You might also like
- Lecture RLDocument37 pagesLecture RLprakuld04No ratings yet
- Reinforcement Learning ExplainedDocument34 pagesReinforcement Learning ExplainedAnum KhawajaNo ratings yet
- A17 ComplexdecisionsDocument28 pagesA17 ComplexdecisionsAbhishek NandaNo ratings yet
- DD2431 Machine Learning Lab 4: Reinforcement Learning Python VersionDocument9 pagesDD2431 Machine Learning Lab 4: Reinforcement Learning Python VersionbboyvnNo ratings yet
- POMDP Tutoria POMDP - TutoriallDocument55 pagesPOMDP Tutoria POMDP - TutoriallEhsan Elahi BashirNo ratings yet
- Lecture 29 RLDocument38 pagesLecture 29 RLprakuld04No ratings yet
- 5.4-Reinforcement Learning-Part2-Learning-AlgorithmsDocument15 pages5.4-Reinforcement Learning-Part2-Learning-Algorithmspolinati.vinesh2023No ratings yet
- An Introduction To Markov Decision Processes: Bob Givan Ron Parr Purdue University Duke UniversityDocument23 pagesAn Introduction To Markov Decision Processes: Bob Givan Ron Parr Purdue University Duke UniversityRosin PriceNo ratings yet
- RL Instructor: Max WellingDocument18 pagesRL Instructor: Max WellingZuzarNo ratings yet
- 5.4-Reinforcement Learning-Part1-IntroductionDocument15 pages5.4-Reinforcement Learning-Part1-Introductionpolinati.vinesh2023No ratings yet
- Markov Decision Processes: Stochastic, Sequential EnvironmentsDocument20 pagesMarkov Decision Processes: Stochastic, Sequential Environmentsmikey61No ratings yet
- RL 10 QUESTIONS FOR MID II Scheme of EvaluvationDocument15 pagesRL 10 QUESTIONS FOR MID II Scheme of EvaluvationmovatehireNo ratings yet
- MDP Presentation CS594Document31 pagesMDP Presentation CS594Mohan SharmaNo ratings yet
- Markov Decision Process TutorialDocument22 pagesMarkov Decision Process TutorialVinitha VasudevanNo ratings yet
- NIPS 2004 Experts in A Markov Decision Process Paper CompressedDocument8 pagesNIPS 2004 Experts in A Markov Decision Process Paper CompressedTasya Syifa AltanzaniaNo ratings yet
- Sec 12Document5 pagesSec 12Prateer Kr RoyNo ratings yet
- Deterministic Policy Gradient Algorithms Outperforms StochasticDocument9 pagesDeterministic Policy Gradient Algorithms Outperforms Stochastic杨烨峰No ratings yet
- Sp14 Cs188 Lecture 8 - Mdps IDocument50 pagesSp14 Cs188 Lecture 8 - Mdps Ixixip66099No ratings yet
- Monte Carlo LearningDocument14 pagesMonte Carlo LearningSivasathiya GNo ratings yet
- ML Unit 4Document9 pagesML Unit 4themojlvlNo ratings yet
- MDP PDFDocument37 pagesMDP PDFbsudheertecNo ratings yet
- Unit 4Document56 pagesUnit 4randyyNo ratings yet
- Rewards in Reinforcement LearningDocument12 pagesRewards in Reinforcement LearningJack LumberNo ratings yet
- Reinforcement Learning and Control: CS229 Lecture NotesDocument15 pagesReinforcement Learning and Control: CS229 Lecture NotesIvan AvramovNo ratings yet
- RL TutorialDocument17 pagesRL TutorialNirajDhotreNo ratings yet
- Markov Decision Processes & Reinforcement Learning: Megan Smith Lehigh University, Fall 2006Document40 pagesMarkov Decision Processes & Reinforcement Learning: Megan Smith Lehigh University, Fall 2006Sanja Lazarova-MolnarNo ratings yet
- Policies, Search, UtilityDocument13 pagesPolicies, Search, UtilityAimee LemmaNo ratings yet
- Reinforcement Learning Key ConceptsDocument35 pagesReinforcement Learning Key Conceptsfull entertainmentNo ratings yet
- Reinforcement Learning I:: The Setting and Classical Stochastic Dynamic Programming AlgorithmsDocument42 pagesReinforcement Learning I:: The Setting and Classical Stochastic Dynamic Programming AlgorithmsAdhityo PriyambodoNo ratings yet
- reinforcement-learningDocument45 pagesreinforcement-learningPooja AngolkarNo ratings yet
