You might also like
- Computers and Operations Research: M.K. Marichelvam, M. Geetha, Ömür TosunDocument9 pagesComputers and Operations Research: M.K. Marichelvam, M. Geetha, Ömür Tosunshaim mahamudNo ratings yet
- Review of Related LiteratureDocument3 pagesReview of Related LiteratureSpencer DariusNo ratings yet
- Accepted Manuscript: MeasurementDocument38 pagesAccepted Manuscript: MeasurementRajyalakshmiNo ratings yet
- A Hybrid Artificial Bee Colony Algorithm For Flexible Job Shop Scheduling With Worker FlexibilityDocument16 pagesA Hybrid Artificial Bee Colony Algorithm For Flexible Job Shop Scheduling With Worker FlexibilityitzgayaNo ratings yet
- Extracting Priority Rules For Dynamic Multi-Objective Flexible Job Shop Scheduling Problems Using Gene Expression ProgrammingDocument18 pagesExtracting Priority Rules For Dynamic Multi-Objective Flexible Job Shop Scheduling Problems Using Gene Expression ProgrammingThenarasumohanveluNo ratings yet
- Li 2019Document11 pagesLi 2019Chakib BenmhamedNo ratings yet
- A Fuzzy Linguistic Approach of Preventive Maintenance Scheduling Cost OptimisationDocument13 pagesA Fuzzy Linguistic Approach of Preventive Maintenance Scheduling Cost Optimisationkarthikeyan PNo ratings yet
- A Constraint Programming-Based Genetic Algorithm For Capacity Output OptimizationDocument28 pagesA Constraint Programming-Based Genetic Algorithm For Capacity Output OptimizationRikudo AkyoshiNo ratings yet
- Generation of Optimum Sequence of Operations Using Ant Colony Algorithm by Sudeep SinghDocument19 pagesGeneration of Optimum Sequence of Operations Using Ant Colony Algorithm by Sudeep SinghSudeep Kumar SinghNo ratings yet
- Generation of Optimum Sequence of Operat PDFDocument19 pagesGeneration of Optimum Sequence of Operat PDFSudeep Kumar SinghNo ratings yet
- Integrated Process Planning and Scheduling in Smart Manufacturing Using Genetic Based AlgorithmDocument6 pagesIntegrated Process Planning and Scheduling in Smart Manufacturing Using Genetic Based Algorithmrizqy lovinaNo ratings yet
- Designing A Manufacturing Cell System by Assigning WorkforceDocument14 pagesDesigning A Manufacturing Cell System by Assigning WorkforceClaudiu IndreNo ratings yet
- 1 s2.0 S0360835211003196 Main PDFDocument10 pages1 s2.0 S0360835211003196 Main PDFitzgayaNo ratings yet
- Ijiec 2012 55Document20 pagesIjiec 2012 55letthereberock448No ratings yet
- An Effective PSO and AIS-Based Hybrid Intelligent Algorithm For Job-Shop SchedulingDocument11 pagesAn Effective PSO and AIS-Based Hybrid Intelligent Algorithm For Job-Shop SchedulingCSENITHNo ratings yet
- Computers & Industrial Engineering: Amir Musa Abazari, Maghsud Solimanpur, Hossein SattariDocument10 pagesComputers & Industrial Engineering: Amir Musa Abazari, Maghsud Solimanpur, Hossein SattariAmrik SinghNo ratings yet
- Applied Sciences: Hybrid Flow Shop Scheduling Problems Using Improved Fireworks Algorithm For PermutationDocument16 pagesApplied Sciences: Hybrid Flow Shop Scheduling Problems Using Improved Fireworks Algorithm For PermutationOlivia brianneNo ratings yet
- Research Paper On Genetic Based Workflow Scheduling Algorithm in Cloud ComputingDocument6 pagesResearch Paper On Genetic Based Workflow Scheduling Algorithm in Cloud ComputingSebastian GuerraNo ratings yet
- An Approach of Designing Robust Plant Layout Using Genetic AlgorithmDocument10 pagesAn Approach of Designing Robust Plant Layout Using Genetic AlgorithmLeonardo LoretiNo ratings yet
- A Novel Hybrid Genetic Algorithm To Solve The Make-To-Order Sequence-Dependent Flow-Shop Scheduling ProblemDocument9 pagesA Novel Hybrid Genetic Algorithm To Solve The Make-To-Order Sequence-Dependent Flow-Shop Scheduling ProblemVerdianto PradanaNo ratings yet
