You might also like
- Tolerance FinderDocument4 pagesTolerance FinderAmit100% (2)
- NAT REVIEWER Statistics ProbabilityDocument7 pagesNAT REVIEWER Statistics Probabilitybertz sumaylo100% (2)
- MCR3U Final Exam Review (June2010)Document6 pagesMCR3U Final Exam Review (June2010)Erin Guerrero100% (1)
- IASSC Green Belt Body of KnowledgeDocument5 pagesIASSC Green Belt Body of KnowledgeBilal Salameh50% (2)
- MCQ Business StatisticsDocument41 pagesMCQ Business StatisticsShivani Kapoor0% (1)
- Descriptive Statistics OverviewDocument8 pagesDescriptive Statistics Overviewchanus19100% (2)
- Chapter 8 Simple Linear RegressionDocument17 pagesChapter 8 Simple Linear RegressionNur Iffatin100% (2)
- Mid Term UmtDocument4 pagesMid Term Umtfazalulbasit9796No ratings yet
- HSC Trial Exam Mathematics Advanced Section II Answer BookletDocument33 pagesHSC Trial Exam Mathematics Advanced Section II Answer Bookletwill100% (1)
- Introductory Statistics A Problem Solving Approach - 2nd EditionDocument890 pagesIntroductory Statistics A Problem Solving Approach - 2nd EditionManuel Guardia Araujo100% (2)
- (Brajendra C. Sutradhar) Longitudinal Categorical Data Analysis (PDF) (ZZZZZ)Document387 pages(Brajendra C. Sutradhar) Longitudinal Categorical Data Analysis (PDF) (ZZZZZ)Tchakounte NjodaNo ratings yet
- A. What Percentage of Parts Will Not Meet The Weight Specs?Document10 pagesA. What Percentage of Parts Will Not Meet The Weight Specs?Allen KateNo ratings yet
- Additional Problem Set Units I and IIDocument9 pagesAdditional Problem Set Units I and IISpider ManNo ratings yet
- Econometrics I Quiz 1 Spring 2022Document4 pagesEconometrics I Quiz 1 Spring 2022Esha IftikharNo ratings yet
- Econometrics Problem Set 2 SolutionsDocument2 pagesEconometrics Problem Set 2 SolutionsMahnoorNo ratings yet
- Assignment 2 ECO204 PDFDocument3 pagesAssignment 2 ECO204 PDFsochNo ratings yet
- Maths and Stats Prep EssentialsDocument12 pagesMaths and Stats Prep Essentialsdevansh kakkarNo ratings yet
- Problem Set 03 - SolutionsDocument16 pagesProblem Set 03 - Solutionsecemakin21No ratings yet
- Econ 115 D - Probset 1Document3 pagesEcon 115 D - Probset 1zhess 4096No ratings yet
- Exercises and Cases in EconometricsDocument30 pagesExercises and Cases in EconometricsFreya GrantNo ratings yet
- Prep For Fe Sol Qr15Document5 pagesPrep For Fe Sol Qr15chumnhomauxanhNo ratings yet
- General: Quarter 1 - Week 1Document18 pagesGeneral: Quarter 1 - Week 1ARNEL GONZALESNo ratings yet
- 3 April 8- Exponenial ModelsDocument10 pages3 April 8- Exponenial ModelstarunikabharathNo ratings yet
- Problem Set 5Document5 pagesProblem Set 5Sila KapsataNo ratings yet
- annual ques bank 11th commerceDocument2 pagesannual ques bank 11th commercealokkulkarni14No ratings yet
- Age Wage: WAGE Predicted To Increase If Age Is Increased by 5 Years?Document3 pagesAge Wage: WAGE Predicted To Increase If Age Is Increased by 5 Years?Jadon BuzzardNo ratings yet
- IAL Statistic 1 Revision Worksheet Month 4Document4 pagesIAL Statistic 1 Revision Worksheet Month 4Le Jeu LifeNo ratings yet
- Sample Paper Mid 2Document10 pagesSample Paper Mid 2samiha.rahman05No ratings yet
- CS132Module2Notes by DMiguelDocument7 pagesCS132Module2Notes by DMiguelDhuanne EstradaNo ratings yet
- STTN225 Small Test1 MEMODocument5 pagesSTTN225 Small Test1 MEMOmaya valentyneNo ratings yet
- Sample QuestionsDocument5 pagesSample Questionsihab awwadNo ratings yet
- Statistics GIDP Ph.D. Qualifying Exam Methodology: January 10, 9:00am-1:00pmDocument20 pagesStatistics GIDP Ph.D. Qualifying Exam Methodology: January 10, 9:00am-1:00pmMd. Mujahidul IslamNo ratings yet
- SS2 Maths Lesson Note PDFDocument104 pagesSS2 Maths Lesson Note PDFdnlbalogun100% (1)
