You might also like
- Distillation 1Document157 pagesDistillation 1Tapiwa Kaponda100% (1)
- Mass Transfer Ecp 224: Unit 4: LeachingDocument53 pagesMass Transfer Ecp 224: Unit 4: LeachingTapiwa KapondaNo ratings yet
- Mass Transfer Ecp 224: Unit 6: DryingDocument50 pagesMass Transfer Ecp 224: Unit 6: DryingTapiwa KapondaNo ratings yet
- Mass Transfer Tutorial: Distillation Example Problem 2: Mccabe-Thiele MethodDocument11 pagesMass Transfer Tutorial: Distillation Example Problem 2: Mccabe-Thiele MethodTapiwa KapondaNo ratings yet
- Of Approximation Numerical Methods: Learning OutcomesDocument27 pagesOf Approximation Numerical Methods: Learning OutcomesTapiwa KapondaNo ratings yet
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (400)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (345)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (121)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- MHF4U - Polynomial TestDocument5 pagesMHF4U - Polynomial Testsriram5555No ratings yet
- Galois in MatLab GuideDocument30 pagesGalois in MatLab Guidelitter_trashNo ratings yet
- Answer Key: 1.7. Quadratic InequalityDocument10 pagesAnswer Key: 1.7. Quadratic InequalityPrincess BoloyNo ratings yet
- Trigo ReviewDocument4 pagesTrigo ReviewDaniel VargasNo ratings yet
- Alcorcon Engineering Review Center: Mathematics (Analytic Geometry) - Day 7Document7 pagesAlcorcon Engineering Review Center: Mathematics (Analytic Geometry) - Day 7Chloe OlazoNo ratings yet
- A. Introduciton: MethodDocument19 pagesA. Introduciton: MethodStrag ChrisNo ratings yet
- Transformation of Functions (Solved With Notes)Document21 pagesTransformation of Functions (Solved With Notes)cs23b1008No ratings yet
- Review Pre Lim ExamDocument72 pagesReview Pre Lim ExamMel Kris MamigoNo ratings yet
- ODEs Modern Perspective Ebook 2003Document271 pagesODEs Modern Perspective Ebook 2003Hanan AltousNo ratings yet
- GRADE 10 SESSION 5 Coordinate Plane Geometry 1Document59 pagesGRADE 10 SESSION 5 Coordinate Plane Geometry 1Gilbert MadinoNo ratings yet
- Module 1Document13 pagesModule 1shaina sucgangNo ratings yet
- FB Applied Maths Module V5Document349 pagesFB Applied Maths Module V5reqiqie reqeqeNo ratings yet
- Pressure Derivative AnalysisDocument8 pagesPressure Derivative AnalysissethkakNo ratings yet
- DILE NO A LA PLANCHA (Kim Jhon Phatti Satto)Document6 pagesDILE NO A LA PLANCHA (Kim Jhon Phatti Satto)Kimsito Al TlvNo ratings yet
- Maths IIDocument5 pagesMaths IIMilan ShahiNo ratings yet
- Lesson 1 - Functions, Function Notation, Domain & RangeDocument27 pagesLesson 1 - Functions, Function Notation, Domain & RangeJerome FresadoNo ratings yet
- Chapter 14 I Circles ENRICHDocument16 pagesChapter 14 I Circles ENRICHjuriah binti ibrahim100% (1)
- Mathematical Relations PDFDocument229 pagesMathematical Relations PDFmars100% (1)
- 2015 MTAP Reviewer For 4th Year Solution Part 1Document3 pages2015 MTAP Reviewer For 4th Year Solution Part 1Nathaniel Pascua22% (9)
- Lecture Notes On Classical Integrability and On The Algebraic Bethe Ansatz For The XXX Heisenberg Spin ChainDocument36 pagesLecture Notes On Classical Integrability and On The Algebraic Bethe Ansatz For The XXX Heisenberg Spin ChainDieff_No ratings yet
- Intermediate Algebra Applications Visualization 3rd Edition Rockswold Test BankDocument18 pagesIntermediate Algebra Applications Visualization 3rd Edition Rockswold Test BankrytormalNo ratings yet
- Fractions 5 Class NotesDocument8 pagesFractions 5 Class NotesviswanathNo ratings yet
- CBSE Class 12 Mathematics Matrices and Determinants Worksheet Set KDocument8 pagesCBSE Class 12 Mathematics Matrices and Determinants Worksheet Set KChaitanya Sethi XI-BNo ratings yet
- Grade 10 12 Understanding The Principles of MathematicsDocument129 pagesGrade 10 12 Understanding The Principles of MathematicsChristabel C kangoNo ratings yet
- MATH 4 10 Least LearnedDocument3 pagesMATH 4 10 Least Learnedariel mateo monesNo ratings yet
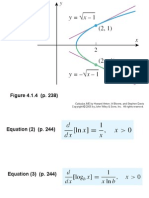
- Figure 4.1.4 (P. 238) : Calculus, 8/E by Howard Anton, Irl Bivens, and Stephen DavisDocument11 pagesFigure 4.1.4 (P. 238) : Calculus, 8/E by Howard Anton, Irl Bivens, and Stephen DavisofuzetaNo ratings yet
- Additional Practice Questions: © Oxford University Press 2021 1Document4 pagesAdditional Practice Questions: © Oxford University Press 2021 1AineeNo ratings yet
- Qualifying Examination For Applicants For Japanese Government (Mext) Scholarship 2020Document6 pagesQualifying Examination For Applicants For Japanese Government (Mext) Scholarship 2020Lésio LuísNo ratings yet
- Vector Spaces: 6.1 Definition and Some Basic PropertiesDocument157 pagesVector Spaces: 6.1 Definition and Some Basic PropertiesByron JimenezNo ratings yet
- 02-Random VariablesDocument38 pages02-Random Variablesmilkiyas mosisaNo ratings yet