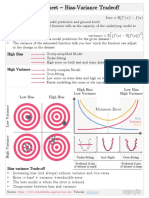
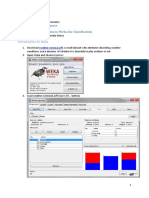
You might also like
- Alarming! the Chasm Separating Education of Applications of Finite Math from It's NecessitiesFrom EverandAlarming! the Chasm Separating Education of Applications of Finite Math from It's NecessitiesNo ratings yet
- Confusion Matrix ROCDocument8 pagesConfusion Matrix ROCtanaya lokhandeNo ratings yet
- Confusion Matrix ROCDocument8 pagesConfusion Matrix ROCtayab khanNo ratings yet
- Machine Learning InterviewDocument14 pagesMachine Learning Interviewsobuz visualNo ratings yet
- Machine Learning/Data Science Interview Cheat Sheets: Aqeel AnwarDocument17 pagesMachine Learning/Data Science Interview Cheat Sheets: Aqeel AnwarJulie ArquizaNo ratings yet
- Cheat Sheet - Machine Learning - Data Science Interview PDFDocument16 pagesCheat Sheet - Machine Learning - Data Science Interview PDFPauloNo ratings yet
- 10 Ai Evaluation tp01Document5 pages10 Ai Evaluation tp01tanjirouchihams12No ratings yet
- EvaluationDocument10 pagesEvaluationNikita AgrawalNo ratings yet
- Binary Classification PDFDocument27 pagesBinary Classification PDFashish kadamNo ratings yet
- Evaluation Metrics For Machine Learning: Negative (Actual) 98 Positive (Actual) 1Document2 pagesEvaluation Metrics For Machine Learning: Negative (Actual) 98 Positive (Actual) 1Denzil SeguntoNo ratings yet
- Chapter 5 Evaluation MetricsDocument18 pagesChapter 5 Evaluation Metricsliyu agyeNo ratings yet
- Learning Best Practices For Model Evaluation and Hyper-Parameter TuningDocument20 pagesLearning Best Practices For Model Evaluation and Hyper-Parameter Tuningsanjeev devNo ratings yet
- Confusion MatrixDocument43 pagesConfusion MatrixSwapnil BeraNo ratings yet
- Machine Learning Cheat Sheet PDFDocument15 pagesMachine Learning Cheat Sheet PDFgalagrandNo ratings yet
- Python LearningDocument21 pagesPython LearningVinayNo ratings yet
- What Is Evaluation ?: PredictionDocument7 pagesWhat Is Evaluation ?: Predictionrokesh choudharyNo ratings yet
- Confusion MatrixDocument5 pagesConfusion MatrixretnoNo ratings yet
- Classification Metrics in Machine LearningDocument6 pagesClassification Metrics in Machine Learningxlnc1No ratings yet
- Evaluation Measure ClassificationDocument6 pagesEvaluation Measure ClassificationEnaqkat PainavNo ratings yet
- Data Mining: Accuracy and Error Measures For Classification and PredictionDocument15 pagesData Mining: Accuracy and Error Measures For Classification and PredictionAshish MohareNo ratings yet
- Chapter 3 Modelling and EvaluationDocument11 pagesChapter 3 Modelling and EvaluationShreeji ModhNo ratings yet
- Permane NT Temporar y Depende NT Independ Ent: 5 PointsDocument12 pagesPermane NT Temporar y Depende NT Independ Ent: 5 PointsRohan AhujaNo ratings yet
- Lecture 2 Classifier Performance MetricsDocument60 pagesLecture 2 Classifier Performance Metricsiamboss086No ratings yet
- Accuracy, Precision, Recall & F1 Score Interpretation of Performance MeasuresDocument5 pagesAccuracy, Precision, Recall & F1 Score Interpretation of Performance MeasuresFriday JonesNo ratings yet
- Confusion Matrix Machine LearningDocument9 pagesConfusion Matrix Machine Learningyordanos birhanuNo ratings yet
- Machine Learning in 10 Pages PDFDocument10 pagesMachine Learning in 10 Pages PDFPratyushNo ratings yet
- ML in 10 Pages 1683806402Document10 pagesML in 10 Pages 1683806402luis.pozaspalomoNo ratings yet
- Evaluation Grade10 AiDocument32 pagesEvaluation Grade10 Aiashwinajay14No ratings yet
