EnajeNo ratings yet
- Math Prob Slinker Measure Theory Infinite HeadsDocument8 pagesMath Prob Slinker Measure Theory Infinite HeadsPrez H. CannadyNo ratings yet
- ProbablityDocument312 pagesProbablityernest104100% (1)
- ProbabilityLectureNotes (MSD) 1Document9 pagesProbabilityLectureNotes (MSD) 1MrigankaNo ratings yet
- Theory of ProbabilityDocument13 pagesTheory of ProbabilityAbolaji AdeolaNo ratings yet
- MIT6 436JF08 Lec01 PDFDocument13 pagesMIT6 436JF08 Lec01 PDFIam MeNo ratings yet
- Prob MIT LecturesDocument240 pagesProb MIT LecturesÀlex RodriguezNo ratings yet
- Introduction To Propabilty TheoryDocument19 pagesIntroduction To Propabilty TheoryNaol WorkuNo ratings yet
- Probability.: Def. Experiment An Is An Activity With Observable Results That Involve Chance or ProbabilityDocument22 pagesProbability.: Def. Experiment An Is An Activity With Observable Results That Involve Chance or ProbabilityWALTER DAVE AGONOYNo ratings yet
- Stochastic Calculus For Finance II ContiDocument99 pagesStochastic Calculus For Finance II ContisumNo ratings yet
- Stat Module Week 1 2Document34 pagesStat Module Week 1 2mertoelaineNo ratings yet
- Random VariableDocument19 pagesRandom VariableGemver Baula BalbasNo ratings yet
- Lecture 3Document35 pagesLecture 3john phol belenNo ratings yet
- Module 2 (Updated)Document71 pagesModule 2 (Updated)Kassy MondidoNo ratings yet
- Unit - I Theory of ProbabilityDocument27 pagesUnit - I Theory of ProbabilitypunithrajNo ratings yet
- MSO201 Week 3 Lecture NotesDocument13 pagesMSO201 Week 3 Lecture NotesKevalNo ratings yet
- محاضرة 3 ORDocument18 pagesمحاضرة 3 ORfsherif423No ratings yet
- Department of Mathematics and Statistics: Statistics For Physical Sciences - Lecture NotesDocument32 pagesDepartment of Mathematics and Statistics: Statistics For Physical Sciences - Lecture NotesGustavo G Borzellino CNo ratings yet
- Shreve Stochcal4fin 2Document99 pagesShreve Stochcal4fin 2Frédéric BlaisNo ratings yet
- STA642 Handouts Topic 1 To 187 by Mahar Afaq Safdar MuhammadDocument1,739 pagesSTA642 Handouts Topic 1 To 187 by Mahar Afaq Safdar Muhammadhumairamubarak2001No ratings yet
- MSO201 Week1 Lecture NotesDocument7 pagesMSO201 Week1 Lecture NotesKevalNo ratings yet
- Probability and Probability DistributionsDocument24 pagesProbability and Probability DistributionsShubham JadhavNo ratings yet
- Probability Theory: 1 Heuristic IntroductionDocument17 pagesProbability Theory: 1 Heuristic IntroductionEpic WinNo ratings yet
- Introduction To Probability and Statistics: 1.1 Random Experiments, Outcomes, EventsDocument8 pagesIntroduction To Probability and Statistics: 1.1 Random Experiments, Outcomes, EventsShreetama BhattacharyaNo ratings yet
- Maths Probability LNDocument114 pagesMaths Probability LNRahul SharmaNo ratings yet
- Statistics Week 1Document21 pagesStatistics Week 1Kristine Angela AbelardeNo ratings yet
- Chapter 5 Discrete Probability Distributions: Definition. If The Random VariableDocument9 pagesChapter 5 Discrete Probability Distributions: Definition. If The Random VariableSolomon Risty CahuloganNo ratings yet
- Mathematics 10 Study Guide Permutation and Factorial Factorial of A NumberDocument10 pagesMathematics 10 Study Guide Permutation and Factorial Factorial of A NumberMc joey NavarroNo ratings yet
- Introduction To Financial MathematicsDocument47 pagesIntroduction To Financial MathematicsTu ShirotaNo ratings yet
