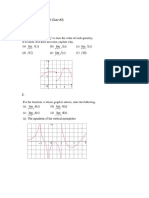
You might also like
- Limits and Continuity (Calculus) Engineering Entrance Exams Question BankFrom EverandLimits and Continuity (Calculus) Engineering Entrance Exams Question BankNo ratings yet
- Math4micro TheoryDocument27 pagesMath4micro Theoryhk9587952zNo ratings yet
- AM2 FTU Official 2022 Oct 16 C1Document29 pagesAM2 FTU Official 2022 Oct 16 C1Huy ĐoànNo ratings yet
- Concepts in Calculus I - Beta Version - 2011 - Miklos Bona - Sergei ShabanovDocument188 pagesConcepts in Calculus I - Beta Version - 2011 - Miklos Bona - Sergei ShabanovThomaz SennaNo ratings yet
- Mathcamp - Lec1 - KopiaDocument49 pagesMathcamp - Lec1 - KopiaPhilippeBourghardtNo ratings yet
- Partial Diffrentiation and Mutiple IntegralsDocument79 pagesPartial Diffrentiation and Mutiple IntegralsAnonymous GNWnQacNo ratings yet
- Basic Calculus and ApplicationsDocument22 pagesBasic Calculus and Applicationspriyadharshini869728No ratings yet
- GRADE 11 Learning Module 2 Semester Finals: General MathematicsDocument10 pagesGRADE 11 Learning Module 2 Semester Finals: General MathematicsNeil Trezley Sunico BalajadiaNo ratings yet
- Bcom BMT 1st Business MathDocument231 pagesBcom BMT 1st Business MathRajs MalikNo ratings yet
- Mat04 Calculu: Gilbert R. Esquillo, PmeDocument64 pagesMat04 Calculu: Gilbert R. Esquillo, PmeLuis NapolesNo ratings yet
- Limits and ContinuityDocument19 pagesLimits and ContinuityAnant KumarNo ratings yet
- Lecture 5 (For Student)Document40 pagesLecture 5 (For Student)Berwyn GazaliNo ratings yet
- Short Summary of Calculus MathDocument13 pagesShort Summary of Calculus MathBamidele ChristopherNo ratings yet
- Calc 1Document138 pagesCalc 1LuisNo ratings yet
- Calculus I OERDocument150 pagesCalculus I OERs140518No ratings yet
- Techniques of DifferentationDocument62 pagesTechniques of DifferentationFeridinand ThainisNo ratings yet
- Week 1 - General MathematicsDocument40 pagesWeek 1 - General MathematicsSirr AustriaNo ratings yet
- Lecture 23Document6 pagesLecture 23Syeda Farkhanda Batool NaqviNo ratings yet
- NLP NctuDocument19 pagesNLP NctularasmoyoNo ratings yet
- Application of IntregationDocument33 pagesApplication of IntregationasaNo ratings yet
- GEN MATH - Module (Banesio)Document124 pagesGEN MATH - Module (Banesio)Francis Sam Labasan SantañezNo ratings yet
- Characteristics of FunctionsDocument15 pagesCharacteristics of FunctionsDAVID ABDULSHUAIB AYEDUNNo ratings yet
- Ma1102R Calculus Lesson 5: Wang FeiDocument14 pagesMa1102R Calculus Lesson 5: Wang FeidelsonwiestNo ratings yet
- Octav Dragoi - Lagrange MultipliersDocument5 pagesOctav Dragoi - Lagrange MultipliersOctav DragoiNo ratings yet
- 311 Maths Eng Lesson25Document42 pages311 Maths Eng Lesson25Audie T. MataNo ratings yet
- Chapter 2 DifferentiationDocument4 pagesChapter 2 DifferentiationManel KricheneNo ratings yet
- Calculus - Lecture 4Document13 pagesCalculus - Lecture 4paramingirlNo ratings yet
- Basic CalculusDocument15 pagesBasic CalculusHanna GalatiNo ratings yet
- 1 Limits & Continuity NotesDocument82 pages1 Limits & Continuity Notesmseconroy84No ratings yet
- A Finite Element Primer: 1.3 4 October 2012Document25 pagesA Finite Element Primer: 1.3 4 October 2012Asad Muhammad ButtNo ratings yet