- EVALUATIONDocument4 pagesEVALUATIONVarsha SinghNo ratings yet
- National Education Policy 2010 FinalDocument61 pagesNational Education Policy 2010 FinalAli HasanNo ratings yet
- EvaluationQuestions Class 10 AiDocument6 pagesEvaluationQuestions Class 10 AikritavearnNo ratings yet
- Model Evaluation and SelectionDocument7 pagesModel Evaluation and SelectionNikhil KanojiNo ratings yet
- Lecture 16Document36 pagesLecture 16Abood FazilNo ratings yet
- Lec4 Oct12 2022 PracticalNotes LinearRegressionDocument34 pagesLec4 Oct12 2022 PracticalNotes LinearRegressionasasdNo ratings yet
- Unit 1MLDocument12 pagesUnit 1MLIshita BahugunaNo ratings yet
- Economics Assignment 2Document11 pagesEconomics Assignment 2Parikshit AgrawalNo ratings yet
- L04 The Classification PipelineDocument46 pagesL04 The Classification PipelineYONG LONG KHAWNo ratings yet
- Binary ClassificationMetrics CheathsheetDocument7 pagesBinary ClassificationMetrics CheathsheetPedro PereiraNo ratings yet
- MBCQ721D-Quantitative Techniques For Management Application-1Document14 pagesMBCQ721D-Quantitative Techniques For Management Application-1Utkarsh Singh100% (1)
- Otal Questions: 56 Total Marks: 100Document11 pagesOtal Questions: 56 Total Marks: 100Parikshit AgrawalNo ratings yet
- DSI Guide - Assessing Classification AccuracyDocument29 pagesDSI Guide - Assessing Classification AccuracyMiguel Angel PiñonNo ratings yet
- 6 Beyond Binary ClassificationDocument14 pages6 Beyond Binary ClassificationJiahong HeNo ratings yet
- Machine Learning Andrew NG Week 6Document11 pagesMachine Learning Andrew NG Week 6Hương ĐặngNo ratings yet
- Physics - 1st MQADocument4 pagesPhysics - 1st MQALance LirioNo ratings yet
- ML Q & A Interview Prep:: ML Algorithms + Basic MLDocument12 pagesML Q & A Interview Prep:: ML Algorithms + Basic MLSrikanth NampalliNo ratings yet
- DM - ModelEvaluation CH 3Document14 pagesDM - ModelEvaluation CH 3Hasset Tiss Abay GenjiNo ratings yet
- 3b. IntroductionToMachineLearningDocument42 pages3b. IntroductionToMachineLearningGauravNo ratings yet
- Performance Metrics (Classification) : Enrique J. de La Hoz DDocument30 pagesPerformance Metrics (Classification) : Enrique J. de La Hoz DJORGE LUIS AGUAS MEZANo ratings yet
- Model Validity (1) : Huawei Confidential 39Document13 pagesModel Validity (1) : Huawei Confidential 39muhamad nadrNo ratings yet
- DS Cheat SheetsDocument18 pagesDS Cheat SheetspunmapiNo ratings yet
- Bernd Klein Python and Machine Learning LetterDocument453 pagesBernd Klein Python and Machine Learning LetterRajaNo ratings yet
- Accuracy, Precision, Recall or F1 - Towards Data ScienceDocument9 pagesAccuracy, Precision, Recall or F1 - Towards Data SciencePRINCE HRIDAYALANKARNo ratings yet
- MIT GJKDocument21 pagesMIT GJKDevendraReddyPoreddyNo ratings yet
- Docs Guiding Principles in Constructing True or FalseDocument5 pagesDocs Guiding Principles in Constructing True or FalseJoy Alexa SibagNo ratings yet
- Machine Learning ProcessDocument7 pagesMachine Learning ProcessBalqishAbuBakarNo ratings yet
- Practical 5: Introduction To Weka For ClassficationDocument4 pagesPractical 5: Introduction To Weka For ClassficationPhạm Hoàng KimNo ratings yet
- CH 3Document8 pagesCH 3Tran Kim ToaiNo ratings yet
- General Physics 1: Quarter 1 - Module 1Document18 pagesGeneral Physics 1: Quarter 1 - Module 1Pril GuetaNo ratings yet
- ClusteringDocument4 pagesClusteringAshuNo ratings yet
- Logistic Regression - Model LearningDocument2 pagesLogistic Regression - Model LearningAshuNo ratings yet