- Chapter 5 Probability and Discrete Probability Distributions 5.1 Basic DefinitionsDocument8 pagesChapter 5 Probability and Discrete Probability Distributions 5.1 Basic Definitionskyle cheungNo ratings yet
- Types of Random VariablesDocument9 pagesTypes of Random VariablesPutri Rania AzzahraNo ratings yet
- Probability of Compound Events LasDocument2 pagesProbability of Compound Events LasJas AntoniNo ratings yet
- SC612 Lec10Document21 pagesSC612 Lec10varshilshah2003No ratings yet
- Stat IIa 2011 PDFDocument212 pagesStat IIa 2011 PDFT.A. MirzaNo ratings yet
- Lecture 1 Chapter 2Document7 pagesLecture 1 Chapter 2azm_zubairsahniNo ratings yet
- ProbabilityDocument12 pagesProbabilityAbdullah MuzammilNo ratings yet
- Lecture Notes On Stochastic Calculus (NYU)Document138 pagesLecture Notes On Stochastic Calculus (NYU)joydrambles100% (2)
- Probability 1Document74 pagesProbability 1Seung Yoon LeeNo ratings yet
- Probability Theory Notes Set 1Document21 pagesProbability Theory Notes Set 1Aguta DanNo ratings yet
- Stochastic Systems Chapter 1-2Document110 pagesStochastic Systems Chapter 1-2Arif BillahNo ratings yet
- MODULE 1 - Random Variables and Probability DistributionsDocument12 pagesMODULE 1 - Random Variables and Probability DistributionsJimkenneth RanesNo ratings yet
- NJC Probability Lecture Notes Student EditionDocument14 pagesNJC Probability Lecture Notes Student EditionbhimabiNo ratings yet
- All Ex SolDocument43 pagesAll Ex SolJitendra K JhaNo ratings yet
- Lesson 1 Exploring Random VariablesDocument59 pagesLesson 1 Exploring Random VariablesAlice RiveraNo ratings yet
- ProbabilityDocument41 pagesProbabilityArchit JainNo ratings yet
- LKJGGDVVJHDocument6 pagesLKJGGDVVJHT CNo ratings yet
- VBNMXXSGGDFDocument6 pagesVBNMXXSGGDFT CNo ratings yet
- GHJJFFDFVHDocument6 pagesGHJJFFDFVHT CNo ratings yet
- CVNNXSDFDocument6 pagesCVNNXSDFT CNo ratings yet
- FhhgtuffDocument6 pagesFhhgtuffT CNo ratings yet
- PrefaceDocument6 pagesPrefaceT CNo ratings yet
- 2.4.2 Specific Volume and Density: Thermal Principles-A Review of FundamentalsDocument6 pages2.4.2 Specific Volume and Density: Thermal Principles-A Review of FundamentalsT CNo ratings yet
- 2.11 Third Law of Thermodynamics: PT S VDocument6 pages2.11 Third Law of Thermodynamics: PT S VT CNo ratings yet
- Evaporator.: Refrigeration and Air ConditioningDocument6 pagesEvaporator.: Refrigeration and Air ConditioningT CNo ratings yet
- Refrigeration and Air Conditioning: 1.3.6 Solar Energy Based Refrigeration SystemsDocument7 pagesRefrigeration and Air Conditioning: 1.3.6 Solar Energy Based Refrigeration SystemsT CNo ratings yet
- WWW - Learnengineering.In: MechanismDocument7 pagesWWW - Learnengineering.In: MechanismT CNo ratings yet
- WWW - Learnengineering.In: Me Echan NismDocument7 pagesWWW - Learnengineering.In: Me Echan NismT CNo ratings yet
- WWW - Learnengineering.In: MechanismDocument7 pagesWWW - Learnengineering.In: MechanismT CNo ratings yet
- WWW - Learnengineering.In: MechanismDocument7 pagesWWW - Learnengineering.In: MechanismT CNo ratings yet
- Continuous Probability Densities: 2.1 Simulation of Continuous ProbabilitiesDocument6 pagesContinuous Probability Densities: 2.1 Simulation of Continuous ProbabilitiesT CNo ratings yet
- Solved According To Your Preferences Do The Following Pairs of ProductsDocument1 pageSolved According To Your Preferences Do The Following Pairs of ProductsM Bilal SaleemNo ratings yet
- Admission Requirements For Candidates With Wassce/Sssce A' Level, Abce/Gbce, MatureDocument23 pagesAdmission Requirements For Candidates With Wassce/Sssce A' Level, Abce/Gbce, Maturede eagleNo ratings yet
