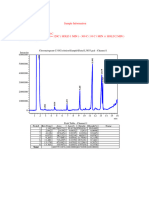
You might also like
- Complex Engineering Problem (CEP) : Topics CoveredDocument2 pagesComplex Engineering Problem (CEP) : Topics CoveredMaisam Abbas100% (1)
- Hidden Secrets of The Alpha CourseDocument344 pagesHidden Secrets of The Alpha CourseC&R Media75% (4)
- Predictive Modelling Alternative Firm Level PDFDocument26 pagesPredictive Modelling Alternative Firm Level PDFAnkita Mishra100% (3)
- MD Anderson Medical Oncology 4th Edition 2022Document1,694 pagesMD Anderson Medical Oncology 4th Edition 2022Iskandar414100% (6)
- Laptop PolicyDocument2 pagesLaptop PolicyKamal SharmaNo ratings yet
- Token Economics BookDocument81 pagesToken Economics BookNara E Aí100% (3)
- Module 4 - Nursing Process and Administration-PharmaDocument13 pagesModule 4 - Nursing Process and Administration-PharmaKelsey MacaraigNo ratings yet
- Authentication and Single Sign-OnDocument48 pagesAuthentication and Single Sign-Onrengasamys100% (2)
- Relationship Between Distance and Delivery TimeDocument5 pagesRelationship Between Distance and Delivery TimeJAISURYA S B.Sc.AIDANo ratings yet
- Solution Manual For Macroeconomics 7th Edition Olivier BlanchardDocument38 pagesSolution Manual For Macroeconomics 7th Edition Olivier Blanchardilvaitekabassou7k10tNo ratings yet
- 14-May - Jupyter NotebookDocument15 pages14-May - Jupyter NotebookAli HassanNo ratings yet
- Drift Method ZPCDocument6 pagesDrift Method ZPCAlfonso EncinasNo ratings yet
- Exploring mineral resource dataDocument9 pagesExploring mineral resource dataRicardo CremaNo ratings yet
- PCA Problem Statement With AnswerDocument22 pagesPCA Problem Statement With AnswerSBS MoviesNo ratings yet
- Task 1Document9 pagesTask 1vansh.jain2021No ratings yet
- 00-023-0677 Nov 30, 2018 12:45 PM (Cristian-Radiometria)Document2 pages00-023-0677 Nov 30, 2018 12:45 PM (Cristian-Radiometria)Ing. Física 2015No ratings yet
- Test ExcelDocument31 pagesTest ExcelLucas OsorioNo ratings yet
- QRT PCR Kursus BiomolDocument40 pagesQRT PCR Kursus BiomolEndang SusilowatiNo ratings yet
- Half HalfDocument22 pagesHalf HalfKent NguyenNo ratings yet
- Data Perhitungan FluidisasiDocument10 pagesData Perhitungan FluidisasiWayan PipitNo ratings yet
- Ardl Analysis Chapter Four UpdatedDocument11 pagesArdl Analysis Chapter Four Updatedsadiqmedical160No ratings yet
- Phthlates 0.1 PPM PDFDocument1 pagePhthlates 0.1 PPM PDFHendy Dwi WarmikoNo ratings yet
- Team 2, Please Contact Alex Franco (Afrancoh@fiu - Edu) in Advance Regarding Running YourDocument4 pagesTeam 2, Please Contact Alex Franco (Afrancoh@fiu - Edu) in Advance Regarding Running YoursantanucctNo ratings yet
- Cli Noch LoreDocument5 pagesCli Noch LorejuanNo ratings yet
- Alkynyl-Functionalized Gold NHC Complexes and TheiDocument5 pagesAlkynyl-Functionalized Gold NHC Complexes and TheikarthickrajaNo ratings yet
- Co IiiDocument1 pageCo IiiAaditya GargNo ratings yet
- Enhancement of Al Meerad and Fuhais Wwtps Pvsupdate22nov2018Document23 pagesEnhancement of Al Meerad and Fuhais Wwtps Pvsupdate22nov2018jon aquinoNo ratings yet
- Chem162 IMForces PartII Report PC Gradescope 102421 PDFDocument7 pagesChem162 IMForces PartII Report PC Gradescope 102421 PDF于一阳No ratings yet
- Chapter 7.2 Classwork SolutionDocument2 pagesChapter 7.2 Classwork Solution205695 Onyeukwu Stephen Gift IndustrialNo ratings yet
- Task 1Document8 pagesTask 1vinay bharthuNo ratings yet
- Linear Programming - Simplex Vs Interior-2-10Document9 pagesLinear Programming - Simplex Vs Interior-2-10Fan ClubNo ratings yet
