You might also like
- Icelandic Spells and SigilsDocument16 pagesIcelandic Spells and SigilsSimonida Mona Vulić83% (6)
- Request For Proposal Construction & Phase 1 OperationDocument116 pagesRequest For Proposal Construction & Phase 1 Operationsobhi100% (2)
- Rose Sparkling WineDocument32 pagesRose Sparkling WineKATHIRVEL S100% (1)
- General Biology 2-Week 2-Module 4-Evidence of EvolutionDocument16 pagesGeneral Biology 2-Week 2-Module 4-Evidence of EvolutionFEMALE Dawal LaizaNo ratings yet
- Time Series Forecasting Business Report: Name: S.Krishna Veni Date: 20/02/2022Document31 pagesTime Series Forecasting Business Report: Name: S.Krishna Veni Date: 20/02/2022Krishna Veni100% (1)
- MLR-handson - Jupyter NotebookDocument5 pagesMLR-handson - Jupyter NotebookAnzal MalikNo ratings yet
- MATHEMATICAL ECONOMICSDocument54 pagesMATHEMATICAL ECONOMICSCities Normah0% (1)
- Chronological OrderDocument5 pagesChronological OrderDharWin d'Wing-Wing d'AriestBoyzNo ratings yet
- AWS Cloud Practicioner Exam Examples 0Document110 pagesAWS Cloud Practicioner Exam Examples 0AnataTumonglo100% (3)
- Project - Time Series Forecasting - Rajendra M BhatDocument33 pagesProject - Time Series Forecasting - Rajendra M BhatRajendra Bhat80% (10)
- QP P1 APR 2023Document16 pagesQP P1 APR 2023Gil legaspiNo ratings yet
- Building and Enhancing New Literacies Across The CurriculumDocument119 pagesBuilding and Enhancing New Literacies Across The CurriculumLowela Kasandra100% (3)
- Multiple Logistic Regression Model-LPDocument7 pagesMultiple Logistic Regression Model-LPmanjushreeNo ratings yet
- OUTPUTDocument16 pagesOUTPUTsehu falahNo ratings yet
- Linear Regression Problem FDocument2 pagesLinear Regression Problem Fdarren mapanooNo ratings yet
- Stat Is TikaDocument9 pagesStat Is TikamirantiNo ratings yet
- TP RegressionDocument1 pageTP RegressionMOHAMED EL BACHIR BERRIOUA100% (1)
- Bank Performance DeterminantsDocument8 pagesBank Performance Determinantslucksia thayanithyNo ratings yet
- Business Forecasting Assignment: Name: Mansi Sharma SAP Id: 80011220277 Roll No: A016 Group: 10Document6 pagesBusiness Forecasting Assignment: Name: Mansi Sharma SAP Id: 80011220277 Roll No: A016 Group: 10MANSI SHARMANo ratings yet
- Desarrollo Solemne 3 - ..Ipynb - ColaboratoryDocument4 pagesDesarrollo Solemne 3 - ..Ipynb - ColaboratoryCarola Araya100% (1)
- 5.00 Ecuacion de CalibraciónDocument2 pages5.00 Ecuacion de CalibraciónJORGE LUIS CAMACHO CHNo ratings yet
- Business Research: Corporate Governance in Financial Institutions of BangladeshDocument31 pagesBusiness Research: Corporate Governance in Financial Institutions of BangladeshShahriar HaqueNo ratings yet
- Tax Consulting and Reported Weaknesses in Internal Control: Randy ElderDocument25 pagesTax Consulting and Reported Weaknesses in Internal Control: Randy ElderVirga Putri HermatikaNo ratings yet
- Data final regressionDocument10 pagesData final regressionisaacbougherabNo ratings yet
- VIFmodel 3Document2 pagesVIFmodel 3Van Joshua NunezNo ratings yet
- Olahan Data Sem 1Document18 pagesOlahan Data Sem 1Apriliana KurniasariNo ratings yet
- Ross Criteria ChartDocument6 pagesRoss Criteria ChartdjcarqNo ratings yet
- Blue Bus485 FinalDocument13 pagesBlue Bus485 FinalTamzid Ahmed AnikNo ratings yet
- STRUCTURE CONTROL AND BASE ISOLATION: Numerical Solution using Newmarks MethodDocument14 pagesSTRUCTURE CONTROL AND BASE ISOLATION: Numerical Solution using Newmarks MethodRupesh UpretyNo ratings yet
- SEM DepresiDocument13 pagesSEM DepresiThojing D PallaqiNo ratings yet
- A. Harga Rata-Rata: N LogxiDocument17 pagesA. Harga Rata-Rata: N LogxilutviaNo ratings yet
- Askaria f1051151052 Modul UjiDocument27 pagesAskaria f1051151052 Modul UjiAskaria FahrezaNo ratings yet
