You might also like
- Disadvantages of Systematic Literature ReviewDocument8 pagesDisadvantages of Systematic Literature Reviewea442225100% (1)
- Content Analysis and Literature ReviewDocument4 pagesContent Analysis and Literature Reviewafmzfvlopbchbe100% (1)
- Template For A Systematic Literature Review ProtocolDocument8 pagesTemplate For A Systematic Literature Review ProtocolafdtvuzihNo ratings yet
- Journal IndexingDocument18 pagesJournal IndexingUmang PatelNo ratings yet
- Review of Related Literature Sample For Student Information SystemDocument5 pagesReview of Related Literature Sample For Student Information Systemea844bbvNo ratings yet
- Guidelines For Performing Systematic Literature Reviews in SoftwareDocument8 pagesGuidelines For Performing Systematic Literature Reviews in Softwareea6xrjc4No ratings yet
- Measuring Open Source Quality A Literature ReviewDocument8 pagesMeasuring Open Source Quality A Literature Reviewfvf4r6xqNo ratings yet
- Sample Literature Review Computer ScienceDocument7 pagesSample Literature Review Computer Scienceafmzxpqoizljqo100% (1)
- Search Strategy For Systematic Literature ReviewDocument6 pagesSearch Strategy For Systematic Literature Reviewaixgaoqif100% (1)
- Systematic Literature Review Information TechnologyDocument7 pagesSystematic Literature Review Information Technologyz0pilazes0m3No ratings yet
- How To Give Citation in Literature ReviewDocument8 pagesHow To Give Citation in Literature Reviewfvg6kcwyNo ratings yet
- A Guide To Conducting A Systematic Literature ReviewDocument8 pagesA Guide To Conducting A Systematic Literature Reviewea8p6td0No ratings yet
- Performing Systematic Literature Review in Software EngineeringDocument6 pagesPerforming Systematic Literature Review in Software Engineeringc5sx83wsNo ratings yet
- Dissertation To Journal Article A Systematic ApproachDocument5 pagesDissertation To Journal Article A Systematic ApproachHelpWithCollegePaperWritingSingaporeNo ratings yet
- Systematic Literature Review Information SystemsDocument6 pagesSystematic Literature Review Information Systemssmvancvkg100% (1)
- Search Methodology Literature ReviewDocument7 pagesSearch Methodology Literature Reviewafdtorpqk100% (1)
- How To Write Literature Review Computer ScienceDocument5 pagesHow To Write Literature Review Computer SciencebeqfkirifNo ratings yet
- A Tertiary Study Experiences of Conducting Systematic Literature Reviews in Software EngineeringDocument6 pagesA Tertiary Study Experiences of Conducting Systematic Literature Reviews in Software EngineeringaflsmceocNo ratings yet
- Web-Scale Discovery Services: Principles, Applications, Discovery Tools and Development HypothesesFrom EverandWeb-Scale Discovery Services: Principles, Applications, Discovery Tools and Development HypothesesNo ratings yet
- Literature Review Example AccountingDocument6 pagesLiterature Review Example Accountingj1zijefifin3100% (1)
- Literature Review Number of SourcesDocument5 pagesLiterature Review Number of Sourcesc5nrmzsw100% (1)
- Guidelines For Performing Systematic Literature Reviews in Software EngineeringDocument4 pagesGuidelines For Performing Systematic Literature Reviews in Software Engineeringtog0filih1h2No ratings yet
- Why Do A Systematic Literature ReviewDocument8 pagesWhy Do A Systematic Literature Reviewc5hzgcdj100% (1)
- Systematic Literature Review en FrancaisDocument4 pagesSystematic Literature Review en Francaisafmzyywqyfolhp100% (1)
- Literature Review in Research Paper SampleDocument4 pagesLiterature Review in Research Paper Sampleaflsigakf100% (1)
- Information Technology Literature Review ExampleDocument8 pagesInformation Technology Literature Review ExampleafdtbbhtzNo ratings yet
