You might also like
- 07-02-16 - Sr. IIT-IZ-CO-SPARK - Ph-I - Jee-Main - GTM-4 - Key & Sol'sDocument13 pages07-02-16 - Sr. IIT-IZ-CO-SPARK - Ph-I - Jee-Main - GTM-4 - Key & Sol'sUppu EshwarNo ratings yet
- The F Test or AnovaDocument5 pagesThe F Test or AnovaCynthia Gemino BurgosNo ratings yet
- Lesson 11 - Angles in A Unit CircleDocument77 pagesLesson 11 - Angles in A Unit CircleRenNo ratings yet
- Summation Notation ExplainedDocument15 pagesSummation Notation ExplainedasdNo ratings yet
- Moderate 180 Intro 1: Standard TuningDocument4 pagesModerate 180 Intro 1: Standard TuningZombieMrCazNo ratings yet
- ANSWERS (Full Permission) PDFDocument65 pagesANSWERS (Full Permission) PDFWant To LearnNo ratings yet
- 22-05-2021 SR - Super60 (In Coming) Jee-Main WTM-31 Key & Sol'sDocument12 pages22-05-2021 SR - Super60 (In Coming) Jee-Main WTM-31 Key & Sol'sRohan k sNo ratings yet
- RM- Session 7 (Week #9)Document11 pagesRM- Session 7 (Week #9)oalsiyabi42No ratings yet
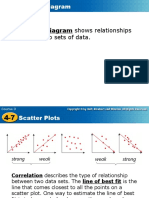
- Scatter Plots Show Relationships Between Data SetsDocument7 pagesScatter Plots Show Relationships Between Data SetsJhonrick MagtibayNo ratings yet
- Spearman Rank Correlation Coefficient ProblemsDocument8 pagesSpearman Rank Correlation Coefficient ProblemsLavinia Delos SantosNo ratings yet
- Part Test-6: Allindiatest SeriesDocument12 pagesPart Test-6: Allindiatest SeriesafasdfasdNo ratings yet
- Aieee Paper - 2010 Answers and Explanations Code:: X X X 2xDocument11 pagesAieee Paper - 2010 Answers and Explanations Code:: X X X 2xscribd_lostandfoundNo ratings yet
- AnomalyDocument2 pagesAnomalyA AzlanNo ratings yet
- Hungarian Method ExplainedDocument2 pagesHungarian Method ExplainedJosé Luis VelázquezNo ratings yet
- MCP-03-12-2018 MT-7 Ans Key Sol 12th PDFDocument10 pagesMCP-03-12-2018 MT-7 Ans Key Sol 12th PDFRishi Dey ChowdhuryNo ratings yet
- Jee-Main - WTM-13 - Key & Sol'sDocument8 pagesJee-Main - WTM-13 - Key & Sol'stheju13052006No ratings yet
- Run Test For RandomnessDocument12 pagesRun Test For RandomnessRajkumar VijNo ratings yet
- Se Essa Rua Fosse MinhaDocument1 pageSe Essa Rua Fosse MinhaRaquel de FreitasNo ratings yet
- Screenshot 2023-07-03 at 17.50.55Document79 pagesScreenshot 2023-07-03 at 17.50.55Anastasiia GorodniaNo ratings yet
- Screenshot 2024-02-05 at 21.16.02Document79 pagesScreenshot 2024-02-05 at 21.16.02Anastasiia GorodniaNo ratings yet
- Screenshot 2023-09-05 at 18.11.33Document79 pagesScreenshot 2023-09-05 at 18.11.33Anastasiia GorodniaNo ratings yet
- Screenshot 2023-10-29 at 12.28.33Document79 pagesScreenshot 2023-10-29 at 12.28.33Anastasiia GorodniaNo ratings yet
- Screenshot 2023-11-23 at 18.25.33Document79 pagesScreenshot 2023-11-23 at 18.25.33Anastasiia GorodniaNo ratings yet
- Screenshot 2024-01-04 at 17.01.37Document79 pagesScreenshot 2024-01-04 at 17.01.37Anastasiia GorodniaNo ratings yet
- Screenshot 2023-12-15 at 18.48.34Document79 pagesScreenshot 2023-12-15 at 18.48.34Anastasiia GorodniaNo ratings yet
- MR Brightside Song BreakdownDocument4 pagesMR Brightside Song BreakdownSteven SwiftNo ratings yet