- Bridge Test Data InsightsDocument33 pagesBridge Test Data InsightsRenxiang LuNo ratings yet
- Final Proximate AnalysisDocument9 pagesFinal Proximate AnalysisAmy SuarezNo ratings yet
- Aerasi - AnalysisReportWithMFGResultsDocument13 pagesAerasi - AnalysisReportWithMFGResultseti apriyantiNo ratings yet
- NO. Elements Page NoDocument21 pagesNO. Elements Page NoandriasNo ratings yet
- Apéndice Entalpías Perry + Felder + HimmelblauDocument7 pagesApéndice Entalpías Perry + Felder + HimmelblauJared LondoNo ratings yet
- D 3Document1 pageD 3Saba GheniNo ratings yet
- Decanter FunctionDocument6 pagesDecanter FunctionJamil HytNo ratings yet
- ML LAB 12 - Jupyter NotebookDocument11 pagesML LAB 12 - Jupyter NotebookrishithaNo ratings yet
- Renewables Power Off Grid ConfigurationDocument4 pagesRenewables Power Off Grid ConfigurationUdit GuptaNo ratings yet
- Glass ClassificationDocument3 pagesGlass ClassificationSiddharth Tiwari100% (2)
- Amis0118 CertificateDocument7 pagesAmis0118 CertificatePumulo MukubeNo ratings yet
- CleaningData Chapter 1 With RDocument21 pagesCleaningData Chapter 1 With RMahmoud TriguiNo ratings yet
- ChroZen GC Brochure ENG 2022Document16 pagesChroZen GC Brochure ENG 2022RafaelGerardoAgueroZamoraNo ratings yet
- bIRUL LAG - 1Document3 pagesbIRUL LAG - 1Kurniawan ArikaNo ratings yet
- Cover Modul 8 (3 Files Merged)Document9 pagesCover Modul 8 (3 Files Merged)LilyNo ratings yet
- Data Vizualization - Jupyter NotebookDocument20 pagesData Vizualization - Jupyter Notebookdimple mahaduleNo ratings yet
- HKBK College of EngineeringDocument51 pagesHKBK College of EngineeringkarthikNo ratings yet
- Realtime PCRDocument78 pagesRealtime PCRAlfanNo ratings yet
- Ie7b04477 Si 001Document6 pagesIe7b04477 Si 001Bilal KazmiNo ratings yet
- Vapor Liquid Equilibria For Water + Propylene Glycols Binary Systems: Experimental Data and RegressionDocument10 pagesVapor Liquid Equilibria For Water + Propylene Glycols Binary Systems: Experimental Data and RegressionGrinder Hernan Rojas UrcohuarangaNo ratings yet
- NFC Iet Multan: Faiz-Ul-RehmanDocument3 pagesNFC Iet Multan: Faiz-Ul-RehmanMuhammad Umair AliNo ratings yet
- Series4 - Renata Putri HenessaDocument12 pagesSeries4 - Renata Putri HenessaPerfect DarksideNo ratings yet
- 30% - 350 - Katalis - 45 Menit Pengenceran 2 Coba Pertama KaliDocument1 page30% - 350 - Katalis - 45 Menit Pengenceran 2 Coba Pertama KaliGTheresiaNo ratings yet
- Analysis of 30%_350_katalis_45 menit pengenceran 2 SampleDocument1 pageAnalysis of 30%_350_katalis_45 menit pengenceran 2 SampleGTheresiaNo ratings yet
- Results FluidisationDocument4 pagesResults FluidisationClifford Dwight RicanorNo ratings yet
- Measuring Process Capability of Manufacturing ExperimentsDocument12 pagesMeasuring Process Capability of Manufacturing ExperimentsAman NagraleNo ratings yet
- Technologyname Phase2Document20 pagesTechnologyname Phase2vasusam300No ratings yet
- Kasus 6Document2 pagesKasus 6Rio ZulmansyahNo ratings yet
- Exp 01-B Feature Selection and ExtractionDocument12 pagesExp 01-B Feature Selection and ExtractionR J SHARIN URK21CS5022No ratings yet
- PT. Mulya Adhi Paramita Certificate of AnalysisDocument5 pagesPT. Mulya Adhi Paramita Certificate of AnalysisRistian Agil Yan SagilNo ratings yet
- PandasDocument21 pagesPandasShubham dattatray koteNo ratings yet
- FDS Solved SlipsDocument63 pagesFDS Solved Slipsyashm4071100% (1)
- RSRAN104 - PRACH Propagation Delay-RSRAN-WCEL-day-rsran WCDMA16 Reports RSRAN104 xml-2020 10 30-10 46 58 890Document17 pagesRSRAN104 - PRACH Propagation Delay-RSRAN-WCEL-day-rsran WCDMA16 Reports RSRAN104 xml-2020 10 30-10 46 58 890Le Duc NamNo ratings yet