- Time-Series, ForecastingDocument12 pagesTime-Series, ForecastingRiska AristiNo ratings yet
- Seminar Final Word FileDocument8 pagesSeminar Final Word FileGhulam MustafaNo ratings yet
- Factors Determining Weight-For-Age Status of Under-Five Children:-Multiple Logistic Regression AnalysisDocument14 pagesFactors Determining Weight-For-Age Status of Under-Five Children:-Multiple Logistic Regression Analysisሻሎም ሃፒ ታዲNo ratings yet
- Notebook: April 13, 2021Document15 pagesNotebook: April 13, 2021siddhiNo ratings yet
- Data Statistics ReportDocument5 pagesData Statistics ReportAeroNo ratings yet
- Table: Cumulative Binomial Probabilities: P P X N C X PDocument7 pagesTable: Cumulative Binomial Probabilities: P P X N C X PFitri HandayaniNo ratings yet
- Chapter01 Solutions 10e SIDocument12 pagesChapter01 Solutions 10e SIMarcos marinhoNo ratings yet
- Id Sepallengthcm Sepalwidthcm Petallengthcm Petalwidthcm Species 0 1 2 3 4Document4 pagesId Sepallengthcm Sepalwidthcm Petallengthcm Petalwidthcm Species 0 1 2 3 4Sebastian CallesNo ratings yet
- Drag On A SphereDocument16 pagesDrag On A SphereMiketanenbaumNo ratings yet
- Parameter Values A12, A21, and CDocument5 pagesParameter Values A12, A21, and Cari suryo lenggonoNo ratings yet
- Assignment 8 6331 PDFDocument11 pagesAssignment 8 6331 PDFALIKNFNo ratings yet
- Principal Component Analysis R Program and OutputDocument7 pagesPrincipal Component Analysis R Program and OutputThameem AnsariNo ratings yet
- Classification ProblemsDocument25 pagesClassification Problemssushanth100% (1)
- Tugas One WayDocument5 pagesTugas One WaymirantiNo ratings yet
- Critical ValueDocument12 pagesCritical ValueZAIRUL AMIN BIN RABIDIN (FRIM)No ratings yet
- Simple Linear RegressionDocument5 pagesSimple Linear Regression2023005No ratings yet
- Height and Basketball True Shooting PercentageDocument15 pagesHeight and Basketball True Shooting PercentageSamia AkterNo ratings yet
- Session 12Document128 pagesSession 12HarisSuprayogiNo ratings yet
- The Box-Jenkins PracticalDocument9 pagesThe Box-Jenkins PracticalDimpho Sonjani-SibiyaNo ratings yet
- LinPro PrintingDocument9 pagesLinPro PrintingtresspasseeNo ratings yet
- Energy Use ANOVA TableDocument3 pagesEnergy Use ANOVA TableEpay Castañares LascuñaNo ratings yet
- UID Sales Perfomance Report09112022Document3 pagesUID Sales Perfomance Report09112022nurkha.crhNo ratings yet
- FDocument84 pagesFBEN BENNo ratings yet
- Linear Control System ProjectDocument15 pagesLinear Control System Projectname choroNo ratings yet
- Equation Solving ExamplesDocument10 pagesEquation Solving Examplesalif08042012No ratings yet
- Equation Solving ExamplesDocument10 pagesEquation Solving Examplesalif08042012No ratings yet
- 6 Investment Appraisal: Project ViabilityDocument7 pages6 Investment Appraisal: Project ViabilityLodhi IsmailNo ratings yet
- Kingrynormalized Data Set AssignmentDocument24 pagesKingrynormalized Data Set Assignment20013122-001No ratings yet
- Pipe flow analysis resultsDocument4 pagesPipe flow analysis resultsJuan MendozaNo ratings yet
- Baseball players' slugging percentages analyzed for 2019-2020 seasonsDocument28 pagesBaseball players' slugging percentages analyzed for 2019-2020 seasonsBharat KoiralaNo ratings yet
- Eigen Values - SnapshotsDocument6 pagesEigen Values - SnapshotsVidya VNo ratings yet
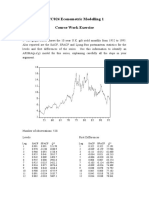
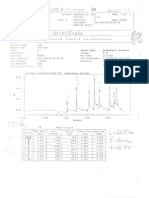
- ECC024 Econometric Modelling 1 Course Work ExerciseDocument4 pagesECC024 Econometric Modelling 1 Course Work Exerciseben_jamin_19No ratings yet
- PVT Sampling - G 11 - W 01-Sample 3Document2 pagesPVT Sampling - G 11 - W 01-Sample 3hitakNo ratings yet
- CFA Model Fit and Factor AnalysisDocument5 pagesCFA Model Fit and Factor AnalysisSyafiq Al FalahNo ratings yet