- Sem - III Business Mathematics Yearly PaperDocument12 pagesSem - III Business Mathematics Yearly Paperoc698067No ratings yet
- Calculus_Week2Document7 pagesCalculus_Week2Dang Xuan MaiNo ratings yet
- Exam AFF700 211210 - SolutionsDocument11 pagesExam AFF700 211210 - Solutionsnnajichinedu20No ratings yet
- Algebra Worksheet N°1 Concept of Fuction: Mathematics Program Algebra MAT2000Document7 pagesAlgebra Worksheet N°1 Concept of Fuction: Mathematics Program Algebra MAT2000Viviana Jiménez.No ratings yet
- Econometrics Assignment 1 AnswersDocument8 pagesEconometrics Assignment 1 AnswersHan ChenNo ratings yet
- QP - Applied Mathematics - XIIDocument10 pagesQP - Applied Mathematics - XIIBhakttipriya SrinivasanNo ratings yet
- (Time: Hours) (Marks: 75) Please Check Whether You Have Got The Right Question PaperDocument16 pages(Time: Hours) (Marks: 75) Please Check Whether You Have Got The Right Question PaperTushar VazeNo ratings yet
- Regression and CorrelationDocument2 pagesRegression and CorrelationKhurram ShahzadaNo ratings yet
- Exercise Prod Design PracticingDocument9 pagesExercise Prod Design PracticingLaura AlósNo ratings yet
- Econometrics exercises: Estimating LRMDocument24 pagesEconometrics exercises: Estimating LRMnishit0157623637No ratings yet
- Job Satisfaction of College Instructors by Years of ServiceDocument4 pagesJob Satisfaction of College Instructors by Years of ServiceElonic AirosNo ratings yet
- Sub-Math Holiday Work S.5Document4 pagesSub-Math Holiday Work S.5musokelukia6No ratings yet
- BusStat 2023 HW13 Chapter 13Document3 pagesBusStat 2023 HW13 Chapter 13Friscilia OrlandoNo ratings yet
- QUIZ (Objectives) Identification: - (Residual)Document5 pagesQUIZ (Objectives) Identification: - (Residual)MarlNo ratings yet
- F12 - 2023 - Statistical ModuleDocument30 pagesF12 - 2023 - Statistical ModuleAbdirahman NurNo ratings yet
- Holiday Assignment On Phy 107Document2 pagesHoliday Assignment On Phy 107Enyiogu AbrahamNo ratings yet
- Chi-Square: Example ProblemDocument7 pagesChi-Square: Example ProblemZsa ChuNo ratings yet
- DC Final Review 2021Document5 pagesDC Final Review 2021Jimena Jaqueline Yañez SalazarNo ratings yet
- Activity Sheet 2Document4 pagesActivity Sheet 2Ann CantilloNo ratings yet
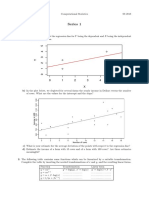
- Series 1Document2 pagesSeries 1Sangwoo KimNo ratings yet
- Econometrics Assignment MBA - 2Document3 pagesEconometrics Assignment MBA - 2Teketel chemesaNo ratings yet
- SLA - Class Test - 1 - AnswerKeyDocument4 pagesSLA - Class Test - 1 - AnswerKeycadi0761No ratings yet
- 2021-22 Ordinaria ENUNCIADO - ENGLISH - SolutionsDocument6 pages2021-22 Ordinaria ENUNCIADO - ENGLISH - SolutionsIker PildainNo ratings yet
- Business Statistics (Exercise 1)Document3 pagesBusiness Statistics (Exercise 1)مہر علی حیدر33% (3)
- EJERCICIOSIDocument41 pagesEJERCICIOSIRossana María López ViramontesNo ratings yet
- Vector Field1Document45 pagesVector Field1EstherNo ratings yet
- Nur Syuhada Binti Safaruddin - Rba2403a - 2020819322Document6 pagesNur Syuhada Binti Safaruddin - Rba2403a - 2020819322syuhadasafar000No ratings yet
- Tutorial 1Document3 pagesTutorial 1AdiNo ratings yet
- Solving word problems involving rates of change and linear functionsDocument34 pagesSolving word problems involving rates of change and linear functionsChris JNo ratings yet
- 2326_EC2020_Main EQP v1_FinalDocument19 pages2326_EC2020_Main EQP v1_FinalAryan MittalNo ratings yet
- FINAL 022014 Answer KeyDocument8 pagesFINAL 022014 Answer KeyDavidNo ratings yet
- General: Quarter 1 - Week 1Document19 pagesGeneral: Quarter 1 - Week 1Jakim LopezNo ratings yet
- Practice ProblemDocument1 pagePractice ProblemElly John ReliquiasNo ratings yet
- Additional Problem Set Units I and IIDocument8 pagesAdditional Problem Set Units I and IISpider ManNo ratings yet