- Quant WS Oct 4Document2 pagesQuant WS Oct 4Time DehradunNo ratings yet
- Linear ElasticityDocument10 pagesLinear Elasticityaishwarya25singhNo ratings yet
- Research Aptitude TestDocument14 pagesResearch Aptitude TestMaths CTNo ratings yet
- Spe 10067 MS PDFDocument21 pagesSpe 10067 MS PDFManuel ChNo ratings yet
- Cambridge IGCSE: MATHEMATICS 0580/33Document20 pagesCambridge IGCSE: MATHEMATICS 0580/33Hussain JassimNo ratings yet
- Manual JCLDocument15 pagesManual JCLivanslesNo ratings yet
- MCA SyllabusDocument38 pagesMCA Syllabusvijayrugi99No ratings yet
- FOC Lab ManualDocument114 pagesFOC Lab Manualsivadba345No ratings yet
- Bend Stretch Forming AluminumDocument8 pagesBend Stretch Forming AluminumMomoNo ratings yet
- Henry System of Classification 14Document1 pageHenry System of Classification 14Ellen Jane GatdulaNo ratings yet
- Alkali Surfactant Polymer (ASP) Process For Shaley Formation With PyriteDocument24 pagesAlkali Surfactant Polymer (ASP) Process For Shaley Formation With PyriteAlexandra Katerine LondoñoNo ratings yet
- Holmquist (2011) A Computational Constitutive Model For Glass Subjected To Large Strains. High Strain Rates and High PressuresDocument9 pagesHolmquist (2011) A Computational Constitutive Model For Glass Subjected To Large Strains. High Strain Rates and High PressuresluisfmpereiraNo ratings yet
- Modular - Gen Math11-Lesson 1.1 Functions As Mathematical Model of Real-Life Situations - BALLERAS, MDocument12 pagesModular - Gen Math11-Lesson 1.1 Functions As Mathematical Model of Real-Life Situations - BALLERAS, MAyesha YusopNo ratings yet
- Kelloway, E. Kevin Using Mplus For Structural Equation Modeling A Researchers GuideDocument250 pagesKelloway, E. Kevin Using Mplus For Structural Equation Modeling A Researchers Guideintemperante100% (4)
- Iyanaga S. - Algebraic Number TheoryDocument155 pagesIyanaga S. - Algebraic Number TheoryJohnnyNo ratings yet
- Python Machine Learning - Sample ChapterDocument57 pagesPython Machine Learning - Sample ChapterPackt PublishingNo ratings yet
- Esci386 Lesson01 IntroductionDocument12 pagesEsci386 Lesson01 IntroductionlocutorNo ratings yet
- Paul F. Lazarsfeld: National Academy of SciencesDocument34 pagesPaul F. Lazarsfeld: National Academy of SciencesSanja JankovićNo ratings yet
- Investigation of Interparticle Breakage As Applied To Cone Crushing PDFDocument16 pagesInvestigation of Interparticle Breakage As Applied To Cone Crushing PDFFrancisco Antonio Guerrero MonsalvesNo ratings yet
- 6th UnpackingDocument33 pages6th UnpackingJESUS ANTONIO RAMOS MORONNo ratings yet
- 1 - Petrobras - DeepWater Gas LiftDocument36 pages1 - Petrobras - DeepWater Gas LiftNisar KhanNo ratings yet
- Eee2502control Engineering IIIDocument32 pagesEee2502control Engineering IIIeuticus100% (1)
- Autonomous College Under VTU - Accredited by NBA - Approved by AICTEDocument3 pagesAutonomous College Under VTU - Accredited by NBA - Approved by AICTESureshNo ratings yet
- CH 6 Sampling - and - EstimationDocument15 pagesCH 6 Sampling - and - EstimationPoint BlankNo ratings yet
- Thermal PhysicsDocument68 pagesThermal PhysicsRahul KumarNo ratings yet
- CPM PertDocument21 pagesCPM Pertkabina goleNo ratings yet
- DXF FormatDocument208 pagesDXF Formatthigopal100% (1)
- The Cresent High School Dina .: Total Marks: 60 Marks Obt: - Physics S.S.C Part IDocument2 pagesThe Cresent High School Dina .: Total Marks: 60 Marks Obt: - Physics S.S.C Part ICh M Sami JuttNo ratings yet
