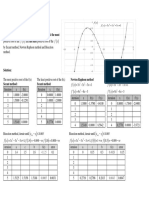
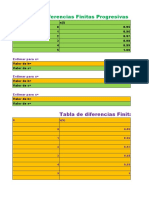
You might also like
- Lecture-13 - ESO208 - Aug 31 - 2022Document28 pagesLecture-13 - ESO208 - Aug 31 - 2022Imad ShaikhNo ratings yet
- Saqib Ali-13015 (NC Lab # 4)Document4 pagesSaqib Ali-13015 (NC Lab # 4)saqib aliNo ratings yet
- 2.2 Exercises With Matlab: 2.2.1 Standard Normal DistributionDocument9 pages2.2 Exercises With Matlab: 2.2.1 Standard Normal Distributionabymani004No ratings yet
- Crash CourseDocument11 pagesCrash CourseHenrik AnderssonNo ratings yet
- 15 - Solutions of Algebric and Transcendental Equations PDFDocument34 pages15 - Solutions of Algebric and Transcendental Equations PDFrishav aggarwalNo ratings yet
- State-Space SystemDocument23 pagesState-Space SystemOmar ElsayedNo ratings yet
- QP 19SS QEStat AccessibleDocument8 pagesQP 19SS QEStat AccessibleHIMANINo ratings yet
- Kashif NC Lab 4Document4 pagesKashif NC Lab 4saqib aliNo ratings yet
- Tutorial Chapter 2Document2 pagesTutorial Chapter 2noraNo ratings yet
- Apm2613 203 0 2022Document9 pagesApm2613 203 0 2022Darrel van OnselenNo ratings yet
- Matlab - Introduction SlidesDocument52 pagesMatlab - Introduction SlidesFernanda ModkowskiNo ratings yet
- Loss Modeling Features of ActuarDocument15 pagesLoss Modeling Features of ActuarToniNo ratings yet
- Tarea 5Document6 pagesTarea 5Alejandra Hernández ValenzoNo ratings yet
- Numerical DifferentiationsDocument6 pagesNumerical DifferentiationsSaurabh TomarNo ratings yet
- Clustering Fraud DetectionDocument45 pagesClustering Fraud DetectionsuperluigiNo ratings yet
- Cálculos AV2 - Cálculo NuméricoDocument9 pagesCálculos AV2 - Cálculo NuméricoMarcio MoreiraNo ratings yet
- Universidad Nacional Del Altiplano: Capitulo 0Document35 pagesUniversidad Nacional Del Altiplano: Capitulo 0Alexander ChinoNo ratings yet
- Introduction To MatlabDocument34 pagesIntroduction To MatlabRasheed KibriaNo ratings yet
- Uocmath M 01 03 11 17 29 31 37 38 52 59Document8 pagesUocmath M 01 03 11 17 29 31 37 38 52 59Iqra NoureenNo ratings yet
- Intoduction To AtlabDocument59 pagesIntoduction To AtlabMaria Jafar KhanNo ratings yet
- Principles 2 PDFDocument17 pagesPrinciples 2 PDFHasan AkhuamariNo ratings yet
- Functions and Their Graphs: 2.4 Library of Functions Piecewise-Defined FunctionsDocument6 pagesFunctions and Their Graphs: 2.4 Library of Functions Piecewise-Defined FunctionsRicardo PlasenciaNo ratings yet
- Lecture Notes 7Document18 pagesLecture Notes 7Hussain AldurazyNo ratings yet
- Newton Raphson MethodDocument6 pagesNewton Raphson Methodfake7083No ratings yet
- Calc. II-1Document45 pagesCalc. II-1Gebretsadik GebregergisNo ratings yet
- Matlab For Pattern RecognitionDocument58 pagesMatlab For Pattern RecognitionmiusayNo ratings yet
- Lab 1 Introduction To MATLABDocument35 pagesLab 1 Introduction To MATLABAbdul RehmanNo ratings yet
- Week11 Integration - KhoirulDocument48 pagesWeek11 Integration - KhoirulsupergioNo ratings yet
- Multimedia - Eng.ukm - My JKMB Kamal CM Chapter3Document22 pagesMultimedia - Eng.ukm - My JKMB Kamal CM Chapter3Mani KumarNo ratings yet
- Mapanoo Melchizedek V Cve208 SS21-22 Ce2b PN1Document19 pagesMapanoo Melchizedek V Cve208 SS21-22 Ce2b PN1EmmanNo ratings yet
- Asg 1 NumecDocument11 pagesAsg 1 NumecNurul SyafiqahNo ratings yet
- Sa 123Document13 pagesSa 123Mehak AgarwalNo ratings yet