- NotesDocument17 pagesNotesSpider ManNo ratings yet
- Chapter 1 Test Bank: Strategic Management (Louisiana State University)Document49 pagesChapter 1 Test Bank: Strategic Management (Louisiana State University)Spider ManNo ratings yet
- Additional Problem Set Units I and IIDocument8 pagesAdditional Problem Set Units I and IISpider ManNo ratings yet
- Strategies For Competing in Industries and MarketsDocument31 pagesStrategies For Competing in Industries and MarketsSpider ManNo ratings yet
- Strategies For Competing in Industries and MarketsDocument31 pagesStrategies For Competing in Industries and MarketsSpider ManNo ratings yet
- Fictional Exercise: Evaluating Team Members For The Group PresenationsDocument1 pageFictional Exercise: Evaluating Team Members For The Group PresenationsSpider ManNo ratings yet
- Because There Is No Planet B: The Case of EcoalfDocument10 pagesBecause There Is No Planet B: The Case of EcoalfSpider ManNo ratings yet
- 1.) Please Describe With Your Own Words Porsche Success and Its Main Strategic Challenge Described in The CaseDocument3 pages1.) Please Describe With Your Own Words Porsche Success and Its Main Strategic Challenge Described in The CaseSpider ManNo ratings yet
- Chapter 1 Test Bank: Strategic Management (Louisiana State University)Document49 pagesChapter 1 Test Bank: Strategic Management (Louisiana State University)Spider ManNo ratings yet
- Lecture 4 Measures of Central TendencyDocument54 pagesLecture 4 Measures of Central Tendencymuhammad aifNo ratings yet
- Practical Research 1 SLHT Week 2Document9 pagesPractical Research 1 SLHT Week 2Ceyah KirstenNo ratings yet
- Week 6Document20 pagesWeek 6Crius DiomedesNo ratings yet
- Combined AnalysisDocument7 pagesCombined AnalysisKuthubudeen T MNo ratings yet
- Measures of Dispersion Handouts NewDocument4 pagesMeasures of Dispersion Handouts NewBAG2989No ratings yet
- Customer Type of Customer Items Net Sales Method of PaymentDocument19 pagesCustomer Type of Customer Items Net Sales Method of PaymentRaj Rajeshwari KayanNo ratings yet
- Sampling Design ProcessDocument31 pagesSampling Design ProcessShoaib ImtiazNo ratings yet
- Chapter 10 VolatilityDocument23 pagesChapter 10 VolatilityKiều Trần Nguyễn DiễmNo ratings yet
- Module 5 Forecasting PDF FreeDocument5 pagesModule 5 Forecasting PDF FreeHiếu Phan TrungNo ratings yet
- Quantitative Analysis for Management Course OutlineDocument36 pagesQuantitative Analysis for Management Course OutlineDeepika PadukoneNo ratings yet
- Application 9Document5 pagesApplication 9Dr. Ir. R. Didin Kusdian, MT.No ratings yet
- BCA 232 Testing of HypothesesDocument80 pagesBCA 232 Testing of HypothesesAzarudheen S StatisticsNo ratings yet
- SBST1303 Pengenalan StatistikDocument4 pagesSBST1303 Pengenalan StatistikzabedahibrahimNo ratings yet
- HW1 Solutions PDFDocument2 pagesHW1 Solutions PDFAnonymous iyBKnnlhNo ratings yet
- GUID - 5 en-USDocument29 pagesGUID - 5 en-USAndrés Ignacio Solano SeravalliNo ratings yet
- Kendall's Tau and Spearman's Rank Correlation Coefficient Assess StatisticalDocument7 pagesKendall's Tau and Spearman's Rank Correlation Coefficient Assess StatisticalAila Elocin PalmasNo ratings yet
- Chapter Twenty - Time SeriesDocument21 pagesChapter Twenty - Time SeriesSDB_EconometricsNo ratings yet
- PHCJ 615 IgnatowskibDocument8 pagesPHCJ 615 Ignatowskibapi-301035073No ratings yet
- UCT PSY2015F Statistics 2023Document34 pagesUCT PSY2015F Statistics 2023ZahraaNo ratings yet
- The Scientific Method: H P D IDocument9 pagesThe Scientific Method: H P D I-No ratings yet
- Lesson 5Document48 pagesLesson 5nelly barasa100% (1)
- Measures of Spread 2Document8 pagesMeasures of Spread 2Jattawee MarkNo ratings yet