- Files 1 2019 June NotesHubDocument 1559416363Document6 pagesFiles 1 2019 June NotesHubDocument 1559416363mail.sushilk8403No ratings yet
- Reinforcement Learning: Karan KathpaliaDocument80 pagesReinforcement Learning: Karan KathpaliaRaghuNo ratings yet
- EE 675 Lecture 27th MarchDocument4 pagesEE 675 Lecture 27th Marchsachin bhadangNo ratings yet
- Reinforcement Learning and Control Andrew NG Vid Lecture 16-17Document15 pagesReinforcement Learning and Control Andrew NG Vid Lecture 16-17Ehsan Elahi BashirNo ratings yet
- Reinforcement LearningDocument32 pagesReinforcement Learningvedang maheshwariNo ratings yet
- Lnotes 03Document11 pagesLnotes 03mouaad ibnealryfNo ratings yet
- _RL Unit 5Document30 pages_RL Unit 5gilloshanonpNo ratings yet
- Reinforcement Learning: Russell and Norvig: CH 21Document16 pagesReinforcement Learning: Russell and Norvig: CH 21ZuzarNo ratings yet
- 17 MDPDocument28 pages17 MDPnada abdelrahmanNo ratings yet
- A Brief Introduction To Reinforcement LearningDocument4 pagesA Brief Introduction To Reinforcement LearningNarendra PatelNo ratings yet
- RL Project_ Deep Q-Network Agent ReportDocument11 pagesRL Project_ Deep Q-Network Agent ReportPhạm TịnhNo ratings yet
- CS 188 Introduction To Artificial Intelligence Summer 2019 Note 4Document9 pagesCS 188 Introduction To Artificial Intelligence Summer 2019 Note 4hellosunshine95No ratings yet
- Control Crash CourseDocument41 pagesControl Crash Courseraa2010No ratings yet
- CS6700_RL_2024_WA1Document7 pagesCS6700_RL_2024_WA1Rahul me20b145No ratings yet
- Stochastic Optimization Lecture NotesDocument23 pagesStochastic Optimization Lecture NotesShipra AgrawalNo ratings yet
- CSD311: Artificial IntelligenceDocument11 pagesCSD311: Artificial IntelligenceAyaan KhanNo ratings yet
- Lecture Notes Deep Reinforcement Learning: Generalizability in Deep RLDocument7 pagesLecture Notes Deep Reinforcement Learning: Generalizability in Deep RLRajat RaiNo ratings yet
- Reinforcement Learning in a Nutshell: Value Functions and Policy GradientsDocument12 pagesReinforcement Learning in a Nutshell: Value Functions and Policy GradientsDope IndianNo ratings yet
- Unit 7Document43 pagesUnit 7Yuvraj RanaNo ratings yet
- Question: Devise A Hill Climbing Search Based Approach To Solve N-City Tsps. You Must de Ne All Req..Document4 pagesQuestion: Devise A Hill Climbing Search Based Approach To Solve N-City Tsps. You Must de Ne All Req..Malik AsadNo ratings yet
- Lecture Notes Classical Reinforcement Learning: Agent-Environment InteractionDocument11 pagesLecture Notes Classical Reinforcement Learning: Agent-Environment InteractionRajat RaiNo ratings yet
- Reinforcement Learning: Russell and Norvig: CH 21Document16 pagesReinforcement Learning: Russell and Norvig: CH 21ZuzarNo ratings yet
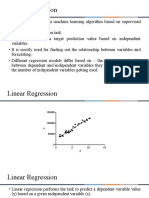
- Introduction To Machine Learning Algorithms: Linear RegressionDocument1 pageIntroduction To Machine Learning Algorithms: Linear RegressionRahul ThoratNo ratings yet
- Regression PPTDocument21 pagesRegression PPTRakesh bhukyaNo ratings yet
- Reinforcement LearningDocument46 pagesReinforcement LearningShagunNo ratings yet
- RL FrraDocument10 pagesRL FrraVishal TarwatkarNo ratings yet
- Lecture 06 EngDocument13 pagesLecture 06 EngParamhans MishraNo ratings yet
- Sample Size for Analytical Surveys, Using a Pretest-Posttest-Comparison-Group DesignFrom EverandSample Size for Analytical Surveys, Using a Pretest-Posttest-Comparison-Group DesignNo ratings yet
- Software Engineering Interview QuestionDocument23 pagesSoftware Engineering Interview QuestionHarpreet Singh BaggaNo ratings yet
- DXC Verbal Ability Test PaperDocument8 pagesDXC Verbal Ability Test PaperHarpreet Singh Bagga100% (1)