- MAFE208IU-L3 - Open Methods - Nonlinear EquationsDocument22 pagesMAFE208IU-L3 - Open Methods - Nonlinear EquationsThy VũNo ratings yet
- Chapter 3Document26 pagesChapter 3Renukadevi Rpt33% (3)
- Lecture Notes On Pattern Recognition and Image ProcessingDocument24 pagesLecture Notes On Pattern Recognition and Image ProcessingManojNo ratings yet
- 3 Discrete Random Variables and Probability DistributionsDocument26 pages3 Discrete Random Variables and Probability DistributionsRenukadevi RptNo ratings yet
- Truss 070505Document147 pagesTruss 070505Leonardo PimentelNo ratings yet
- 5 Numerical DifferenciationDocument8 pages5 Numerical DifferenciationSaiful IslamNo ratings yet
- Bma1104cat 1Document5 pagesBma1104cat 1nyukuricpakNo ratings yet
- WINSEM2019-20 MAT2001 ELA VL2019205002696 Reference Material I 31-Jan-2020 7 R LAB - Normal DistributionDocument38 pagesWINSEM2019-20 MAT2001 ELA VL2019205002696 Reference Material I 31-Jan-2020 7 R LAB - Normal Distributionjeevan saiNo ratings yet
- Some Solved QuestionsDocument53 pagesSome Solved QuestionsEdwin Okoampa BoaduNo ratings yet
- An Introduction To Extreme Order Statistics and Actuarial ApplicationsDocument54 pagesAn Introduction To Extreme Order Statistics and Actuarial ApplicationsĐặng Minh TháiNo ratings yet
- # Experiment Name: Introduction To MATLABDocument10 pages# Experiment Name: Introduction To MATLABOmor Hasan Al BoshirNo ratings yet
- Numerical Integration CH 6Document5 pagesNumerical Integration CH 6Coder DNo ratings yet
- Fault Detection Using Data Based ModelsDocument14 pagesFault Detection Using Data Based ModelsPierpaolo VergatiNo ratings yet
- Intoduction To MATLABDocument32 pagesIntoduction To MATLABDania KhattakNo ratings yet
- NONLINEAR Bisection Method Example: F (X) X 3+x 2-3x-3 0Document5 pagesNONLINEAR Bisection Method Example: F (X) X 3+x 2-3x-3 0SherylDinglasanFenol0% (1)
- Universiti Tunku Abdul Rahman Faculty of Science: Lim Xue Qi 16ADB03823 Loo Xin Yi 16ADB04027Document19 pagesUniversiti Tunku Abdul Rahman Faculty of Science: Lim Xue Qi 16ADB03823 Loo Xin Yi 16ADB04027Yew Wen KhangNo ratings yet
- Ejercicio - 19Document23 pagesEjercicio - 19Diego Kadù Desposorio MendezNo ratings yet
- Tối Ưu Hóa Cho Khoa Học Dữ LiệuDocument64 pagesTối Ưu Hóa Cho Khoa Học Dữ Liệuminhpc2911No ratings yet
- Monte Carlo Simulation: MATH 182Document18 pagesMonte Carlo Simulation: MATH 182Roland ToledoNo ratings yet
- Introduction To Matlab 2Document34 pagesIntroduction To Matlab 2Deepak Kumar SinghNo ratings yet
- Introduction To Matlab: By: DR - Narmada AlaparthiDocument34 pagesIntroduction To Matlab: By: DR - Narmada AlaparthinarmadaNo ratings yet
- Basic Simulation File-41-45Document5 pagesBasic Simulation File-41-45San MikeNo ratings yet
- WINSEM2019 20 MAT2001 ELA VL2019205002696 Reference Material I 31 Jan 2020 7 R LAB Normal DistributionDocument39 pagesWINSEM2019 20 MAT2001 ELA VL2019205002696 Reference Material I 31 Jan 2020 7 R LAB Normal DistributionasNo ratings yet
- HW03 Spring 2024Document2 pagesHW03 Spring 2024forgamesforgames7No ratings yet
- Linear RegressionDocument19 pagesLinear RegressionKarthikeya ShukklaNo ratings yet
- Time Series Analysis: Statistical TechniquesDocument15 pagesTime Series Analysis: Statistical TechniquesSuson Dhital100% (2)
