You might also like
- Biotechnology & Bioprocessing: Advance Your Skill and Knowledge To The Next Level. and Keep It ThereDocument11 pagesBiotechnology & Bioprocessing: Advance Your Skill and Knowledge To The Next Level. and Keep It TherePattharachai LakornrachNo ratings yet
- Bioinformatics:: Focus On Primer Designing and Sequence Analysis (Blast)Document30 pagesBioinformatics:: Focus On Primer Designing and Sequence Analysis (Blast)Ravi KumarNo ratings yet
- BIOINFOMATICS - Information Sources and ApplicationsDocument80 pagesBIOINFOMATICS - Information Sources and Applicationstrupti_bioinfoNo ratings yet
- Bioinformatics: Nadiya Akmal Binti Baharum (PHD)Document54 pagesBioinformatics: Nadiya Akmal Binti Baharum (PHD)Nur RazinahNo ratings yet
- Bioinformatics Thesis TopicsDocument4 pagesBioinformatics Thesis Topicsafcngocah100% (2)
- Slides Smart Search Strategies Final Attached 20210126 707230Document37 pagesSlides Smart Search Strategies Final Attached 20210126 707230dr.tonichenNo ratings yet
- Supercomputing & Computational Biology: Presented byDocument26 pagesSupercomputing & Computational Biology: Presented bySatyabrata Sahu100% (1)
- Joint Beca-Ilri Hub, Slu and Unesco Advanced Genomics and BioinformaticsDocument27 pagesJoint Beca-Ilri Hub, Slu and Unesco Advanced Genomics and BioinformaticsBrandon ArceNo ratings yet
- Breaking Age-Long Barriers in Science Using AIDocument33 pagesBreaking Age-Long Barriers in Science Using AIAbassyacoubouNo ratings yet
- What Is Molecular Biology and Biotechnology?Document3 pagesWhat Is Molecular Biology and Biotechnology?Carl Angelo Lustre MarceloNo ratings yet
- Lect 2Document63 pagesLect 2api-3829740No ratings yet
- Introduction To BioinformaticsDocument15 pagesIntroduction To BioinformaticsJayankNo ratings yet
- เอกสารการบรรยาย - หัวข้อ 1 IntroductionDocument77 pagesเอกสารการบรรยาย - หัวข้อ 1 Introduction许伟思No ratings yet
- AAKHYATISINHA (2y 0m)Document2 pagesAAKHYATISINHA (2y 0m)rishabh singhNo ratings yet
- Bioinformatics PHD Thesis TopicsDocument5 pagesBioinformatics PHD Thesis Topicsl0dakyw1pon2100% (2)
- Week1 Slides 20221004Document62 pagesWeek1 Slides 20221004Ammar JagadhitaNo ratings yet
- Lecture1 BIMM143 LargeDocument73 pagesLecture1 BIMM143 Largepaseczkowo7No ratings yet
- FSLC Fiche GillesThomasDocument2 pagesFSLC Fiche GillesThomasMazhar KayaNo ratings yet
- Introduction To BioinformaticsDocument123 pagesIntroduction To BioinformaticsMaryem SafdarNo ratings yet
- Biophysical Characterization TechnologyDocument14 pagesBiophysical Characterization TechnologyAkindele O AdigunNo ratings yet
- DNA Fingerprinting - Bio-RadDocument102 pagesDNA Fingerprinting - Bio-Radebujak100% (3)
- Sequenciamento para BioinformatasDocument144 pagesSequenciamento para Bioinformatasilc67123No ratings yet
- Bio-Bio-1 - TopBright - Intro To Bioinfo MethodsDocument6 pagesBio-Bio-1 - TopBright - Intro To Bioinfo MethodsFokhruz ZamanNo ratings yet
- Machine Learning Based Prediction Methods in BioinformaticsDocument34 pagesMachine Learning Based Prediction Methods in Bioinformaticsdineshgupta11No ratings yet
- Bio in For Ma TicsDocument52 pagesBio in For Ma TicsSwapnesh SinghNo ratings yet
- Learning Objectives of Module: Fancy Statistical MethodsDocument25 pagesLearning Objectives of Module: Fancy Statistical Methodsmainak12No ratings yet
- Bio Molecular ComputingDocument16 pagesBio Molecular Computingsuresh teja chatrapatiNo ratings yet
- PV92 PCR Kit Manual PDFDocument104 pagesPV92 PCR Kit Manual PDFPaolo NaguitNo ratings yet
- BrochureDocument2 pagesBrochureAnonymous ffXdlcNo ratings yet
- CRN Webinarresearch 101may09Document27 pagesCRN Webinarresearch 101may09LunneteNo ratings yet