- Einstein Weighted Geometric Operator For Pythagorean Fuzzy Hypersoft With Its Application in Material SelectionDocument27 pagesEinstein Weighted Geometric Operator For Pythagorean Fuzzy Hypersoft With Its Application in Material SelectionScience DirectNo ratings yet
- Is Parameters Quantification in Genetic Algorithm Important, How To Do It?Document12 pagesIs Parameters Quantification in Genetic Algorithm Important, How To Do It?IAES IJAINo ratings yet
- Expert Systems With ApplicationsDocument15 pagesExpert Systems With ApplicationsEva Selene Hernández GressNo ratings yet
- Bo 24437446Document10 pagesBo 24437446Kelvin SudaniNo ratings yet
- Cb-Pattern Trees: Identifying Distributed Nodes Where Materialization Is AvailableDocument12 pagesCb-Pattern Trees: Identifying Distributed Nodes Where Materialization Is AvailableLewis TorresNo ratings yet
- Ding 2015Document10 pagesDing 2015bilalkhurshidNo ratings yet
- Expert Systems With Applications: Massimo Bertolini, Davide Mezzogori, Francesco ZammoriDocument19 pagesExpert Systems With Applications: Massimo Bertolini, Davide Mezzogori, Francesco Zammorispike9444No ratings yet
- Empirical Study To Explore The Impact ofDocument20 pagesEmpirical Study To Explore The Impact ofJorge Alejandro Patron ChicanaNo ratings yet
- 10 23919eleco47770 2019 8990395Document15 pages10 23919eleco47770 2019 8990395Phạm Trọng ĐứcNo ratings yet
- Castellano. 2021. Metaheuristics For The Flowshop Scheduling Problem With Maintenance Activites IntegratedDocument26 pagesCastellano. 2021. Metaheuristics For The Flowshop Scheduling Problem With Maintenance Activites Integratedmilyhya fgNo ratings yet
- CPIE-2016 Paper 49Document10 pagesCPIE-2016 Paper 49Atul ChauhanNo ratings yet
- Optimizing Non Unit Repetitive Project Resource and Scheduling by Evolutionary AlgorithmsDocument27 pagesOptimizing Non Unit Repetitive Project Resource and Scheduling by Evolutionary AlgorithmsDANIEL MULYONONo ratings yet
- 10 1108 - BPMJ 07 2013 0098Document28 pages10 1108 - BPMJ 07 2013 00982381232No ratings yet
- FMS Scheduling With Knowledge Based Genetic Algorithm ApproachDocument11 pagesFMS Scheduling With Knowledge Based Genetic Algorithm ApproachKhải TrầnNo ratings yet
- Retrieve Integrated Preventive Maintenance and FowDocument37 pagesRetrieve Integrated Preventive Maintenance and FowJavier Enrique Linares DominguezNo ratings yet
- 2019 TASEA Two-Layer Adaptive Surrogate-Assisted Evolutionary Algorithm For High-Dimensional Computationally Expensive ProblemsDocument33 pages2019 TASEA Two-Layer Adaptive Surrogate-Assisted Evolutionary Algorithm For High-Dimensional Computationally Expensive ProblemsZhangming WuNo ratings yet
- Computers & Industrial Engineering 145 (2020) 106505Document10 pagesComputers & Industrial Engineering 145 (2020) 106505Olivia brianneNo ratings yet
- Employing Fuzzy ANP For Green Supplier Selection and Order Allocations: A Case StudyDocument11 pagesEmploying Fuzzy ANP For Green Supplier Selection and Order Allocations: A Case StudyTI Journals PublishingNo ratings yet
- A Performance-Based Labor Allocation Model for Cellular ManufacturingDocument6 pagesA Performance-Based Labor Allocation Model for Cellular ManufacturingAnupa De SilvaNo ratings yet
- RUN Beyond The Metaphor-An Efficient Optimization Algorithm Based On Runge Kutta Method-ESWA 2021Document50 pagesRUN Beyond The Metaphor-An Efficient Optimization Algorithm Based On Runge Kutta Method-ESWA 2021alihNo ratings yet
- Ijiec 2019 19Document22 pagesIjiec 2019 19b4rtm4nNo ratings yet
- Fu 2019Document15 pagesFu 2019Chakib BenmhamedNo ratings yet
- Review CriticsDocument7 pagesReview CriticsAyele NugusieNo ratings yet