- Green's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)From EverandGreen's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)No ratings yet
- 2060A Ex 3 2019Document2 pages2060A Ex 3 2019Samuel Alfonzo Gil BarcoNo ratings yet
- 2050C Problem Set 3Document1 page2050C Problem Set 3Samuel Alfonzo Gil BarcoNo ratings yet
- 2060A Ex 5 2019Document1 page2060A Ex 5 2019Samuel Alfonzo Gil BarcoNo ratings yet
- 2060A Ex 4 2019Document1 page2060A Ex 4 2019Samuel Alfonzo Gil BarcoNo ratings yet
- 2050C Problem Set 2Document1 page2050C Problem Set 2Samuel Alfonzo Gil BarcoNo ratings yet
- 2050C Problem Set 1Document1 page2050C Problem Set 1Samuel Alfonzo Gil BarcoNo ratings yet
- 2060A Ex 2 2019Document1 page2060A Ex 2 2019Samuel Alfonzo Gil BarcoNo ratings yet
- 2060A Ex 1 2019Document4 pages2060A Ex 1 2019Samuel Alfonzo Gil BarcoNo ratings yet
- 2050C Problem Set 4Document1 page2050C Problem Set 4Samuel Alfonzo Gil BarcoNo ratings yet
- 2050C Problem Set 3Document1 page2050C Problem Set 3Samuel Alfonzo Gil BarcoNo ratings yet
- 2050C Problem Set 0Document1 page2050C Problem Set 0Samuel Alfonzo Gil BarcoNo ratings yet
- 2050C Problem Set 4Document1 page2050C Problem Set 4Samuel Alfonzo Gil BarcoNo ratings yet
- 2050C Problem Set 2Document1 page2050C Problem Set 2Samuel Alfonzo Gil BarcoNo ratings yet
- 2050C Problem Set 1Document1 page2050C Problem Set 1Samuel Alfonzo Gil BarcoNo ratings yet
- 2050 B HW 1 SolDocument4 pages2050 B HW 1 SolSamuel Alfonzo Gil BarcoNo ratings yet
- MATH2050a Mathematical Analysis I: Exercise 8 Suggested SolutionDocument3 pagesMATH2050a Mathematical Analysis I: Exercise 8 Suggested SolutionSamuel Alfonzo Gil BarcoNo ratings yet
- TA's Solution To 2050B Homework 5: N N N N NDocument4 pagesTA's Solution To 2050B Homework 5: N N N N NSamuel Alfonzo Gil BarcoNo ratings yet
- 2050C Problem Set 0Document1 page2050C Problem Set 0Samuel Alfonzo Gil BarcoNo ratings yet
- This Solution Is Adapted From The Work by Former Tas.: N M N M N MDocument4 pagesThis Solution Is Adapted From The Work by Former Tas.: N M N M N MSamuel Alfonzo Gil BarcoNo ratings yet
- Solution to 2050B assignment 3: ∃N ∈ N N ≤ x ≤ βDocument2 pagesSolution to 2050B assignment 3: ∃N ∈ N N ≤ x ≤ βSamuel Alfonzo Gil BarcoNo ratings yet
- 2050A Solution 2Document2 pages2050A Solution 2Samuel Alfonzo Gil BarcoNo ratings yet
- 2050 Atset 2018Document2 pages2050 Atset 2018Samuel Alfonzo Gil BarcoNo ratings yet
- MATH2050a Mathematical Analysis I: Exercise 7 Suggested SolutionDocument2 pagesMATH2050a Mathematical Analysis I: Exercise 7 Suggested SolutionSamuel Alfonzo Gil BarcoNo ratings yet
- MATH2050a Mathematical Analysis I: Exercise 4 Suggested SolutionDocument2 pagesMATH2050a Mathematical Analysis I: Exercise 4 Suggested SolutionSamuel Alfonzo Gil BarcoNo ratings yet
- 2050A Solution 1Document2 pages2050A Solution 1Samuel Alfonzo Gil BarcoNo ratings yet
- MATH2050a Mathematical Analysis I: Exercise 6 Suggested SolutionDocument2 pagesMATH2050a Mathematical Analysis I: Exercise 6 Suggested SolutionSamuel Alfonzo Gil BarcoNo ratings yet
- 2050A Solution 3Document2 pages2050A Solution 3Samuel Alfonzo Gil BarcoNo ratings yet
- MATH2050a Mathematical Analysis I: Exercise 5 Suggested SolutionDocument1 pageMATH2050a Mathematical Analysis I: Exercise 5 Suggested SolutionSamuel Alfonzo Gil BarcoNo ratings yet
- 2050A Solution 1Document2 pages2050A Solution 1Samuel Alfonzo Gil BarcoNo ratings yet