- Bioinformatics Thesis DownloadDocument8 pagesBioinformatics Thesis Downloadkatrinagreeneugene100% (2)
- Research Paper in BiotechnologyDocument7 pagesResearch Paper in Biotechnologyc9r0s69n100% (1)
- Data CollectionDocument39 pagesData CollectionAG GwanNo ratings yet
- Instant Download Ebook PDF Encyclopedia of Bioinformatics and Computational Biology ABC of Bioinformatics PDF ScribdDocument41 pagesInstant Download Ebook PDF Encyclopedia of Bioinformatics and Computational Biology ABC of Bioinformatics PDF Scribdhoward.linkovich475100% (43)
- Big Data in Evaluating Drug Efficacy and SafetyDocument28 pagesBig Data in Evaluating Drug Efficacy and SafetyVerena NatasiaNo ratings yet
- Just in Time-Inventory Control: Knowledge Access - JITDocument7 pagesJust in Time-Inventory Control: Knowledge Access - JITGac Rohit RadhakrishnanNo ratings yet
- Term Paper Genetic EngineeringDocument4 pagesTerm Paper Genetic Engineeringea68afje100% (1)
- Anne Carpenter Michael Schatz Matt Wood: Broad Institute, @drannecarpenterDocument26 pagesAnne Carpenter Michael Schatz Matt Wood: Broad Institute, @drannecarpenterAde Fachrur RozieNo ratings yet
- 4th Semester SyllabusDocument4 pages4th Semester SyllabusBHU tNo ratings yet
- Ameter Summary v0.3Document5 pagesAmeter Summary v0.3Reid BuckNo ratings yet
- Biostatistics PDFDocument150 pagesBiostatistics PDFsumNo ratings yet
- BBL 434 - Bioinformatics: D. SundarDocument22 pagesBBL 434 - Bioinformatics: D. SundarSparsh Negi100% (1)
- Module1 Understanding BioinformaticsDocument28 pagesModule1 Understanding Bioinformaticsnguyenquynhnhungt65No ratings yet
- Alex Wiedenhoeft - FLA 2016Document17 pagesAlex Wiedenhoeft - FLA 2016cedeweyNo ratings yet
- Dna Barcode ThesisDocument5 pagesDna Barcode Thesislisawilliamsnewhaven100% (2)
- Lecture : BiometricsDocument15 pagesLecture : BiometricsBasantNo ratings yet
- Big Data in HealthcareDocument35 pagesBig Data in HealthcareVerena NatasiaNo ratings yet
- R & D Indonesia Biotechnology Students Forum: Arif Rahman Sadjuri, S.SiDocument20 pagesR & D Indonesia Biotechnology Students Forum: Arif Rahman Sadjuri, S.Siscience_educatorNo ratings yet
- Lesson Plan Biotech PHDocument4 pagesLesson Plan Biotech PHMariflor RabeNo ratings yet
- Animal Classificatio. Mini Project ReportDocument11 pagesAnimal Classificatio. Mini Project ReportKrishNo ratings yet
- Biological Databases: October 2020Document15 pagesBiological Databases: October 2020Ahsan Arshad BSIT-F16-LC-008No ratings yet
- Molecular Markers Volume 1 enDocument375 pagesMolecular Markers Volume 1 enBlaxez YTNo ratings yet
- Performance Output (Pseudo-Research Proposal)Document4 pagesPerformance Output (Pseudo-Research Proposal)Vince Kleeser CabanigNo ratings yet
- Base Presentation 11 - 14 - 2023Document14 pagesBase Presentation 11 - 14 - 2023iulia alievNo ratings yet
- A.S. Shelten George: ObjectiveDocument4 pagesA.S. Shelten George: ObjectiveShelten GeorgeNo ratings yet
- Resume Writing Interviewing IndustryDocument23 pagesResume Writing Interviewing IndustryTeja RaoNo ratings yet
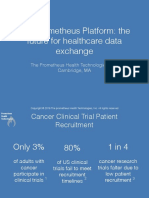
- The Prometheus Platform: The Future For Healthcare Data ExchangeDocument12 pagesThe Prometheus Platform: The Future For Healthcare Data ExchangeDavid MawsonNo ratings yet
- 2 BiotechnologyDocument4 pages2 BiotechnologyAmit DuttaNo ratings yet
- Analyzing the Large Number of Variables in Biomedical and Satellite ImageryFrom EverandAnalyzing the Large Number of Variables in Biomedical and Satellite ImageryNo ratings yet
- Bioinformatics: Algorithms, Coding, Data Science And BiostatisticsFrom EverandBioinformatics: Algorithms, Coding, Data Science And BiostatisticsNo ratings yet