- Bonus Reports 20130121Document18 pagesBonus Reports 20130121Michael KovachNo ratings yet
- DSPDocument10 pagesDSPKrishnaveni RajNo ratings yet
- Cart-Rf-ANN: Prepared by Muralidharan NDocument16 pagesCart-Rf-ANN: Prepared by Muralidharan NKrishnaveni Raj0% (1)
- Advanced Statistics Business Report: Name: S.Krishnaveni Date: 17/10/2021Document18 pagesAdvanced Statistics Business Report: Name: S.Krishnaveni Date: 17/10/2021Krishna VeniNo ratings yet
- SMDMDocument8 pagesSMDMKrishna VeniNo ratings yet
- Krishnaveni-PM Business ReportDocument23 pagesKrishnaveni-PM Business ReportKrishnaveni RajNo ratings yet
- AsbrDocument23 pagesAsbrKrishnaveni RajNo ratings yet
- DVT Project - KrishnaveniDocument1 pageDVT Project - KrishnaveniKrishnaveni RajNo ratings yet
- SMDM-Business ReportDocument11 pagesSMDM-Business ReportC K SarkarNo ratings yet
- Data Science PMDocument38 pagesData Science PMKrishnaveni RajNo ratings yet
- Krishnaveni-PM Business Report FinalDocument42 pagesKrishnaveni-PM Business Report FinalKrishnaveni RajNo ratings yet
- Krishnaveni-As Business ReportDocument26 pagesKrishnaveni-As Business ReportKrishnaveni RajNo ratings yet
- Krishnaveni-PM Business ReportDocument23 pagesKrishnaveni-PM Business ReportKrishnaveni RajNo ratings yet
- Krishnaveni-PM Business Report FinalDocument42 pagesKrishnaveni-PM Business Report FinalKrishnaveni RajNo ratings yet
- SCJP 1.6 Mock Exam Questions (60 QuestionsDocument32 pagesSCJP 1.6 Mock Exam Questions (60 QuestionsManas GhoshNo ratings yet
- Sonigra Manav Report Finle-Converted EDITEDDocument50 pagesSonigra Manav Report Finle-Converted EDITEDDABHI PARTHNo ratings yet
- Answer Questions Only: Chemical Engineering DeptDocument2 pagesAnswer Questions Only: Chemical Engineering DepthusseinNo ratings yet
- Presentation of Urban RegenerationsDocument23 pagesPresentation of Urban RegenerationsRafiuddin RoslanNo ratings yet
- Useful Relations in Quantum Field TheoryDocument30 pagesUseful Relations in Quantum Field TheoryDanielGutierrez100% (1)
- Common Pesticides in AgricultureDocument6 pagesCommon Pesticides in AgricultureBMohdIshaqNo ratings yet
- Oral Medication PharmacologyDocument4 pagesOral Medication PharmacologyElaisa Mae Delos SantosNo ratings yet
- 2 5 Marking ScheduleDocument6 pages2 5 Marking Scheduleapi-218511741No ratings yet
- KingmakerDocument5 pagesKingmakerIan P RiuttaNo ratings yet
- Proposed Panel Antenna: Globe Telecom ProprietaryDocument2 pagesProposed Panel Antenna: Globe Telecom ProprietaryJason QuibanNo ratings yet
- Medicinal PlantDocument13 pagesMedicinal PlantNeelum iqbalNo ratings yet
- Mad LabDocument66 pagesMad LabBalamurugan MNo ratings yet
- Digital Water Monitoring and Turbidity Quality System Using MicrocontrollerDocument8 pagesDigital Water Monitoring and Turbidity Quality System Using MicrocontrollerIrin DwiNo ratings yet
- Smoktech Vmax User ManualDocument9 pagesSmoktech Vmax User ManualStella PapaNo ratings yet
- MECHANICAL PROPERTIES OF SOLIDSDocument39 pagesMECHANICAL PROPERTIES OF SOLIDSAbdul Musavir100% (1)
- 10 Tips To Support ChildrenDocument20 pages10 Tips To Support ChildrenRhe jane AbucejoNo ratings yet
- Millennium Separation ReportDocument3 pagesMillennium Separation ReportAlexandra AkeNo ratings yet
- A61C00100 Communication and Employee Engagement by Mary Welsh 2Document19 pagesA61C00100 Communication and Employee Engagement by Mary Welsh 2Moeshfieq WilliamsNo ratings yet
- JTP Brochure - 2Document6 pagesJTP Brochure - 2YAKOVNo ratings yet
- 5 Guys Nutrition InfoDocument1 page5 Guys Nutrition InfoJody Ike LinerNo ratings yet
- 41 PDFsam Redis CookbookDocument5 pages41 PDFsam Redis CookbookHữu Hưởng NguyễnNo ratings yet
- Moon Fast Schedule 2024Document1 pageMoon Fast Schedule 2024mimiemendoza18No ratings yet