- Pattern 1272 AnataseDocument6 pagesPattern 1272 AnataseNifia Lutfianica100% (1)
- Heart Disease - EDA and PredictionDocument13 pagesHeart Disease - EDA and PredictionXgnc CvkiNo ratings yet
- KnowTechFrameworks1 PDFDocument11 pagesKnowTechFrameworks1 PDFXgnc CvkiNo ratings yet
- Microcollege - Online: 50 Keys To Crack Aptitude TestDocument27 pagesMicrocollege - Online: 50 Keys To Crack Aptitude TestXgnc CvkiNo ratings yet
- Study MaterialDocument77 pagesStudy MaterialXgnc CvkiNo ratings yet
- DIPR - P.R.NO - 308 - Hon'ble CM Press Release (Lockdown) - Date - 20.06.2021Document15 pagesDIPR - P.R.NO - 308 - Hon'ble CM Press Release (Lockdown) - Date - 20.06.2021josekrNo ratings yet
- Tancet Model Question PaperDocument21 pagesTancet Model Question Paperroshiniea80% (5)
- IC Engine Basics ExplainedDocument12 pagesIC Engine Basics ExplainedXgnc CvkiNo ratings yet
- ACR - Grolier Turn Over of Online ResourcesDocument4 pagesACR - Grolier Turn Over of Online ResourcesIreneo Aposacas Jr.No ratings yet
- Coverage and Profiling For Real-Time Tiny KernelsDocument6 pagesCoverage and Profiling For Real-Time Tiny Kernelsanusree_bhattacharjeNo ratings yet
- Copier CoDocument9 pagesCopier CoHun Yao ChongNo ratings yet
- Unit 1Document176 pagesUnit 1kassahun meseleNo ratings yet
- Unbalanced Dynamic Microphone Pre-AmpDocument1 pageUnbalanced Dynamic Microphone Pre-AmpAhmad FauziNo ratings yet
- Q Asgt - Biz Law - A192Document10 pagesQ Asgt - Biz Law - A192otaku himeNo ratings yet
- MSG 01084Document4 pagesMSG 01084testiandiniNo ratings yet
- 10 Days 7 NightsDocument5 pages10 Days 7 NightsSisca SetiawatyNo ratings yet
- Kick Control: BY: Naga Ramesh D. Assistant Professor Petroleum Engineering Dept. KlefDocument13 pagesKick Control: BY: Naga Ramesh D. Assistant Professor Petroleum Engineering Dept. Klefavula43No ratings yet
- Electricity (Innovative Licence) Regulations 2023Document16 pagesElectricity (Innovative Licence) Regulations 2023BernewsAdminNo ratings yet
- IH May-June 2022Document60 pagesIH May-June 2022Omkar R PujariNo ratings yet
- 4 AppleDocument9 pages4 AppleSam Peter GeorgieNo ratings yet
- VerizonClaimAffidavit 448952883 PDFDocument2 pagesVerizonClaimAffidavit 448952883 PDFJanetheNo ratings yet
- Ethernet Networking EssentialsDocument5 pagesEthernet Networking Essentialsjmiguel000No ratings yet
- Swiss Ephemeris Table of Houses for Southern HemisphereDocument121 pagesSwiss Ephemeris Table of Houses for Southern HemisphereAnonymous 5S91GvOgNo ratings yet
- Calculation of absorption properties of absorbent materialsDocument4 pagesCalculation of absorption properties of absorbent materialsRezaul Karim TutulNo ratings yet
- CPRI Annual Report 2010-11 Highlights Record RevenueDocument206 pagesCPRI Annual Report 2010-11 Highlights Record Revenueshivendra singhNo ratings yet
- GSV EDU Factbook Apr 13 2012Document127 pagesGSV EDU Factbook Apr 13 2012Innovative Educational Services, CCIUNo ratings yet
- Microeconomics Primer 1Document15 pagesMicroeconomics Primer 1md1sabeel1ansariNo ratings yet
- This Study Resource WasDocument6 pagesThis Study Resource WasRian RorresNo ratings yet
- Liftking Forklift PDIDocument1 pageLiftking Forklift PDIManual ForkliftNo ratings yet
- English For Academic and Professional Purposes: Quarter 1 - Module 3Document9 pagesEnglish For Academic and Professional Purposes: Quarter 1 - Module 3John Vincent Salmasan100% (5)
- Example of An Essay CAEDocument3 pagesExample of An Essay CAEJon ArriaranNo ratings yet