- Englis 123Document39 pagesEnglis 123Cindy EysiaNo ratings yet
- Esp8285 Datasheet enDocument29 pagesEsp8285 Datasheet enJohn GreenNo ratings yet
- Introduction To Object Oriented Database: Unit-IDocument67 pagesIntroduction To Object Oriented Database: Unit-Ipreetham rNo ratings yet
- Complex Poly (Lactic Acid) - Based - 1Document20 pagesComplex Poly (Lactic Acid) - Based - 1Irina PaslaruNo ratings yet
- BF254 BF255Document3 pagesBF254 BF255rrr2013No ratings yet
- (IGC 2024) 2nd Circular - 0630Document43 pages(IGC 2024) 2nd Circular - 0630VictoriaNo ratings yet
- Practical CS ProcessingDocument483 pagesPractical CS ProcessinganAMUstudent100% (2)
- CE Laws L8 L15Document470 pagesCE Laws L8 L15Edwin BernatNo ratings yet
- Advanced Power Electronics Corp.: AP70T03GH/JDocument4 pagesAdvanced Power Electronics Corp.: AP70T03GH/JVolodiyaNo ratings yet
- SOP For Operation & Calibration of PH Meter - QualityGuidancesDocument9 pagesSOP For Operation & Calibration of PH Meter - QualityGuidancesfawaz khalilNo ratings yet
- Part 1. Question 1-7. Complete The Notes Below. Write NO MORE THAN THREE WORDS AND/OR A NUMBER For Each AnswerDocument13 pagesPart 1. Question 1-7. Complete The Notes Below. Write NO MORE THAN THREE WORDS AND/OR A NUMBER For Each Answerahmad amdaNo ratings yet
- What On Earth Is A MainframeDocument132 pagesWhat On Earth Is A MainframeCarlos DantasNo ratings yet
- Electric Valve Actuator Type Car: For 2 & 3-Way Valves Type G/L/M/S 2Fm-T & G/L/M/S 3Fm-T Page 1 of 4 0-4.11.08-HDocument4 pagesElectric Valve Actuator Type Car: For 2 & 3-Way Valves Type G/L/M/S 2Fm-T & G/L/M/S 3Fm-T Page 1 of 4 0-4.11.08-HMuhd Khir RazaniNo ratings yet
- CR-805 Retransfer PrinterDocument2 pagesCR-805 Retransfer PrinterBolivio FelizNo ratings yet
- Federal Government Employees Housing FoundationDocument2 pagesFederal Government Employees Housing FoundationMuhammad Shakil JanNo ratings yet
- AC7140 Rev CDocument73 pagesAC7140 Rev CRanga100% (1)
- Simple Past Lastdinezqm7Document16 pagesSimple Past Lastdinezqm7Esin ErgeneNo ratings yet
- Easy NoFap EbookDocument37 pagesEasy NoFap Ebookசரஸ்வதி சுவாமிநாதன்No ratings yet
- UV-Visible Systems - Operational Qualification - Col23 PDFDocument10 pagesUV-Visible Systems - Operational Qualification - Col23 PDFIsabelle PlourdeNo ratings yet
- 30xa 100t PDFDocument162 pages30xa 100t PDFleung ka kitNo ratings yet
- NUFLO Low Power Pre-Amplifier: SpecificationsDocument2 pagesNUFLO Low Power Pre-Amplifier: SpecificationsJorge ParraNo ratings yet
- 2005 Warehouse Benchmark in GR PTDocument59 pages2005 Warehouse Benchmark in GR PTMarco Antonio Oliveira NevesNo ratings yet
- Technical Assistance Plan School Year 2020-2021 Prioritized Needs of The Clients Objectives Strategies Activities MOV Time-Frame ResourcesDocument3 pagesTechnical Assistance Plan School Year 2020-2021 Prioritized Needs of The Clients Objectives Strategies Activities MOV Time-Frame ResourcesDon Angelo De Guzman95% (19)
- VRF Mv6R: Heat Recovery Outdoor UnitsDocument10 pagesVRF Mv6R: Heat Recovery Outdoor UnitsTony NguyenNo ratings yet
- Unseen Passage 2Document6 pagesUnseen Passage 2Vinay OjhaNo ratings yet
- Teccrs 3800Document431 pagesTeccrs 3800Genus SumNo ratings yet
- DocumentationDocument44 pagesDocumentation19-512 Ratnala AshwiniNo ratings yet
- Syllabus - Building Rehabilitation Anfd Forensic en - 220825 - 181244Document3 pagesSyllabus - Building Rehabilitation Anfd Forensic en - 220825 - 181244M O H A N A V E LNo ratings yet
- 7 ApportionmentDocument46 pages7 Apportionmentsass sofNo ratings yet
- PLX Model OfficialDocument105 pagesPLX Model OfficialBảo Ngọc LêNo ratings yet