- OS Interview Questions ExplainedDocument28 pagesOS Interview Questions ExplainedHarpreet Singh BaggaNo ratings yet
- S.S. Coachings, S.C.O. 30, Sector: 41-D, Chandigarh: Assignment: Selection StructureDocument4 pagesS.S. Coachings, S.C.O. 30, Sector: 41-D, Chandigarh: Assignment: Selection StructureDipin Preet SinghNo ratings yet
- HR Interview QuestionDocument9 pagesHR Interview QuestionHarpreet Singh BaggaNo ratings yet
- TCS Technical Interview QuestionsDocument8 pagesTCS Technical Interview QuestionsHarpreet Singh BaggaNo ratings yet
- Technical Interview Question (Wipro) Memory Management In CDocument21 pagesTechnical Interview Question (Wipro) Memory Management In CHarpreet Singh BaggaNo ratings yet
- PuzzlesDocument7 pagesPuzzlesHarpreet Singh BaggaNo ratings yet
- Puzzles 1Document5 pagesPuzzles 1Harpreet Singh BaggaNo ratings yet
- Spot The ErrorDocument4 pagesSpot The ErrorHarpreet Singh BaggaNo ratings yet
- Data Base Managment System Interview QuestionDocument31 pagesData Base Managment System Interview QuestionHarpreet Singh BaggaNo ratings yet
- C++ Programming Interview Questions & AnswersDocument27 pagesC++ Programming Interview Questions & AnswersHarpreet Singh BaggaNo ratings yet
- Data Structure & Algorithem InterviewDocument30 pagesData Structure & Algorithem InterviewHarpreet Singh BaggaNo ratings yet
- Capgemini Technical Interview QuestionsDocument12 pagesCapgemini Technical Interview QuestionsHarpreet Singh BaggaNo ratings yet
- Oracle QDocument2 pagesOracle QHarpreet Singh BaggaNo ratings yet
- Computer Network Interview QuestionDocument23 pagesComputer Network Interview QuestionHarpreet Singh BaggaNo ratings yet
- If ElseDocument11 pagesIf ElseHarpreet Singh BaggaNo ratings yet
- Classification Accuracy Logarithmic Loss Confusion Matrix Area Under Curve F1 Score Mean Absolute ErrorDocument9 pagesClassification Accuracy Logarithmic Loss Confusion Matrix Area Under Curve F1 Score Mean Absolute ErrorHarpreet Singh BaggaNo ratings yet
- RL and Bellman EquationDocument7 pagesRL and Bellman EquationHarpreet Singh BaggaNo ratings yet
- AI Informed Search Algorithms.Document8 pagesAI Informed Search Algorithms.Harpreet Singh BaggaNo ratings yet
- Markov Decision ProcessDocument11 pagesMarkov Decision ProcessHarpreet Singh BaggaNo ratings yet
- Reinforcement Learning, Q-LearningDocument20 pagesReinforcement Learning, Q-LearningHarpreet Singh BaggaNo ratings yet
- Unit-3 DS StudentsDocument35 pagesUnit-3 DS StudentsHarpreet Singh BaggaNo ratings yet
- Validation Over Under Fir Unit 5Document6 pagesValidation Over Under Fir Unit 5Harpreet Singh BaggaNo ratings yet
- Achieving Universal Human OrderDocument9 pagesAchieving Universal Human OrderHarpreet Singh BaggaNo ratings yet
- Unit-4 DS StudentDocument43 pagesUnit-4 DS StudentHarpreet Singh BaggaNo ratings yet
- Detailed List of Tasks:: Course Code: BTCS617-18 Course Title: Data Science Lab L:0 T:0 2 P: 1creditsDocument1 pageDetailed List of Tasks:: Course Code: BTCS617-18 Course Title: Data Science Lab L:0 T:0 2 P: 1creditsHarpreet Singh BaggaNo ratings yet
- Project Report ON Online Car Rental SystemDocument12 pagesProject Report ON Online Car Rental SystemHarpreet Singh BaggaNo ratings yet
- Mid Term Report of Car Rental SystemDocument15 pagesMid Term Report of Car Rental SystemHarpreet Singh BaggaNo ratings yet
- BIGuidebook Templates - BI Logical Data Model - Data Integration DesignDocument12 pagesBIGuidebook Templates - BI Logical Data Model - Data Integration DesignShahina H CrowneNo ratings yet
- ks20201 Sample Questions Psycholinguistics Module3Document6 pagesks20201 Sample Questions Psycholinguistics Module3Anurag TiwariNo ratings yet