- Literature Review Computer SystemDocument4 pagesLiterature Review Computer Systemafdtliuvb100% (1)
- Literature Review For Engineering ThesisDocument8 pagesLiterature Review For Engineering Thesisdhryaevkg100% (1)
- Implementing It Service Management A Systematic Literature ReviewDocument5 pagesImplementing It Service Management A Systematic Literature Reviewc5r0xg9zNo ratings yet
- Systematic Literature Review ProtocolDocument6 pagesSystematic Literature Review Protocolnqdpuhxgf100% (1)
- Systematic Literature Review DatabaseDocument5 pagesSystematic Literature Review Databaseaflsnbfir100% (1)
- Methodology Before Literature ReviewDocument5 pagesMethodology Before Literature Reviewc5ryek5a100% (1)
- Systematic Literature Review ComponentsDocument7 pagesSystematic Literature Review Componentsgw10ka6s100% (1)
- Example of Citation in Literature ReviewDocument6 pagesExample of Citation in Literature Reviewafdtlgezo100% (1)
- How To Make Citation in Literature ReviewDocument6 pagesHow To Make Citation in Literature Reviewc5jwy8nr100% (1)
- Literature Review On Online SystemsDocument4 pagesLiterature Review On Online Systemsetmqwvqif100% (1)
- Literature Review On Database Management SystemDocument10 pagesLiterature Review On Database Management SystempkzoyxrifNo ratings yet
- Literature Review TaxonomyDocument8 pagesLiterature Review Taxonomyea5zjs6a100% (1)
- Systematic Literature Review FormatDocument6 pagesSystematic Literature Review Formatfeiaozukg100% (1)
- Literature Review On PositioningDocument5 pagesLiterature Review On Positioningea1yw8dx100% (1)
- Where To Place Literature Review in A Research PaperDocument5 pagesWhere To Place Literature Review in A Research PaperzrpcnkrifNo ratings yet
- Systematic Literature Review Search StrategyDocument6 pagesSystematic Literature Review Search Strategyc5j07dceNo ratings yet
- Et Al in Literature ReviewDocument6 pagesEt Al in Literature Reviewgjosukwgf100% (1)
- Research Paper On Database IndexingDocument4 pagesResearch Paper On Database Indexingcwzobjbkf100% (1)
- Literature Review For Project Management SystemDocument4 pagesLiterature Review For Project Management Systemafmzsgbmgwtfoh100% (1)
- How To Find Impact Factor of A Research PaperDocument8 pagesHow To Find Impact Factor of A Research Paperfvgy6fn3100% (1)
- Theoretical Conceptual Framework Literature ReviewDocument8 pagesTheoretical Conceptual Framework Literature ReviewafdtywgduNo ratings yet
- Evidence Table For Literature ReviewDocument6 pagesEvidence Table For Literature Reviewafmzzulfmzbxet100% (1)
- Systematic Literature Review MastersDocument8 pagesSystematic Literature Review Mastersafmzxutkxdkdam100% (1)
- How To Make A Medical Literature ReviewDocument4 pagesHow To Make A Medical Literature Reviewfnraxlvkg100% (1)
- Systematic Literature Review Summary TableDocument6 pagesSystematic Literature Review Summary Tableaflsqfsaw100% (1)
- Systematic Literature Review ToolsDocument8 pagesSystematic Literature Review Toolsaflsiqhah100% (1)
- Example Law Literature ReviewDocument8 pagesExample Law Literature Reviewjizogol1siv3100% (1)
- Literature Review Library ScienceDocument4 pagesLiterature Review Library Scienceafmyervganedba100% (1)
- Systematic or Literature ReviewDocument8 pagesSystematic or Literature Reviewea219sww100% (1)
- Systematic Literature Review MethodologyDocument6 pagesSystematic Literature Review Methodologyea7gjrm5100% (1)
- Literature Review On Expert SystemDocument6 pagesLiterature Review On Expert Systemc5sd1aqj100% (1)
- How To Start A Systematic Literature ReviewDocument8 pagesHow To Start A Systematic Literature Reviewfgwuwoukg100% (1)