- Computers & Industrial Engineering: SciencedirectDocument16 pagesComputers & Industrial Engineering: SciencedirectitzgayaNo ratings yet
- TimetableDocument11 pagesTimetableTusi tusi TusiNo ratings yet
- Optimization of Process Synthesis and Design Problems - A Modified Differential Evolution ApproachDocument15 pagesOptimization of Process Synthesis and Design Problems - A Modified Differential Evolution ApproachSangHao NgNo ratings yet
- Computers & Industrial Engineering: Muhammad Imran, Changwook Kang, Young Hae Lee, Mirza Jahanzaib, Haris AzizDocument13 pagesComputers & Industrial Engineering: Muhammad Imran, Changwook Kang, Young Hae Lee, Mirza Jahanzaib, Haris AzizAnkitKhareNo ratings yet
- Production Line Performance by Using Queuing Model: Muhammad Marsudi, Hani ShafeekDocument6 pagesProduction Line Performance by Using Queuing Model: Muhammad Marsudi, Hani ShafeeklixoshadyNo ratings yet
- Application of Fuzzy Inference Systems and Genetic Algorithms in Integrated Process Planning and SchedulingDocument17 pagesApplication of Fuzzy Inference Systems and Genetic Algorithms in Integrated Process Planning and SchedulingIndah FitrianiNo ratings yet
- Literature ReviewDocument7 pagesLiterature ReviewChikooNo ratings yet
- Multi-Objective Facility Layout Problems Using BBO, NSBBO and NSGA-II MetaheuristicDocument24 pagesMulti-Objective Facility Layout Problems Using BBO, NSBBO and NSGA-II MetaheuristicswarajNo ratings yet
- Chaudry. 2015. Integrated Process Planning and Scheduling Using Genetic AlgorithmsDocument9 pagesChaudry. 2015. Integrated Process Planning and Scheduling Using Genetic Algorithmsmilyhya fgNo ratings yet
- A Mathematical Model and Tabu Search Algorithm For Multi-Manned AlbpDocument20 pagesA Mathematical Model and Tabu Search Algorithm For Multi-Manned AlbpCynthia Sasmita DewiNo ratings yet
- Mean Gbest and Gravitational Search AlgorithmDocument22 pagesMean Gbest and Gravitational Search AlgorithmmaniNo ratings yet
- Algorithms: Simulation On Cooperative Changeover of Production Team Using Hybrid Modeling MethodDocument16 pagesAlgorithms: Simulation On Cooperative Changeover of Production Team Using Hybrid Modeling MethodSantosh SharmaNo ratings yet
- Ga ResultsDocument13 pagesGa ResultsWan IzhamNo ratings yet
- Comparison of Meta-Heuristic Algorithms For Solving Machining Optimization ProblemsDocument16 pagesComparison of Meta-Heuristic Algorithms For Solving Machining Optimization Problemsravi474No ratings yet
- Batch 2020 - Class 1 - Group 13 - Paper Writting Assignment 1Document14 pagesBatch 2020 - Class 1 - Group 13 - Paper Writting Assignment 1Bintang KusumaNo ratings yet
- Utilization of Timetable Management System to a Medium Scaled UniversityDocument10 pagesUtilization of Timetable Management System to a Medium Scaled UniversityANKOMAH EVANSNo ratings yet
- 2021-03 Approach To Value ChainsDocument15 pages2021-03 Approach To Value ChainsFasilNo ratings yet
- 1 Banikoi Et AlDocument15 pages1 Banikoi Et AlFasilNo ratings yet
- A6-Note Ug en 201909Document21 pagesA6-Note Ug en 201909FasilNo ratings yet
- ThesisDocument389 pagesThesisFasilNo ratings yet
- Lenovo A6 Note Dual Sim Cerny 38383 Cesky NavodDocument68 pagesLenovo A6 Note Dual Sim Cerny 38383 Cesky NavodFasilNo ratings yet
- Lenovo A6 Note Dual Sim Cerny 38383 Cesky NavodDocument68 pagesLenovo A6 Note Dual Sim Cerny 38383 Cesky NavodFasilNo ratings yet
- A6-Note Ug en 201909Document21 pagesA6-Note Ug en 201909FasilNo ratings yet
- J of Business Logistics - 2022 - Pan - When The Going Gets Tough Do The Tough Go ShoppingDocument19 pagesJ of Business Logistics - 2022 - Pan - When The Going Gets Tough Do The Tough Go ShoppingFasilNo ratings yet
- Step 2: Mapping and AnalysisDocument10 pagesStep 2: Mapping and AnalysisFasilNo ratings yet