- Solving Dual Problems: 1 M T 1 1 T R RDocument14 pagesSolving Dual Problems: 1 M T 1 1 T R RSamuel Alfonzo Gil BarcoNo ratings yet
- I-O BoardDocument7 pagesI-O BoardBoris MaldonadoNo ratings yet
- Operating System ServicesDocument4 pagesOperating System ServicesCassandra KarolinaNo ratings yet
- Foundations of Computer Science - Chapter 1Document34 pagesFoundations of Computer Science - Chapter 1Shaun NevilleNo ratings yet
- Directx SDK EulaDocument6 pagesDirectx SDK Eulaanon-117073100% (1)
- SINUMERIK 808D Diagnostics Manual 201212 EngDocument324 pagesSINUMERIK 808D Diagnostics Manual 201212 EngpsilvamarNo ratings yet
- Automation of Interview Scheduling Process AbstractDocument4 pagesAutomation of Interview Scheduling Process AbstractTelika RamuNo ratings yet
- Hybrid Cloud Observability - Network Monitoring Participant's GuideDocument35 pagesHybrid Cloud Observability - Network Monitoring Participant's GuideAnggaraNo ratings yet
- A Step-by-Step Guide To Remote Sensing and GISDocument55 pagesA Step-by-Step Guide To Remote Sensing and GISchristine sNo ratings yet
- Blood Donation Management SystemDocument13 pagesBlood Donation Management SystemAJER JOURNAL94% (16)
- Gastritis: Free TemplatesDocument57 pagesGastritis: Free TemplatesJonathanNo ratings yet
- Activity 3 Array and Arc Drawing: Link To Lecture 3 - Https://youtu - be/Ps-mT5Cl0gkDocument2 pagesActivity 3 Array and Arc Drawing: Link To Lecture 3 - Https://youtu - be/Ps-mT5Cl0gkRobert MacalanaoNo ratings yet
- Manual TestingDocument37 pagesManual Testingapi-3815323100% (4)
- Curriculum VitaeDocument2 pagesCurriculum Vitaevenki125No ratings yet
- Excel MacrosDocument2 pagesExcel MacrosSudarshan RaoNo ratings yet
- Lab 3.1 Configuring SDM On A RouterDocument34 pagesLab 3.1 Configuring SDM On A Routergargamel_220No ratings yet
- History The Six Invariants of Spiral ModelDocument4 pagesHistory The Six Invariants of Spiral ModelsuhailNo ratings yet
- Python Full StackDocument8 pagesPython Full StackTikendra Kumar PalNo ratings yet
- Role of Mis in PlanningDocument3 pagesRole of Mis in PlanningJjjo ChitimbeNo ratings yet
- Rift Valley University Bishoftu CampusDocument58 pagesRift Valley University Bishoftu CampusAyansa TeshomeNo ratings yet
- Mpal 8Document48 pagesMpal 8ifrah shujaNo ratings yet
- BSSPAR - Chapter 03 - Radio - Resource - Management - MODocument26 pagesBSSPAR - Chapter 03 - Radio - Resource - Management - MOSamir Mezouar100% (1)
- Computing Project: Topic 1Document45 pagesComputing Project: Topic 1Kay TunNo ratings yet
- Computer Skills: MS Programs & The Internet Section 1, Page 1 of 17Document17 pagesComputer Skills: MS Programs & The Internet Section 1, Page 1 of 17Michael FissehaNo ratings yet
- Rashi Mahawar: Area of InterestDocument2 pagesRashi Mahawar: Area of InterestRashi MahawarNo ratings yet
- CD 14016Document6 pagesCD 14016amitkraj25No ratings yet
- Everyday Practical Electronics - August 2016Document77 pagesEveryday Practical Electronics - August 20161553No ratings yet
- BAdi2 For MM02Document14 pagesBAdi2 For MM02raju221756_843567682100% (1)
- GST List of PatchesDocument13 pagesGST List of PatchesdurairajNo ratings yet
- LTE CR-7077 Operation GraphsDocument135 pagesLTE CR-7077 Operation GraphsAdil MuradNo ratings yet
- PPS MCQ Unit IIDocument61 pagesPPS MCQ Unit IIAdvait KeskarNo ratings yet