- Mathematics Notes on Matrices and DeterminantsDocument36 pagesMathematics Notes on Matrices and DeterminantsMuhammad JanNo ratings yet
- 6 - Graph-Note VersionDocument93 pages6 - Graph-Note VersionRakibul IslamNo ratings yet
- Structured LightDocument10 pagesStructured LightKopkoHNo ratings yet
- Memo Grade 7 Mathematics Test Term 2 2022Document2 pagesMemo Grade 7 Mathematics Test Term 2 2022emmanuelmutemba919No ratings yet
- Stroud Engineering Mathematics 7th Ed ErrataDocument3 pagesStroud Engineering Mathematics 7th Ed ErrataRonald LNo ratings yet
- Firth of Firth AcousticDocument3 pagesFirth of Firth Acousticfranck GARCIANo ratings yet
- 09 02 17 SR - Iit Iz Co Spark Jee Main GTM 3 Key&SolDocument13 pages09 02 17 SR - Iit Iz Co Spark Jee Main GTM 3 Key&SolUppu EshwarNo ratings yet
- CS702 - Advanced Algorithms Analysis and Design: Instructions To Solve AssignmentsDocument4 pagesCS702 - Advanced Algorithms Analysis and Design: Instructions To Solve Assignmentsmc210202963 MAMOONA RANANo ratings yet
- 6) TOROKHTIY Online Training (15 - 21 Feb 2016)Document25 pages6) TOROKHTIY Online Training (15 - 21 Feb 2016)hanus.milannseznam.czNo ratings yet
- TOEFL 4 answer sheetDocument3 pagesTOEFL 4 answer sheetSaidNo ratings yet
- Sri Chaitanya IIT Academy., India.: Key SheetDocument9 pagesSri Chaitanya IIT Academy., India.: Key SheetAMITH. KNo ratings yet
- Linear AlgebraDocument19 pagesLinear AlgebraOm SirsathNo ratings yet
- Fajar 2019: AnswersDocument2 pagesFajar 2019: AnswersJosephine AnandNo ratings yet
- Survey response data analysisDocument4 pagesSurvey response data analysisRadinsa Yola CandadilaNo ratings yet
- Suhu Awal Liquida (C) Bukaan Liquida (Putaran) Bukaan Gas (Derajat) Suhu Liquida Produk (C)Document30 pagesSuhu Awal Liquida (C) Bukaan Liquida (Putaran) Bukaan Gas (Derajat) Suhu Liquida Produk (C)JV CVNo ratings yet
- Orchestral: Words & Music by Born For Dying 120Document9 pagesOrchestral: Words & Music by Born For Dying 120AndreasNo ratings yet
- 2 - Introduction To Matrices: A A A A A ADocument2 pages2 - Introduction To Matrices: A A A A A AD MNo ratings yet
- Sri Chaitanya IIT Academy., India.: Key SheetDocument38 pagesSri Chaitanya IIT Academy., India.: Key SheetAjay BhatnagarNo ratings yet
- Grade 8 Practice Book PDFDocument116 pagesGrade 8 Practice Book PDFMahmoud SolimanNo ratings yet
- CSMQLD SpecMath34 19answersDocument79 pagesCSMQLD SpecMath34 19answersgreatdowhanNo ratings yet
- Circle Trig DefinitionDocument36 pagesCircle Trig DefinitionnuagagwenmoNo ratings yet
- Book 1Document2 pagesBook 1VIANEY ERYL DIYAWYAWNo ratings yet
- Case5-Draperton Parks and RecreationDocument3 pagesCase5-Draperton Parks and RecreationlifrachobaNo ratings yet
- Basic GraphDocument8 pagesBasic GraphAditNo ratings yet
- FPP Daisy Pattern.01Document1 pageFPP Daisy Pattern.01Ann SztojkaNo ratings yet
- AnovaDocument16 pagesAnovaJodie JustinianoNo ratings yet
- Solution Report 202Document8 pagesSolution Report 202debsankarsantra123No ratings yet
- Frequencies: StatisticsDocument11 pagesFrequencies: StatisticsDian ZaizyulNo ratings yet
- Divide-and-Conquer Analysis of Merge SortDocument20 pagesDivide-and-Conquer Analysis of Merge SortHamza HashmiNo ratings yet