- Dokumen - Tips Origin of AmharicDocument12 pagesDokumen - Tips Origin of AmharicFasilNo ratings yet
- Participatory Planning Step GuideDocument11 pagesParticipatory Planning Step GuideFasilNo ratings yet
- OSN 9800 U64, U32, U16, UPS Installation GuideDocument157 pagesOSN 9800 U64, U32, U16, UPS Installation GuidedonekeoNo ratings yet
- Performance Appraisal at UFLEX Ltd.Document29 pagesPerformance Appraisal at UFLEX Ltd.Mohit MehraNo ratings yet
- Mobile Banking Prospects Problems BangladeshDocument20 pagesMobile Banking Prospects Problems BangladeshabrarNo ratings yet
- Ch3 Profiles, Password Policies, Privileges, and RolesDocument79 pagesCh3 Profiles, Password Policies, Privileges, and Rolesahlam alzhraniNo ratings yet
- United States Government and PoliticsDocument21 pagesUnited States Government and PoliticsTony BuiNo ratings yet
- Quy Trình AgencyDocument4 pagesQuy Trình Agencyson nguyenNo ratings yet
- Haslinda Mohd Anuar Senior Lecturer School of Law ColgisDocument24 pagesHaslinda Mohd Anuar Senior Lecturer School of Law ColgisSHAHEERANo ratings yet
- SheetMetal Bend Allowance GuideDocument3 pagesSheetMetal Bend Allowance GuidesunilbholNo ratings yet
- Zodax Collection 2011Document129 pagesZodax Collection 2011njlaporteNo ratings yet
- Whitmer Unveils Proposed 2022 Michigan BudgetDocument187 pagesWhitmer Unveils Proposed 2022 Michigan BudgetWXYZ-TV Channel 7 DetroitNo ratings yet
- Kick Control: BY: Naga Ramesh D. Assistant Professor Petroleum Engineering Dept. KlefDocument13 pagesKick Control: BY: Naga Ramesh D. Assistant Professor Petroleum Engineering Dept. Klefavula43No ratings yet
- Pilz PNOZ 3 DatasheetDocument5 pagesPilz PNOZ 3 DatasheetIsrael De LeonNo ratings yet
- 9 Principles of Income Tax LawsDocument82 pages9 Principles of Income Tax LawsVyankatesh GotalkarNo ratings yet
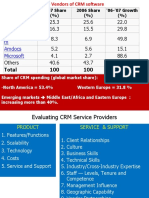
- CRM Vendors, Vendor SelectionDocument7 pagesCRM Vendors, Vendor SelectionsanamkmNo ratings yet
- Melissa Wanstall March 2016Document2 pagesMelissa Wanstall March 2016api-215567355No ratings yet
- Ivent201 - Manual de Usuario (220-290)Document71 pagesIvent201 - Manual de Usuario (220-290)Wilber AleluyaNo ratings yet
- Combinational CircuitsDocument18 pagesCombinational CircuitsSalil TimalsinaNo ratings yet
- Manual DishwashingDocument2 pagesManual Dishwashingkean redNo ratings yet
- Petron Corporate PresentationDocument46 pagesPetron Corporate Presentationsivuonline0% (1)
- Sub Engineer Test Model PaperDocument8 pagesSub Engineer Test Model PaperZeeshan AhmadNo ratings yet
- Hello World in FortranDocument43 pagesHello World in Fortranhussein alsaedeNo ratings yet
- Sk200-8 Sk210lc-8 Super AsiaDocument16 pagesSk200-8 Sk210lc-8 Super AsiaAnwar Rashid86% (7)
- Databases 2 Exercise Sheet 4Document2 pagesDatabases 2 Exercise Sheet 4Shivam ShuklaNo ratings yet
- Malware Analysis Project ClusteringDocument11 pagesMalware Analysis Project ClusteringGilian kipkosgeiNo ratings yet
- Beam Loader Tributary ExcelDocument2 pagesBeam Loader Tributary ExcelHari Amudhan IlanchezhianNo ratings yet
- Job - Details - Grant Acquisition Management (GAM) Manager - 5219Document4 pagesJob - Details - Grant Acquisition Management (GAM) Manager - 5219Salman DigaleNo ratings yet
- VLSI Design Course PlanDocument2 pagesVLSI Design Course PlanJunaid RajputNo ratings yet
- How To Combine Cells Into A Cell With Comma, Space and Vice VersaDocument8 pagesHow To Combine Cells Into A Cell With Comma, Space and Vice VersaClifford Marco ArimadoNo ratings yet
- MD Anderson Medical Oncology 4th Edition 2022Document1,694 pagesMD Anderson Medical Oncology 4th Edition 2022Iskandar414100% (6)
- 20NCT2 1784 SampleDocument12 pages20NCT2 1784 Samplekimjohn dejesusNo ratings yet