- Literature Review MediaDocument4 pagesLiterature Review Mediac5j07dce100% (1)
- Literature Review Systematic ApproachDocument6 pagesLiterature Review Systematic Approachafdtrzkhw100% (1)
- chapter 10 dbmsDocument9 pageschapter 10 dbmsSaloni VaniNo ratings yet
- Ack, Cert, TOC, AbstractDocument5 pagesAck, Cert, TOC, AbstractShailendra DeolNo ratings yet
- ETL MappingDocument19 pagesETL MappingsureshNo ratings yet
- Managing IT Case Studies and ChaptersDocument2 pagesManaging IT Case Studies and ChaptersAndreas BrownNo ratings yet
- DBMS Lesson 5.1Document17 pagesDBMS Lesson 5.1Ravi TejaNo ratings yet
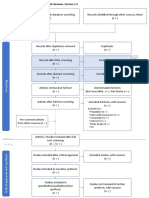
- ROSES Flow Diagram For Systematic ReviewsDocument1 pageROSES Flow Diagram For Systematic Reviewswhy daNo ratings yet
- Architecture and components of Computer System: Memory ClassificationDocument14 pagesArchitecture and components of Computer System: Memory Classificationtestscribd9898No ratings yet
- Modulo Nand Flash ARDUINODocument78 pagesModulo Nand Flash ARDUINOWilmer Yesid Granados JaimesNo ratings yet
- Newrajesh R13Document8 pagesNewrajesh R13R. RajeshNo ratings yet
- The Data Warehouse Toolkit - The Complete - Guide - To - Dimensional - Modeling - Chapter 02Document35 pagesThe Data Warehouse Toolkit - The Complete - Guide - To - Dimensional - Modeling - Chapter 02Huỳnh Các Duy ThuầnNo ratings yet
- Five-minute rule thirty years laterDocument29 pagesFive-minute rule thirty years laterKevin MarcusNo ratings yet
- Data Lineage and Impact AnalysisDocument1 pageData Lineage and Impact AnalysisAsad HussainNo ratings yet
- SQL DBA AlwaysOn Interview Questions and Answers 01Document9 pagesSQL DBA AlwaysOn Interview Questions and Answers 01AnishNo ratings yet
- Brilliant Database v9 User Guide SEODocument224 pagesBrilliant Database v9 User Guide SEOPaul AsturbiarisNo ratings yet
- LogDocument65 pagesLogRois SamsihanNo ratings yet
- MySQL Questions AnswersDocument18 pagesMySQL Questions Answersfouziya9296No ratings yet
- Murachs SQL Server 2016 For Developers TOCDocument10 pagesMurachs SQL Server 2016 For Developers TOCmidowakilNo ratings yet
- User ExperienceDocument195 pagesUser Experiencekapow100% (3)
- Getting Started with Power QueryDocument45 pagesGetting Started with Power QueryDioniisosNo ratings yet
- Informatics Practices Practical File Class 12th - Pandas, Matplotlib & SQL Questions With SolutionsDocument27 pagesInformatics Practices Practical File Class 12th - Pandas, Matplotlib & SQL Questions With Solutionsdeboshree chatterjee100% (1)
- Manual Library Management SystemDocument9 pagesManual Library Management Systemkf410071No ratings yet
- Uttar Pradesh Unnao Block FacilitiesDocument272 pagesUttar Pradesh Unnao Block FacilitiesAhana ChatterjeeNo ratings yet
- Types of Database Normalization Explained in DetailDocument23 pagesTypes of Database Normalization Explained in DetailDrBhupesh RawatNo ratings yet
- GettingStarted 12.0.0.1 PDFDocument37 pagesGettingStarted 12.0.0.1 PDFAshaNo ratings yet
- AyushmanBhattacharya MCAN-102 CA2 121802Document4 pagesAyushmanBhattacharya MCAN-102 CA2 121802Ayushman BhattacharyaNo ratings yet
- XconDocument12 pagesXconsriuthraNo ratings yet
- SQL IvDocument14 pagesSQL IvKrishnendu RarhiNo ratings yet
- Raskin, Jef - Humane Interface, The - New Directions For Designing Interactive Systems - Indice - Online en CISNE PDFDocument2 pagesRaskin, Jef - Humane Interface, The - New Directions For Designing Interactive Systems - Indice - Online en CISNE PDFxabazx0% (2)
- Prefatory Section of A Long (Formal) ReportDocument5 pagesPrefatory Section of A Long (Formal) ReportSadaf Fayyaz50% (2)
- Process Chain MonitoringDocument3 pagesProcess Chain MonitoringkaranNo ratings yet