You might also like
- Tailieuxanh Bai Tap Mon Lap Trinh Hop Ngu So 5 0346Document18 pagesTailieuxanh Bai Tap Mon Lap Trinh Hop Ngu So 5 0346Thanhtùng BùiNo ratings yet
- Multivariable Calculus 10th Edition Larson Test BankDocument25 pagesMultivariable Calculus 10th Edition Larson Test BankJoshuaSnowexds100% (54)
- Loi GiaiDocument10 pagesLoi GiaiMusic NonstopNo ratings yet
- FMS Assignment 3.2Document12 pagesFMS Assignment 3.2Addi TorNo ratings yet
- Complete Cellist - Rudolf MatzDocument163 pagesComplete Cellist - Rudolf Matzevans_pritchard100% (2)
- Preferable Welded Joints of Plate EdgesDocument11 pagesPreferable Welded Joints of Plate EdgesSinyoe Sii DjumNo ratings yet
- ProofsDocument46 pagesProofsmasrawy eduNo ratings yet
- Data Definitions and Stack OperationsDocument5 pagesData Definitions and Stack OperationsakhiyarwaladiNo ratings yet
- Jaydep Paul 021 Ca4Document7 pagesJaydep Paul 021 Ca4FANTANo ratings yet
- Review: LanguageDocument1 pageReview: LanguageSOUFIAN AKABBALNo ratings yet
- Aps Mid 2016Document1 pageAps Mid 2016Mansoor SarwarNo ratings yet
- Blair StructureOfLispCompilerDocument26 pagesBlair StructureOfLispCompilersheldon bazingaNo ratings yet
- AKG BX5 ManualDocument18 pagesAKG BX5 Manualmartin.mk-vhweb.deNo ratings yet
- Adobe Scan 14 Mar 2024Document5 pagesAdobe Scan 14 Mar 2024Sanjay SNo ratings yet
- Adobe Scan Apr 13, 2022Document4 pagesAdobe Scan Apr 13, 2022Beat ThemeatNo ratings yet
- ExercisesontheGrammaloguesandContractionsofPitmansShorthand 10511074Document45 pagesExercisesontheGrammaloguesandContractionsofPitmansShorthand 10511074ivankagupta4No ratings yet
- MWE - Unit 2 NotesDocument16 pagesMWE - Unit 2 Notesmuskulayashwanthreddy175No ratings yet
- MCQ EspDocument34 pagesMCQ EspYosef KirosNo ratings yet
- 1 Trabalho de ED Turma A Revis Ao de CBDocument11 pages1 Trabalho de ED Turma A Revis Ao de CBWilliam Nunes PinheiroNo ratings yet
- Problem SolvingDocument2 pagesProblem SolvingAlisa MyrgorodskaNo ratings yet
- PDF Metodologia Producerii de Samanta La Mazare CompressDocument9 pagesPDF Metodologia Producerii de Samanta La Mazare CompressclaudiaNo ratings yet
- Chem Work Sheet Grade 11 Unit-2Document12 pagesChem Work Sheet Grade 11 Unit-2wayesoaliyi92No ratings yet
- PDF Tarea X - CompressDocument10 pagesPDF Tarea X - CompressCarlos LopezNo ratings yet
- CS60057 Speech and Natural Language Processing MA 2016Document2 pagesCS60057 Speech and Natural Language Processing MA 2016Nirmalendu KumarNo ratings yet
- Statistics Exam Sheet PDFDocument7 pagesStatistics Exam Sheet PDFRdxNo ratings yet
- GE Notes 1Document11 pagesGE Notes 1swastikNo ratings yet
- Ushtrime Teorema Transportit Reynolds, Ekuacionet BazeDocument6 pagesUshtrime Teorema Transportit Reynolds, Ekuacionet BazealtindorriNo ratings yet
- FCJHRDN KN Ibahrbthrfh Inyns KN Ihs 'Bsns FCJHRDN KN Ibahrbthrfh Inyns KN Ihs 'Bsns Fknbins FknbinsDocument5 pagesFCJHRDN KN Ibahrbthrfh Inyns KN Ihs 'Bsns FCJHRDN KN Ibahrbthrfh Inyns KN Ihs 'Bsns Fknbins FknbinsJulio Cesar Tellez CaceresNo ratings yet
- Eg Assignment 01 and 02 (Ap)Document10 pagesEg Assignment 01 and 02 (Ap)Tushar AkareNo ratings yet
- ASIC Assignment - 1Document6 pagesASIC Assignment - 1MANGAL KUMAR MOHAPATRANo ratings yet