- Logistic Regression - BuildingDocument4 pagesLogistic Regression - BuildingAshuNo ratings yet
- Market Basket QuestionsDocument1 pageMarket Basket QuestionsAshuNo ratings yet
- Time Series ForecastingDocument1 pageTime Series ForecastingAshu0% (1)
- Logistic Regression - Fitness of ModelDocument2 pagesLogistic Regression - Fitness of ModelAshuNo ratings yet
- Alternative AssessmentDocument24 pagesAlternative AssessmentSol100% (2)
- Passive VoiceDocument9 pagesPassive VoiceGeorgia KleoudiNo ratings yet
- Research Management DR Mohamed Hasnain IsaDocument62 pagesResearch Management DR Mohamed Hasnain IsarushdiNo ratings yet
- Individual Performance Commitment and Review Form: Mfos Kras Objectives Timeline Weight Rating Per KRADocument6 pagesIndividual Performance Commitment and Review Form: Mfos Kras Objectives Timeline Weight Rating Per KRARogieNo ratings yet
- LIT5343 Module 2 ApplicationDocument8 pagesLIT5343 Module 2 ApplicationCaraNo ratings yet
- Hip 2017 Contest BrochureDocument4 pagesHip 2017 Contest BrochureRanita AwangNo ratings yet
- Allport's Theory of PersonalityDocument13 pagesAllport's Theory of PersonalityNiharika SpencerNo ratings yet
- Tiếng Anh: WonderfulDocument190 pagesTiếng Anh: WonderfulHà Thị Hồng NhungNo ratings yet
- Math Lesson Plan 4Document4 pagesMath Lesson Plan 4api-299621535No ratings yet
- Curriculm VitaeDocument10 pagesCurriculm Vitaeapi-603235692No ratings yet
- Graphic Organizer TemplatesDocument38 pagesGraphic Organizer Templatesanna39100% (2)
- Lesson Plan - in The Old HouseDocument8 pagesLesson Plan - in The Old HouseMicle Gheorghe-mihaiNo ratings yet
- Miss Lose Carry Wear Take Give: Useful VerbsDocument2 pagesMiss Lose Carry Wear Take Give: Useful VerbsMiguel PradoNo ratings yet
- Cefr Grammar Levels - 1425642569 PDFDocument6 pagesCefr Grammar Levels - 1425642569 PDFkhaledhnNo ratings yet
- Finding The Philosophical Core: A Review of Stephen C. Pepper's World Hypotheses: A Study in Evidence1Document16 pagesFinding The Philosophical Core: A Review of Stephen C. Pepper's World Hypotheses: A Study in Evidence1Júlio C. Abdala FHNo ratings yet
- MODULE - 1 AnswersDocument10 pagesMODULE - 1 AnswersDARLYN TABEROSNo ratings yet
- TENSESDocument34 pagesTENSESLalu FahrurroziNo ratings yet
- CSEC English A E Marking Specimen 2013 P2Document24 pagesCSEC English A E Marking Specimen 2013 P2Kevin50% (2)
- Chapter 2Document3 pagesChapter 2Leandro CabalteaNo ratings yet
- BBLDocument7 pagesBBLSyarifah RaisaNo ratings yet
- Oral Com #1 ActivityDocument3 pagesOral Com #1 ActivityAngelica Sibayan QuinionesNo ratings yet
- PBL Assessment 2Document23 pagesPBL Assessment 2api-430008440No ratings yet
- Lbs 302 Classroom Management PlanDocument10 pagesLbs 302 Classroom Management Planapi-437553094No ratings yet
- Advanced Practice On Word Formation PDFDocument0 pagesAdvanced Practice On Word Formation PDFKhiem Vuong100% (1)
- 1944 - Robert - The Science of IdiomsDocument17 pages1944 - Robert - The Science of IdiomsErica WongNo ratings yet
- Ray Schlanger Sutton 2009Document23 pagesRay Schlanger Sutton 2009abigailNo ratings yet
- Reasoning Coding 3Document9 pagesReasoning Coding 3sontoshNo ratings yet
- Motivation WorksheetDocument4 pagesMotivation WorksheetDragutescu Maria ElizaNo ratings yet
- Bca 106 BusineesDocument6 pagesBca 106 BusineesanilperfectNo ratings yet
- Lecture-8. Only For This BatchDocument46 pagesLecture-8. Only For This BatchmusaNo ratings yet