- Chemist (Chemistry) Exam 2014 Key Release DateDocument1 pageChemist (Chemistry) Exam 2014 Key Release DateKeshavVashisthaNo ratings yet
- Iso 262 - 1998 (E)Document7 pagesIso 262 - 1998 (E)john_progecoNo ratings yet
- Frequency Distribution Hasil Tugas Titik Tengah Tally FrequencyDocument3 pagesFrequency Distribution Hasil Tugas Titik Tengah Tally FrequencyDelyana EbNo ratings yet
- A Waveguide Verification Standard Design Procedure For The Microwave Characterization of Magnetic MaterialsDocument12 pagesA Waveguide Verification Standard Design Procedure For The Microwave Characterization of Magnetic Materialsnaveen narulaNo ratings yet
- Nested Arrays: A Novel Approach To Array Processing With Enhanced Degrees of FreedomDocument15 pagesNested Arrays: A Novel Approach To Array Processing With Enhanced Degrees of Freedomnaveen narulaNo ratings yet
- Two-Dimensional DOA Estimation via Tensor Modeling for L-shaped Nested ArrayDocument12 pagesTwo-Dimensional DOA Estimation via Tensor Modeling for L-shaped Nested Arraynaveen narulaNo ratings yet
- Wideband Gaussian Source Processing Using A Linear Nested ArrayDocument4 pagesWideband Gaussian Source Processing Using A Linear Nested Arraynaveen narulaNo ratings yet
- Nested Arrays: A Novel Approach To Array Processing With Enhanced Degrees of FreedomDocument15 pagesNested Arrays: A Novel Approach To Array Processing With Enhanced Degrees of Freedomnaveen narulaNo ratings yet
- SIMULATED S-PARAMETERS REVEAL NOVEL METAMATERIAL'S NEGATIVE PERMEABILITYDocument4 pagesSIMULATED S-PARAMETERS REVEAL NOVEL METAMATERIAL'S NEGATIVE PERMEABILITYnaveen narulaNo ratings yet
- An Approximate Approach To Determining The Permittivity andDocument15 pagesAn Approximate Approach To Determining The Permittivity andnaveen narulaNo ratings yet
- Research Article: Broadband DOA Estimation Based On Nested ArraysDocument8 pagesResearch Article: Broadband DOA Estimation Based On Nested Arraysnaveen narulaNo ratings yet
- Nested Arrays: A Novel Approach To Array Processing With Enhanced Degrees of FreedomDocument15 pagesNested Arrays: A Novel Approach To Array Processing With Enhanced Degrees of Freedomnaveen narulaNo ratings yet
- Wideband Direction of Arrival Estimation Using Nested ArraysDocument4 pagesWideband Direction of Arrival Estimation Using Nested Arraysnaveen narulaNo ratings yet
- Wideband Direction of Arrival Estimation Using Nested ArraysDocument4 pagesWideband Direction of Arrival Estimation Using Nested Arraysnaveen narulaNo ratings yet
- Yimin D. Zhang, Moeness G. Amin, Fauzia Ahmad, and Braham HimedDocument4 pagesYimin D. Zhang, Moeness G. Amin, Fauzia Ahmad, and Braham Himednaveen narulaNo ratings yet
- Nested Arrays: A Novel Approach To Array Processing With Enhanced Degrees of FreedomDocument15 pagesNested Arrays: A Novel Approach To Array Processing With Enhanced Degrees of Freedomnaveen narulaNo ratings yet
- Sensors: Direction-of-Arrival Estimation in Coprime Array Using The ESPRIT-Based MethodDocument14 pagesSensors: Direction-of-Arrival Estimation in Coprime Array Using The ESPRIT-Based Methodnaveen narulaNo ratings yet
- Advanced Direction-of-Arrival Estimation and Beamforming Techniques For Multiple Antenna SystemsDocument198 pagesAdvanced Direction-of-Arrival Estimation and Beamforming Techniques For Multiple Antenna Systemsnaveen narulaNo ratings yet
- Multiple Emitter Location and Signal Parameter EstimationDocument5 pagesMultiple Emitter Location and Signal Parameter EstimationbarbaranicolasNo ratings yet
- Application of Detection Theory To The MeasurementDocument48 pagesApplication of Detection Theory To The Measurementnaveen narulaNo ratings yet
- Application of Detection Theory To The MeasurementDocument48 pagesApplication of Detection Theory To The Measurementnaveen narulaNo ratings yet
- Introduction To Machine Learning: K-Nearest Neighbors: Annals of Translational Medicine June 2016Document8 pagesIntroduction To Machine Learning: K-Nearest Neighbors: Annals of Translational Medicine June 2016naveen narulaNo ratings yet
- Signal Detection Theory (SDT) : 1 OverviewDocument9 pagesSignal Detection Theory (SDT) : 1 Overviewチャリズモニック ナヴァーロNo ratings yet
- Ambiguity Resolution in DOA Estimation Using Differential GeometryDocument19 pagesAmbiguity Resolution in DOA Estimation Using Differential Geometrynaveen narulaNo ratings yet
- Detection Theory by HeegerDocument10 pagesDetection Theory by HeegerRb KahnNo ratings yet
- Detection and Estimation With Compressive MeasurementsDocument16 pagesDetection and Estimation With Compressive MeasurementsAbd KanaaNo ratings yet
- F E U MFCC: Eature Xtraction SingDocument8 pagesF E U MFCC: Eature Xtraction SingKarl Martin AlduesoNo ratings yet
- Principles of Synthetic Aperture Radar: Surveys in Geophysics January 2000Document13 pagesPrinciples of Synthetic Aperture Radar: Surveys in Geophysics January 2000naveen narula100% (1)
- Exercises695Clas SolutionDocument13 pagesExercises695Clas SolutionHunAina Irshad100% (2)
- Chapter1 2Document15 pagesChapter1 2JagritiKumariNo ratings yet
- Bayesian Decision Theory: Robert Jacobs Department of Brain & Cognitive Sciences University of RochesterDocument40 pagesBayesian Decision Theory: Robert Jacobs Department of Brain & Cognitive Sciences University of RochesterRavi ShankerNo ratings yet
- SAR 28march2012 FinalDocument55 pagesSAR 28march2012 Finalnaveen narulaNo ratings yet
- Lembar Jawaban Skillab Evidence Based Edicine (Ebm) : Parameter Rerata SD RERATA+2sd Nilai AbnormalitasDocument26 pagesLembar Jawaban Skillab Evidence Based Edicine (Ebm) : Parameter Rerata SD RERATA+2sd Nilai Abnormalitassisil muntheNo ratings yet
- BioassayDocument38 pagesBioassayMuhammad Masoom AkhtarNo ratings yet
- What Is A Modal Verb - List of Modal Verbs - GingerDocument9 pagesWhat Is A Modal Verb - List of Modal Verbs - GingerPatricia ShantiNo ratings yet
- The Lair of Arachas - A Mausritter AdventureDocument8 pagesThe Lair of Arachas - A Mausritter AdventureGladstone PinheiroNo ratings yet
- FNHA First Nations Health Benefits Mental Health Provider ListDocument17 pagesFNHA First Nations Health Benefits Mental Health Provider ListJoel PanganibanNo ratings yet
- Bahia Slave RevoltDocument73 pagesBahia Slave Revoltalexandercarberry1543No ratings yet
- The New Jewish Wedding by Anita DiamantDocument39 pagesThe New Jewish Wedding by Anita DiamantSimon and Schuster27% (15)
- Resume-Sylvia MphofeDocument3 pagesResume-Sylvia Mphofeapi-346863907No ratings yet
- SAP Two-Phase CommitDocument39 pagesSAP Two-Phase CommitSudhanshu DuttaNo ratings yet
- Cyber Security Module 1Document4 pagesCyber Security Module 1silentnightNo ratings yet
- 117cherished MomentsDocument32 pages117cherished MomentsPilar Martín Zamora100% (1)
- 5 All India Mobile Database SampleDocument15 pages5 All India Mobile Database Sampleali khan Saifi100% (1)
- Notes BST - CH 1Document5 pagesNotes BST - CH 1Khushi KashyapNo ratings yet
- Transcript All Without NumberingDocument35 pagesTranscript All Without NumberingJohn Carl AparicioNo ratings yet
- Effectiveness of Workplace Counseling On Employee Performance. A Case of Mumias Sugar Company Limited, KenyaDocument10 pagesEffectiveness of Workplace Counseling On Employee Performance. A Case of Mumias Sugar Company Limited, KenyainventionjournalsNo ratings yet
- 1st International Conference On Foreign Language Teaching and Applied Linguistics (Sarajevo, 5-7 May 2011)Document38 pages1st International Conference On Foreign Language Teaching and Applied Linguistics (Sarajevo, 5-7 May 2011)Jasmin Hodžić100% (2)
- Guía BaccettiDocument11 pagesGuía BaccettiPercy Andree Bayona GuillermoNo ratings yet
- Benjamin Arnold, German Bishops and Their MilitaryDocument23 pagesBenjamin Arnold, German Bishops and Their MilitaryJoeNo ratings yet
- Learning Activity Sheet in 3is (Inquiries, Investigation, Immersion)Document5 pagesLearning Activity Sheet in 3is (Inquiries, Investigation, Immersion)Roselyn Relacion LucidoNo ratings yet
- Kudippaka" - in Kannur Politics An Investigation?Document8 pagesKudippaka" - in Kannur Politics An Investigation?Anonymous CwJeBCAXpNo ratings yet
- Puddu v. 6D Global Tech. - Securities Complaint PDFDocument57 pagesPuddu v. 6D Global Tech. - Securities Complaint PDFMark JaffeNo ratings yet
- The Legend of Magat RiverDocument1 pageThe Legend of Magat RiverMichael Clinton DionedaNo ratings yet
- (2019) 7 CLJ 560 PDFDocument12 pages(2019) 7 CLJ 560 PDFhuntaNo ratings yet
- Kinematics of MachineDocument4 pagesKinematics of MachineSumit KambleNo ratings yet
- Recruiting freelancers: Factors for firms to considerDocument2 pagesRecruiting freelancers: Factors for firms to consideroanh nguyen pham oanhNo ratings yet
- Barney ErrorDocument78 pagesBarney Erroralexiscerdadiaz100% (6)
- Mark Scheme (Results) : Summer 2018Document22 pagesMark Scheme (Results) : Summer 2018RafaNo ratings yet
- Charatible Trust FINAL BOOKDocument80 pagesCharatible Trust FINAL BOOKAmitNo ratings yet
- Philippine Supreme Court Decisions on Constitutionality of LawsDocument64 pagesPhilippine Supreme Court Decisions on Constitutionality of Lawswesternwound82No ratings yet
- Jude Sheerin (BBC/Sky - DC) Twitter DM Conversation - @supernanaDocument7 pagesJude Sheerin (BBC/Sky - DC) Twitter DM Conversation - @supernanaAlva FRENCH-N'GUESSANNo ratings yet