- Calculus BC For DummiesDocument12 pagesCalculus BC For DummiesJoon KoNo ratings yet
- ENMA 121 Module IDocument14 pagesENMA 121 Module ICarl Justin WattangNo ratings yet
- Gen Math ReviewerDocument8 pagesGen Math ReviewerBrian Benedict de CastroNo ratings yet
- Meyers Risk Aversion OptimizationDocument25 pagesMeyers Risk Aversion OptimizationAdnan KamalNo ratings yet
- 2.1 Derivatives of Algebraic and Transcendental FunctionsDocument15 pages2.1 Derivatives of Algebraic and Transcendental FunctionsFabie BarcenalNo ratings yet
- Mathematical Economics (ECON 471) Unconstrained & Constrained OptimizationDocument20 pagesMathematical Economics (ECON 471) Unconstrained & Constrained OptimizationLilia XaNo ratings yet
- Lecture Notes 5Document10 pagesLecture Notes 5Joey DeprinceNo ratings yet
- FEM PrimerDocument26 pagesFEM Primerted_kordNo ratings yet
- Class 1Document86 pagesClass 1allan surasepNo ratings yet
- Chapter 4: Mathematical Functions: Lecture 04,05Document6 pagesChapter 4: Mathematical Functions: Lecture 04,05Chaqib SultanNo ratings yet
- A Method To Find The Best Mixed Polarity Reed-Muller ExpansionDocument52 pagesA Method To Find The Best Mixed Polarity Reed-Muller Expansionأيوب حسنNo ratings yet
- Convexity Examples: CE 377K Stephen D. Boyles Spring 2015Document11 pagesConvexity Examples: CE 377K Stephen D. Boyles Spring 2015hoalongkiemNo ratings yet
- Connexions Module: m11240Document4 pagesConnexions Module: m11240rajeshagri100% (2)
- Micromof2015 151224080824Document310 pagesMicromof2015 151224080824MarksNo ratings yet
- Functional AnalysisDocument93 pagesFunctional Analysisbala_muraliNo ratings yet
- Chapter One 1.1. Theoretical Versus Mathematical Economics Example. ExampleDocument19 pagesChapter One 1.1. Theoretical Versus Mathematical Economics Example. ExampleEnyewNo ratings yet
- JO Ao Lopes DiasDocument19 pagesJO Ao Lopes DiasRosita Salas TuanamaNo ratings yet
- Dylan S Primeri Handouts-7Document13 pagesDylan S Primeri Handouts-7Weerasak BoonwuttiwongNo ratings yet
- DiffrentiationDocument16 pagesDiffrentiationfathalla tarekNo ratings yet
- Lesson 2 - Functions and Their Graphs - NOTESDocument65 pagesLesson 2 - Functions and Their Graphs - NOTESAilyn DelpuertoNo ratings yet
- Maths For Mgt. (Chapter 5)Document17 pagesMaths For Mgt. (Chapter 5)Dawit Mekonnen100% (1)
- LP1 Math1 Unit1 Edited-082321Document15 pagesLP1 Math1 Unit1 Edited-082321hajiNo ratings yet
- Unit One Mathematical EconomicsDocument15 pagesUnit One Mathematical EconomicsSitra AbduNo ratings yet
- Mod4-The Definite Integral Methods of IntegrationDocument15 pagesMod4-The Definite Integral Methods of Integrationjerick.magadiaNo ratings yet
- Calculus RevisedDocument23 pagesCalculus RevisedAngela Laine HiponiaNo ratings yet
- MST121 Chapter A3 FunctionsDocument64 pagesMST121 Chapter A3 FunctionsbarryNo ratings yet
- Difference Equations in Normed Spaces: Stability and OscillationsFrom EverandDifference Equations in Normed Spaces: Stability and OscillationsNo ratings yet
- Econ 303 Problem Set #2Document1 pageEcon 303 Problem Set #2Mary Catherine Almonte - EmbateNo ratings yet
- Econ 303 Section 2.1Document30 pagesEcon 303 Section 2.1Mary Catherine Almonte - EmbateNo ratings yet
- Econ 303 Problem Set #4 (Prelim Exam)Document1 pageEcon 303 Problem Set #4 (Prelim Exam)Mary Catherine Almonte - EmbateNo ratings yet