- A Banach Space With Basis Constant Greater Than 1 (P.Enflo)Document5 pagesA Banach Space With Basis Constant Greater Than 1 (P.Enflo)Miguel Ángel Acebo VisanzayNo ratings yet
- BOSS Cryptanalyst Handbook With IndexDocument64 pagesBOSS Cryptanalyst Handbook With IndexTobenna MeniruNo ratings yet
- Outpost 31 Campaign CompressedDocument6 pagesOutpost 31 Campaign Compressednacho.jimenezNo ratings yet
- PL SQL (Programs)Document9 pagesPL SQL (Programs)Sankaraiah MudiNo ratings yet
- Sanar La Verguenza Que Nos Domina - John BradshawDocument154 pagesSanar La Verguenza Que Nos Domina - John BradshawIsabel Cristina García TovarNo ratings yet
- Calculus Larson 10th Edition Test BankDocument36 pagesCalculus Larson 10th Edition Test Bankkapnomar.drused.gz6n100% (41)
- Piecewise Linear Topology HudsonDocument289 pagesPiecewise Linear Topology HudsonjatinjangraonlyNo ratings yet
- Instructions: As A Group, Decipher The Encrypted Message Using The Specified Key or CipherDocument4 pagesInstructions: As A Group, Decipher The Encrypted Message Using The Specified Key or CipherJustin Paul GallanoNo ratings yet
- DevopsDocument7 pagesDevopsAniket SonaleNo ratings yet
- Auto EncodersDocument7 pagesAuto EncodersSrikar VadakattuNo ratings yet
- DE Lab 3Document7 pagesDE Lab 3AKNo ratings yet
- Uni Ti:Basi Csoffl Ui DpowerandpumpsDocument35 pagesUni Ti:Basi Csoffl Ui DpowerandpumpsSuryakant LadNo ratings yet
- Qdoc - Tips Street Effective Martial ArtsDocument11 pagesQdoc - Tips Street Effective Martial ArtstrinhhongtaiNo ratings yet
- Unit 1 and 2 BXEDocument37 pagesUnit 1 and 2 BXEshanky2338No ratings yet
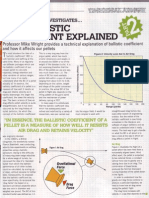
- The Ballistic Coeficient Explai.Document3 pagesThe Ballistic Coeficient Explai.Jorge Rodriguez Fernandez100% (2)
- Sa CND 3em Xam: Koll No. B'Ti8Eceo26Document14 pagesSa CND 3em Xam: Koll No. B'Ti8Eceo26AnujNo ratings yet
- MP Practical 7Document7 pagesMP Practical 7C1 314 Krishna GavaneNo ratings yet
- G.princy XII C .... Comp - App PaperDocument18 pagesG.princy XII C .... Comp - App PaperEvanglin .gNo ratings yet
- Brosur Mini BankerDocument2 pagesBrosur Mini BankerRama Asmara TariganNo ratings yet
- Ax Ax: Macro Mov MovDocument2 pagesAx Ax: Macro Mov MovSangeetha GowdaNo ratings yet
- Adobe Scan 21 Dec 2020Document12 pagesAdobe Scan 21 Dec 2020Sanzar Rahman 1621555030No ratings yet
- Assume Nothing: Previous Home NextDocument42 pagesAssume Nothing: Previous Home NextHassaan RanaNo ratings yet
- PAB 01 DatasheetDocument7 pagesPAB 01 DatasheetCarlos Amadeu CasarimNo ratings yet
- DSDV and Aodv Varshi PDFDocument8 pagesDSDV and Aodv Varshi PDFKANNAMGUNTA POORNIMA SEKHARNo ratings yet
- DAA-Module 4 (Part 2) - S MercyDocument24 pagesDAA-Module 4 (Part 2) - S MercyIshita SinghalNo ratings yet
- IQI IQI: ) ) (Ub B (Ub Bs BH IQI6 S BH IQI6Document16 pagesIQI IQI: ) ) (Ub B (Ub Bs BH IQI6 S BH IQI6Raul Villa100% (1)
- Bahan Toefl Skill 1-12Document17 pagesBahan Toefl Skill 1-12dian suprianaNo ratings yet
- Dokumen - Tips Kitchen Aid k45 Service Manual For Hobart Made Vintage MixersDocument30 pagesDokumen - Tips Kitchen Aid k45 Service Manual For Hobart Made Vintage Mixershartfordmove9328No ratings yet
- PatternDocument3 pagesPatternprimasg637No ratings yet
- Hall MicroPower High Speed DrillDocument40 pagesHall MicroPower High Speed DrillwaculaNo ratings yet