- Travel directions LPU-Batangas from Manila, Laguna, Quezon, CaviteDocument1 pageTravel directions LPU-Batangas from Manila, Laguna, Quezon, CaviteMark Levin Munar100% (1)
- Huawei Technologies Network Router B681Document12 pagesHuawei Technologies Network Router B681Eduardo Vaz RibeiroNo ratings yet
- The World in Which We Believe in Is The Only World We Live inDocument26 pagesThe World in Which We Believe in Is The Only World We Live inYusufMiddeyNo ratings yet
- Expansion Joint PSDocument2 pagesExpansion Joint PSYoga SaputraNo ratings yet
- PackMan ReportDocument41 pagesPackMan ReportPrakash SamshiNo ratings yet
- Function Apollo Amadeus: Sign In/OutDocument16 pagesFunction Apollo Amadeus: Sign In/OutMabs GaddNo ratings yet
- Akhtamov A.A. - Destination C1-C2, Test CollectionDocument37 pagesAkhtamov A.A. - Destination C1-C2, Test CollectionNguyen NhiNo ratings yet
- SreejithDocument23 pagesSreejithAkn SNo ratings yet
- Tda7266 PDFDocument9 pagesTda7266 PDFRenato HernandezNo ratings yet
- Lanco Solar EPC leaderDocument19 pagesLanco Solar EPC leaderShabir TrambooNo ratings yet
- Daily DAWN News Vocabulary With Urdu Meaning (05 April 2020) PDFDocument6 pagesDaily DAWN News Vocabulary With Urdu Meaning (05 April 2020) PDFAEO Begowala100% (2)
- Practical Training Seminar Report FormatDocument8 pagesPractical Training Seminar Report FormatShrijeet PugaliaNo ratings yet
- Certificate of Incorporation Phlips India LimitedDocument1 pageCertificate of Incorporation Phlips India LimitedRam AgarwalNo ratings yet
- Alejandro D. Ramos - Tourism Development Economics, Management - 2008 PDFDocument258 pagesAlejandro D. Ramos - Tourism Development Economics, Management - 2008 PDFSanjiv RudrakarNo ratings yet
- Ac and DC MeasurementsDocument29 pagesAc and DC MeasurementsRudra ChauhanNo ratings yet
- Analyzing an Anti-Smoking Poster Using a Formalist ApproachDocument20 pagesAnalyzing an Anti-Smoking Poster Using a Formalist ApproachAlphred Jann NaparanNo ratings yet
- A Is Called The Base and N Is Called The Exponent: Grade 7 Math Lesson 21: Laws of Exponents Learning GuideDocument4 pagesA Is Called The Base and N Is Called The Exponent: Grade 7 Math Lesson 21: Laws of Exponents Learning GuideKez MaxNo ratings yet
- Pearson Knowledge Management An Integrated Approach 2nd Edition 0273726854Document377 pagesPearson Knowledge Management An Integrated Approach 2nd Edition 0273726854karel de klerkNo ratings yet
- Memo-on-Orientation and Submission of PNPKIDocument5 pagesMemo-on-Orientation and Submission of PNPKICoronia Mermaly LamsenNo ratings yet
- E-Ship Assignment 2 Utkarsh Surjey MBA-FT-EDocument3 pagesE-Ship Assignment 2 Utkarsh Surjey MBA-FT-Eutkarsh surjeyNo ratings yet
- Vidya Mandir Public School Class 11 Computer Science String Assignment SolutionsDocument5 pagesVidya Mandir Public School Class 11 Computer Science String Assignment SolutionsArun SharmaNo ratings yet
- Challan FormDocument2 pagesChallan FormSingh KaramvirNo ratings yet
- 720-C-001 (Vent Wash Column)Document4 pages720-C-001 (Vent Wash Column)idilfitriNo ratings yet
- 5S ManualDocument60 pages5S ManualMun Hein ZawNo ratings yet
- Substitution in The Linguistics of Text and Grammatical ThoughtDocument17 pagesSubstitution in The Linguistics of Text and Grammatical ThoughtThảo HanahNo ratings yet
- August Morning WorkDocument20 pagesAugust Morning Workapi-471325484No ratings yet
- BITS Vulnerability Management Maturity ModelDocument19 pagesBITS Vulnerability Management Maturity ModelJack JacksonNo ratings yet
- EPFO Declaration FormDocument4 pagesEPFO Declaration FormSiddharth PednekarNo ratings yet