- Econ 303 Section 2.1Document30 pagesEcon 303 Section 2.1Mary Catherine Almonte - EmbateNo ratings yet
- Econ 303 Problem Set #3 (Quiz #3)Document3 pagesEcon 303 Problem Set #3 (Quiz #3)Mary Catherine Almonte - EmbateNo ratings yet
- Econ 303 Problem Set #4 (Prelim Exam)Document1 pageEcon 303 Problem Set #4 (Prelim Exam)Mary Catherine Almonte - EmbateNo ratings yet
- Econ 303 Problem Set #1 FinalsDocument1 pageEcon 303 Problem Set #1 FinalsMary Catherine Almonte - EmbateNo ratings yet
- Econ 303 OutlineDocument5 pagesEcon 303 OutlineMary Catherine Almonte - EmbateNo ratings yet
- Econ 303 Problem Set #1Document1 pageEcon 303 Problem Set #1Mary Catherine Almonte - EmbateNo ratings yet
- Econ 303 Problem Set #1 FinalsDocument1 pageEcon 303 Problem Set #1 FinalsMary Catherine Almonte - EmbateNo ratings yet
- Econ 303 Midterm ExamDocument1 pageEcon 303 Midterm ExamMary Catherine Almonte - EmbateNo ratings yet
- IntermediateDocument89 pagesIntermediateYanjing KeNo ratings yet
- Econ 303 Chapter 1Document49 pagesEcon 303 Chapter 1Mary Catherine Almonte - EmbateNo ratings yet
- Econ 303 OutlineDocument5 pagesEcon 303 OutlineMary Catherine Almonte - EmbateNo ratings yet
- ECON203Document58 pagesECON203CharlotteNo ratings yet
- The Consumer Problem and How To Solve ItDocument7 pagesThe Consumer Problem and How To Solve ItMary Catherine Almonte - EmbateNo ratings yet
- Econ 303 Midterm ExamDocument1 pageEcon 303 Midterm ExamMary Catherine Almonte - EmbateNo ratings yet
- 1633-Article Text-6473-1-10-20110125Document10 pages1633-Article Text-6473-1-10-20110125Mary Catherine Almonte - EmbateNo ratings yet
- Intermediate Micro With Calc. ProblemsDocument3 pagesIntermediate Micro With Calc. ProblemsDunbar AndersNo ratings yet
- A Consumer's Constrained ChoiceDocument33 pagesA Consumer's Constrained ChoiceMary Catherine Almonte - EmbateNo ratings yet
- How To Teach Hicksian Compensation and Duality Using A Spreadsheet OptimizerDocument10 pagesHow To Teach Hicksian Compensation and Duality Using A Spreadsheet OptimizerMary Catherine Almonte - EmbateNo ratings yet
- 2 Topic ChoiceDocument25 pages2 Topic ChoiceMary Catherine Almonte - EmbateNo ratings yet
- Solving Consumer Choice ProblemsDocument3 pagesSolving Consumer Choice ProblemsUtkarshNo ratings yet
- Admin, Journal Manager, pp25-29MS216finalDocument5 pagesAdmin, Journal Manager, pp25-29MS216finalMary Catherine Almonte - EmbateNo ratings yet
- Applied de Bert inDocument254 pagesApplied de Bert inyayaskyuNo ratings yet
- Intermediate Microeconomics: Fudan UniversityDocument4 pagesIntermediate Microeconomics: Fudan UniversityMary Catherine Almonte - EmbateNo ratings yet
- Revised PDP PlanDocument385 pagesRevised PDP PlanMary Catherine Almonte - EmbateNo ratings yet
- Revised PDP PlanDocument385 pagesRevised PDP PlanMary Catherine Almonte - EmbateNo ratings yet
- Slide 7: Streamline Processes For Speedy Resolution of Criminal and Civil CasesDocument7 pagesSlide 7: Streamline Processes For Speedy Resolution of Criminal and Civil CasesMary Catherine Almonte - EmbateNo ratings yet
- Gauss-Codazzi EquationsDocument5 pagesGauss-Codazzi EquationsaguiNo ratings yet
- 1.1-1.4 Basic Concepts of VectorsDocument16 pages1.1-1.4 Basic Concepts of VectorsyslnjuNo ratings yet