- Programming The World Wide Web by Robert W SebestaDocument6 pagesProgramming The World Wide Web by Robert W SebestadukeNo ratings yet
- Modbus Controller (2080 Serialisol)Document2 pagesModbus Controller (2080 Serialisol)Piyush KumarNo ratings yet
- Daily Tasks in Oracle RDSDocument17 pagesDaily Tasks in Oracle RDSganesh_24No ratings yet
- Landsat 8 Quality Assessment BandDocument4 pagesLandsat 8 Quality Assessment BandFajar RahmawanNo ratings yet
- Flash Memory Research PaperDocument6 pagesFlash Memory Research Papergw11pm8h100% (1)
- Unit 7 Short Test 2B: GrammarDocument1 pageUnit 7 Short Test 2B: GrammarMinh TruongNo ratings yet
- W Wor Orks Ksho Hop 08 P08 Iintrod Ntroductio Uction To Proce N To Process Ss O Opt Ptim Imiza Izati Tion On Iin NG Gams Ams® ®Document29 pagesW Wor Orks Ksho Hop 08 P08 Iintrod Ntroductio Uction To Proce N To Process Ss O Opt Ptim Imiza Izati Tion On Iin NG Gams Ams® ®franko2422No ratings yet
- Developing Materials For Students Listening SkillsDocument25 pagesDeveloping Materials For Students Listening SkillsMikha100% (2)
- 07-Interprocess CommunicationDocument14 pages07-Interprocess Communicationmuhammad iftikharNo ratings yet
- Mobile Banking ServicesDocument11 pagesMobile Banking ServicesDiksha SadanaNo ratings yet
- Shimadzu Mobiledart Evolution Installation Manual - rv2Document554 pagesShimadzu Mobiledart Evolution Installation Manual - rv2Jhairzito RM83% (6)
- Shi Et Al. - 2023 - SFCGDroid Android Malware Detection Based On SensDocument10 pagesShi Et Al. - 2023 - SFCGDroid Android Malware Detection Based On Senstrinhhtk.5903No ratings yet
- St. Francis School, ICSE: Koramangala, Bengaluru-34Document2 pagesSt. Francis School, ICSE: Koramangala, Bengaluru-34Sreedhar ReddyNo ratings yet
- Electrically Alterable ROM (EAROM)Document6 pagesElectrically Alterable ROM (EAROM)Zulhelmi NasirNo ratings yet
- UGE1 Comparison and ContrastDocument7 pagesUGE1 Comparison and ContrastShanen May Apostol Ampatin IINo ratings yet
- Operation/Technical ManualDocument64 pagesOperation/Technical ManualBilal AloulouNo ratings yet
- GBCrib Sheet 000129Document4 pagesGBCrib Sheet 000129mistershrubberNo ratings yet
- National Institute of Technology, Rourkela: M.I.S. Live Project On ZareeDocument7 pagesNational Institute of Technology, Rourkela: M.I.S. Live Project On ZareeAkb BhanuNo ratings yet
- DX DiagDocument42 pagesDX DiagunnuNo ratings yet
- Crome969 HeartwoodDocument8 pagesCrome969 HeartwoodAlcatrazz Albion OnlineNo ratings yet
- Sprac 51Document16 pagesSprac 51fabiolmtNo ratings yet
- Caring Means Sharing - Barney Wiki - FandomDocument4 pagesCaring Means Sharing - Barney Wiki - FandomchefchadsmithNo ratings yet
- Const RobotDocument16 pagesConst RobotBhargavi PatilNo ratings yet
- ADCDocument5 pagesADCnazmulNo ratings yet
- SDR Mapping Design - SDRmap Installation On WinNTDocument2 pagesSDR Mapping Design - SDRmap Installation On WinNTQaafqqNo ratings yet
- DH-DVR0404LE-AS/AN: 4 Channel Entry-Level Simple 1U Standalone DVRDocument2 pagesDH-DVR0404LE-AS/AN: 4 Channel Entry-Level Simple 1U Standalone DVRAllmir GrgicNo ratings yet
- Tango Manual 92Document267 pagesTango Manual 92mateykoNo ratings yet
- Combinatorics: The Fine Art of Counting: Week Three SolutionsDocument10 pagesCombinatorics: The Fine Art of Counting: Week Three SolutionsSandeep SharmaNo ratings yet
- