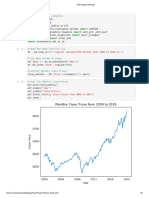
You might also like
- Simple Linear RegressionDocument4 pagesSimple Linear RegressionAfandi NatNo ratings yet
- Paper 2.Document5 pagesPaper 2.Avi TiwariNo ratings yet
- Assignment 4Document5 pagesAssignment 4shellieratheeNo ratings yet
- Salary Prediction LinearRegressionDocument7 pagesSalary Prediction LinearRegressionYagnesh Vyas100% (1)
- 01 Simple Linear RegressionDocument6 pages01 Simple Linear RegressionGabriel GheorgheNo ratings yet
- Cluster Australia: 1 StrategyDocument5 pagesCluster Australia: 1 StrategySteven TruongNo ratings yet
- Logistic RegressionDocument10 pagesLogistic RegressionChichi Jnr100% (1)
- Data Preprocessing Python Tome IIIDocument12 pagesData Preprocessing Python Tome IIIElisée TEGUENo ratings yet
- TSA Project Python CodeDocument6 pagesTSA Project Python CodemarketingwithparamjeetNo ratings yet
- Rolling Window Functions With PandasDocument37 pagesRolling Window Functions With PandasVadim YermolenkoNo ratings yet
- Day42 SVM RegressionDocument3 pagesDay42 SVM RegressionIgor FernandesNo ratings yet
- Machine Learning With SQLDocument12 pagesMachine Learning With SQLprince krish100% (1)
- Machine Learning LAB: Practical-1Document24 pagesMachine Learning LAB: Practical-1Tsering Jhakree100% (1)
- Experiment2 2158Document3 pagesExperiment2 2158sohit sharmaNo ratings yet
- G Pandey PracticalDocument33 pagesG Pandey PracticalSadananda Moirãngthëm Gidi LêïjreNo ratings yet
- Linear and Logistic RegressionDocument6 pagesLinear and Logistic RegressionMahevish FatimaNo ratings yet
- Praktikum 1 Jupiter Machine LearningDocument1 pagePraktikum 1 Jupiter Machine LearningAditya NugrohoNo ratings yet
- SFB EdaDocument13 pagesSFB EdaPraneeth AluruNo ratings yet
- Big Data MergedDocument7 pagesBig Data MergedIngame IdNo ratings yet
- 03 A Polynomial Linear RegressionDocument6 pages03 A Polynomial Linear RegressionGabriel GheorgheNo ratings yet
- Backward && Forward Feature Selection PART-2Document6 pagesBackward && Forward Feature Selection PART-2Gabriel GheorgheNo ratings yet
- Exp 1Document6 pagesExp 1Mr. SNo ratings yet
- C1 W2 Lab05 Sklearn GD SolnDocument3 pagesC1 W2 Lab05 Sklearn GD SolnSrinidhi PNo ratings yet
- Coca Cola StartDocument1 pageCoca Cola StartxtremewhizNo ratings yet
- MLfullDocument29 pagesMLfullJanvi PatelNo ratings yet
- Stats Practical WJCDocument23 pagesStats Practical WJCBhuvanesh SriniNo ratings yet
- Peer Review Assignment 4: InstructionsDocument17 pagesPeer Review Assignment 4: Instructionshamza omar100% (1)
- Mslab All 2982Document31 pagesMslab All 2982Anubhav KhuranaNo ratings yet
- PML Ex3 FinalDocument20 pagesPML Ex3 FinalJasmitha BNo ratings yet
- 2 Naive Bayee Algorithm - Jupyter NotebookDocument2 pages2 Naive Bayee Algorithm - Jupyter Notebookvenkatesh mNo ratings yet
- 20bce0872 VL2022230503441 Ast01 230122 204351Document10 pages20bce0872 VL2022230503441 Ast01 230122 204351Vishesh BhargavaNo ratings yet
- DS ManualDocument30 pagesDS ManualZoom CommunicationNo ratings yet
- Linear Regression Python Sklearn Numpy P PDFDocument2 pagesLinear Regression Python Sklearn Numpy P PDFPranabesh ChatterjeeNo ratings yet
- Principal Component Analysis Notes : InfoDocument22 pagesPrincipal Component Analysis Notes : InfoVALMICK GUHANo ratings yet
- Tugas Akhir Big DataDocument10 pagesTugas Akhir Big DataSaskya LidayaniNo ratings yet
- Appendix PDFDocument5 pagesAppendix PDFRamaNo ratings yet
- Mslab All 2376Document32 pagesMslab All 2376Anubhav KhuranaNo ratings yet
- Gregorio RDAG DCEE23 BSCpE2A-Practical-ExamDocument16 pagesGregorio RDAG DCEE23 BSCpE2A-Practical-ExamJoshua CañezalNo ratings yet
- C: Users Dell Downloads Salary - Data - CSVDocument2 pagesC: Users Dell Downloads Salary - Data - CSVredhaNo ratings yet
- ML PracticalsDocument11 pagesML Practicals05. Yash DaroleNo ratings yet
- Supervised Learning For Data Science...Document14 pagesSupervised Learning For Data Science...shivaybhargava33No ratings yet
- SVM K NN MLP With Sklearn Jupyter NoteBoDocument22 pagesSVM K NN MLP With Sklearn Jupyter NoteBoAhm TharwatNo ratings yet
- PythDocument38 pagesPythMinal JoshiNo ratings yet
- Handwritten Character Recognition With Neural NetworkDocument12 pagesHandwritten Character Recognition With Neural Networkshreyash sononeNo ratings yet
- FinanceDocument1 pageFinanceahmadkhalilNo ratings yet
- School of Engineering: Lab Manual On Machine Learning LabDocument23 pagesSchool of Engineering: Lab Manual On Machine Learning LabRavi KumawatNo ratings yet
- FrescoDocument17 pagesFrescovinay100% (2)
- Aychew ChernetDocument8 pagesAychew ChernetaychewchernetNo ratings yet
- 06 SeabornDocument13 pages06 SeabornAnonymous 001No ratings yet
- Financial Analytics With PythonDocument40 pagesFinancial Analytics With PythonHarshit Singh100% (1)
- I.P Practical Solution - PlottingDocument9 pagesI.P Practical Solution - Plottingrizanmuhammed055No ratings yet
- Practical Record 2 PYTHON AND SQL PROGRAMS - 2023Document76 pagesPractical Record 2 PYTHON AND SQL PROGRAMS - 2023isnprincipal2020No ratings yet
- Time-Series Forecasting Using Conv1D-LSTM - Multiple Timesteps Into FutureDocument6 pagesTime-Series Forecasting Using Conv1D-LSTM - Multiple Timesteps Into Future8c354be21dNo ratings yet
- Variosalgoritmos - Jupyter NotebookDocument9 pagesVariosalgoritmos - Jupyter NotebookPAULO CESAR CALDERON BERMUDO100% (1)
- AIDS - DM Using Python - Lab ProgramsDocument19 pagesAIDS - DM Using Python - Lab ProgramsyelubandirenukavidyadhariNo ratings yet
- Machine Learning Hands-OnDocument18 pagesMachine Learning Hands-OnVivek JD100% (1)
- Experiment No.:1: ProgramDocument7 pagesExperiment No.:1: ProgramDhiraj ShahNo ratings yet
- Predictive+Modelling+-+Linear+Discriminant+Analysis+-+Mentor+version - Ipynb - ColaboratoryDocument13 pagesPredictive+Modelling+-+Linear+Discriminant+Analysis+-+Mentor+version - Ipynb - ColaboratorySHEKHAR SWAMINo ratings yet
- Efficient Python Tricks and Tools For Data Scientists - by Khuyen TranDocument20 pagesEfficient Python Tricks and Tools For Data Scientists - by Khuyen TranKhagenNo ratings yet
- Strategy-Making in Turbulent TimesDocument20 pagesStrategy-Making in Turbulent TimesnishantNo ratings yet
- 1962 Agribusniess Trends LEK Executive InsightsDocument6 pages1962 Agribusniess Trends LEK Executive InsightsnishantNo ratings yet
- Orient Electric IC Jun22Document44 pagesOrient Electric IC Jun22nishantNo ratings yet
- 6 - SwapDocument29 pages6 - SwapnishantNo ratings yet
- RIL Chairman Statement-45th AGM 2022Document17 pagesRIL Chairman Statement-45th AGM 2022nishantNo ratings yet
- Deft TheftDocument6 pagesDeft TheftnishantNo ratings yet
- 5 - GreeksDocument100 pages5 - GreeksnishantNo ratings yet
- Guidelines For Resume BuildingDocument4 pagesGuidelines For Resume BuildingnishantNo ratings yet
- Assignment 2 19030Document2 pagesAssignment 2 19030nishantNo ratings yet
- DeBeers Case Answers (Case 2)Document6 pagesDeBeers Case Answers (Case 2)nishantNo ratings yet
- Task 4: Exploratory Data Analysis - Terrorism Task 4: Exploratory Data Analysis - Terrorism Presented By: Nishant Kumar Presented By: Nishant KumarDocument11 pagesTask 4: Exploratory Data Analysis - Terrorism Task 4: Exploratory Data Analysis - Terrorism Presented By: Nishant Kumar Presented By: Nishant KumarnishantNo ratings yet
- Goal - Perform Eda Over A Dataset 'Samplesuperstore' Goal - Perform Eda Over A Dataset 'Samplesuperstore'Document9 pagesGoal - Perform Eda Over A Dataset 'Samplesuperstore' Goal - Perform Eda Over A Dataset 'Samplesuperstore'nishantNo ratings yet
- Financials Projections and AssumptionsDocument4 pagesFinancials Projections and AssumptionsnishantNo ratings yet
- MTE Project: Task 1Document6 pagesMTE Project: Task 1nishantNo ratings yet
- DCF Model TemplateDocument20 pagesDCF Model TemplatenishantNo ratings yet
- Ratio Analysis TemplateDocument20 pagesRatio Analysis TemplatenishantNo ratings yet
- Financial Model: Circus Matchboxes IncDocument13 pagesFinancial Model: Circus Matchboxes IncnishantNo ratings yet
- MTE Project-2: Task 1Document3 pagesMTE Project-2: Task 1nishantNo ratings yet
- Book 1Document3 pagesBook 1nishantNo ratings yet
- Analysis DataDocument221 pagesAnalysis DatanishantNo ratings yet
- SMS Unhappy: Marketing ManagementDocument37 pagesSMS Unhappy: Marketing ManagementnishantNo ratings yet
- Bank of New Generation Relationship That Grows With YouDocument1 pageBank of New Generation Relationship That Grows With YounishantNo ratings yet
- UNITED SPIRITS LTD-SIrDocument39 pagesUNITED SPIRITS LTD-SIrnishantNo ratings yet
- Chapter 1Document30 pagesChapter 1nishantNo ratings yet
- Capital BudgetingDocument28 pagesCapital BudgetingnishantNo ratings yet
- Global 2019 Third PlaceDocument15 pagesGlobal 2019 Third PlacenishantNo ratings yet
- Multiple Linear RegressionDocument13 pagesMultiple Linear RegressionHemanshu DasNo ratings yet
- 6.5 Checkpoint Reliability and MaintenanceDocument5 pages6.5 Checkpoint Reliability and MaintenanceherrajohnNo ratings yet
- Is 15393 2 2003 PDFDocument51 pagesIs 15393 2 2003 PDFLuis ConstanteNo ratings yet
- Lecture 3 Role of Statistics in ResearchDocument34 pagesLecture 3 Role of Statistics in ResearchFazlee KanNo ratings yet
- Hw3 Mimo CapDocument18 pagesHw3 Mimo CapShirishinahal SumanNo ratings yet
- BC06-1 Bmas Topic-5 Linear Correlation and RegresssionDocument13 pagesBC06-1 Bmas Topic-5 Linear Correlation and Regresssionafatima paintingNo ratings yet
- A Study of Weibull Mixture ROC Curve With Constant Shape Parameter PDFDocument10 pagesA Study of Weibull Mixture ROC Curve With Constant Shape Parameter PDFAzhar UddinNo ratings yet
- 9A04303 Probability Theory & Stochastic ProcessesDocument4 pages9A04303 Probability Theory & Stochastic ProcessessivabharathamurthyNo ratings yet
- StatisticsDocument11 pagesStatisticsYeoj Aquit ParreñoNo ratings yet
- Assignment 4 Joint Probability Distribution.176656.1519666683.4243Document4 pagesAssignment 4 Joint Probability Distribution.176656.1519666683.4243Beam JF TeddyNo ratings yet
- Quality AssociatesDocument6 pagesQuality AssociatesAkash AK100% (1)
- Hypothesis Testing Problem SetDocument2 pagesHypothesis Testing Problem SetKhenz MistalNo ratings yet
- Stats 845 Lecture 14nDocument84 pagesStats 845 Lecture 14nAashima Sharma BhasinNo ratings yet
- 283 - MCSE-004 D18 - Compressed PDFDocument5 pages283 - MCSE-004 D18 - Compressed PDFPankaj SharmaNo ratings yet
- Chapter 3Document87 pagesChapter 3goegiorgianaNo ratings yet
- Eeb2033/Edb2053 May 2022: Probability & Random Process: Credit Hours: 3 UnitDocument3 pagesEeb2033/Edb2053 May 2022: Probability & Random Process: Credit Hours: 3 UnitYo Liang SikNo ratings yet
- Statistical Methods For Quality & ReliabilityDocument2 pagesStatistical Methods For Quality & ReliabilityManish R PillaiNo ratings yet
- Quiz #6Document3 pagesQuiz #6Zhen ManlangitNo ratings yet
- Edexcel s1 Mixed QuestionDocument78 pagesEdexcel s1 Mixed QuestionStylianos_C100% (1)
- Chapter 5: The Beast of Bias: Smart Alex's SolutionsDocument15 pagesChapter 5: The Beast of Bias: Smart Alex's SolutionsMinzaNo ratings yet
- MT427 Notebook 4 Fall 2013/2014: Prepared by Professor Jenny BaglivoDocument27 pagesMT427 Notebook 4 Fall 2013/2014: Prepared by Professor Jenny BaglivoOmar Olvera GNo ratings yet
- s10 Sampling Distributions PDFDocument39 pagess10 Sampling Distributions PDFCarlos LeonNo ratings yet
- Stats Heavy QuestionsDocument48 pagesStats Heavy QuestionsblueNo ratings yet
- Measures of Central TendencyDocument7 pagesMeasures of Central TendencyAnjo Pasiolco CanicosaNo ratings yet
- 2nd 3rd Assignment 17MAT41Document2 pages2nd 3rd Assignment 17MAT41Ritwik guptaNo ratings yet
- Cluster Sampling: ProcedureDocument12 pagesCluster Sampling: ProcedureAahil RazaNo ratings yet
- Option Pricing in A Dynamic Variance-Gamma ModelDocument25 pagesOption Pricing in A Dynamic Variance-Gamma ModelNoureddineLahouelNo ratings yet
- This Study Resource Was: L19 Quiz: HomeworkDocument3 pagesThis Study Resource Was: L19 Quiz: HomeworkPenny Tratia0% (1)
- 17.6: Backwards Martingales: Basic TheoryDocument3 pages17.6: Backwards Martingales: Basic TheoryMohammedseid AhmedinNo ratings yet
- Statistical Inference: Sampling DistributionsDocument36 pagesStatistical Inference: Sampling DistributionsgulafshanNo ratings yet