- Calculus IIIvectorcalculus 2011Document82 pagesCalculus IIIvectorcalculus 2011Alfi LouisNo ratings yet
- 3d - Wave EquationDocument3 pages3d - Wave EquationzubairNo ratings yet
- Unit-6.PDF Engg MathDocument56 pagesUnit-6.PDF Engg MathSudersanaViswanathanNo ratings yet
- Book EngDocument133 pagesBook Engmalav8049No ratings yet
- Jenis Kabel TM Dan TRDocument6 pagesJenis Kabel TM Dan TRrangga riswanNo ratings yet
- ثالث معادلات جزئيةDocument26 pagesثالث معادلات جزئيةAli Hyder KolachiNo ratings yet
- 5.6 The Curl of A Vector FieldDocument1 page5.6 The Curl of A Vector FieldRubensVilhenaFonsecaNo ratings yet
- Curvature Formulas For Implicit Curves and Surfaces: Computer Aided Geometric Design October 2005Document28 pagesCurvature Formulas For Implicit Curves and Surfaces: Computer Aided Geometric Design October 2005CESAR ERNESTO ROQUE CISNEROSNo ratings yet
- Tensor Analysis: Presented byDocument16 pagesTensor Analysis: Presented byarun kumarNo ratings yet
- Weekly Test 2 Engineering MechanicsDocument3 pagesWeekly Test 2 Engineering MechanicsAnonymous RJfsy8PtNo ratings yet
- AMATH 231 Calculus IV Solutions A6Document5 pagesAMATH 231 Calculus IV Solutions A6Forsen ShungiteNo ratings yet
- A PERSONAL PROOF of The STOKES' THEOREM-Una Dimostrazione Personale Del Teorema Di StokesDocument2 pagesA PERSONAL PROOF of The STOKES' THEOREM-Una Dimostrazione Personale Del Teorema Di StokesLeonardo RubinoNo ratings yet
- Math 2230 - Problem Set 1 2018Document3 pagesMath 2230 - Problem Set 1 2018Andrew MahadeoNo ratings yet
- Elliptic Partial Differential Equations Solution in Cartesian Coordinate SystemDocument5 pagesElliptic Partial Differential Equations Solution in Cartesian Coordinate SystemShivam SharmaNo ratings yet
- CH 3 Vector CalculusDocument16 pagesCH 3 Vector CalculusHemal ParikhNo ratings yet
- Mth166:Differential Equations and Vector Calculus: Session 2021-22 Page:1/1Document1 pageMth166:Differential Equations and Vector Calculus: Session 2021-22 Page:1/1Mohit RajNo ratings yet
- Mathematics (Vector Analysis) 1Document3 pagesMathematics (Vector Analysis) 1chetan HRNo ratings yet
- Surface Area and Surface Integrals. (Sect. 16.6) : TheoremDocument8 pagesSurface Area and Surface Integrals. (Sect. 16.6) : TheoremTidal SurgesNo ratings yet
- Partial Differential Equations (Pdes)Document5 pagesPartial Differential Equations (Pdes)uploadingpersonNo ratings yet
- Multivariate Calculus: Unit OneDocument26 pagesMultivariate Calculus: Unit OneErnest YeboahNo ratings yet
- Multivariable Calculus: 1 Typical OperationsDocument3 pagesMultivariable Calculus: 1 Typical Operationsanon_482623913100% (1)
- Unit-Iii Electromagnetic Waves - NotesDocument13 pagesUnit-Iii Electromagnetic Waves - NotesAnusha KovuruNo ratings yet
- Vector Calculus: R NaveDocument2 pagesVector Calculus: R NavegsigalaoNo ratings yet
- Vector CalculusDocument27 pagesVector CalculusHarpreetSinghNo ratings yet
- Skills Check Extra 2ADocument1 pageSkills Check Extra 2AVishmi JayawardeneNo ratings yet
- EMFW Course Guide Book PDFDocument4 pagesEMFW Course Guide Book PDFYohanes KassuNo ratings yet
- Derivatives of Multivariable FunctionDocument101 pagesDerivatives of Multivariable FunctionAna MaciasNo ratings yet
- Charpits MethodDocument24 pagesCharpits Methodabul hasanNo ratings yet