- Mental Math Secrets - How To Be a Human CalculatorFrom EverandMental Math Secrets - How To Be a Human CalculatorRating: 5 out of 5 stars5/5 (3)
- A Mathematician's Lament: How School Cheats Us Out of Our Most Fascinating and Imaginative Art FormFrom EverandA Mathematician's Lament: How School Cheats Us Out of Our Most Fascinating and Imaginative Art FormRating: 5 out of 5 stars5/5 (5)
- Basic Math & Pre-Algebra Workbook For Dummies with Online PracticeFrom EverandBasic Math & Pre-Algebra Workbook For Dummies with Online PracticeRating: 4 out of 5 stars4/5 (2)
- Build a Mathematical Mind - Even If You Think You Can't Have One: Become a Pattern Detective. Boost Your Critical and Logical Thinking Skills.From EverandBuild a Mathematical Mind - Even If You Think You Can't Have One: Become a Pattern Detective. Boost Your Critical and Logical Thinking Skills.Rating: 5 out of 5 stars5/5 (1)
- Quantum Physics: A Beginners Guide to How Quantum Physics Affects Everything around UsFrom EverandQuantum Physics: A Beginners Guide to How Quantum Physics Affects Everything around UsRating: 4.5 out of 5 stars4.5/5 (3)
- Fluent in 3 Months: How Anyone at Any Age Can Learn to Speak Any Language from Anywhere in the WorldFrom EverandFluent in 3 Months: How Anyone at Any Age Can Learn to Speak Any Language from Anywhere in the WorldRating: 3 out of 5 stars3/5 (80)
- Calculus Workbook For Dummies with Online PracticeFrom EverandCalculus Workbook For Dummies with Online PracticeRating: 3.5 out of 5 stars3.5/5 (8)
- Mathematical Mindsets: Unleashing Students' Potential through Creative Math, Inspiring Messages and Innovative TeachingFrom EverandMathematical Mindsets: Unleashing Students' Potential through Creative Math, Inspiring Messages and Innovative TeachingRating: 4.5 out of 5 stars4.5/5 (21)
- Mental Math: How to Develop a Mind for Numbers, Rapid Calculations and Creative Math Tricks (Including Special Speed Math for SAT, GMAT and GRE Students)From EverandMental Math: How to Develop a Mind for Numbers, Rapid Calculations and Creative Math Tricks (Including Special Speed Math for SAT, GMAT and GRE Students)No ratings yet
- Images of Mathematics Viewed Through Number, Algebra, and GeometryFrom EverandImages of Mathematics Viewed Through Number, Algebra, and GeometryNo ratings yet
- ParaPro Assessment Preparation 2023-2024: Study Guide with 300 Practice Questions and Answers for the ETS Praxis Test (Paraprofessional Exam Prep)From EverandParaPro Assessment Preparation 2023-2024: Study Guide with 300 Practice Questions and Answers for the ETS Praxis Test (Paraprofessional Exam Prep)No ratings yet
- Math Workshop, Grade K: A Framework for Guided Math and Independent PracticeFrom EverandMath Workshop, Grade K: A Framework for Guided Math and Independent PracticeRating: 5 out of 5 stars5/5 (1)
- How Math Explains the World: A Guide to the Power of Numbers, from Car Repair to Modern PhysicsFrom EverandHow Math Explains the World: A Guide to the Power of Numbers, from Car Repair to Modern PhysicsRating: 3.5 out of 5 stars3.5/5 (9)
- A-level Maths Revision: Cheeky Revision ShortcutsFrom EverandA-level Maths Revision: Cheeky Revision ShortcutsRating: 3.5 out of 5 stars3.5/5 (8)
- A Guide to Success with Math: An Interactive Approach to Understanding and Teaching Orton Gillingham MathFrom EverandA Guide to Success with Math: An Interactive Approach to Understanding and Teaching Orton Gillingham MathRating: 5 out of 5 stars5/5 (1)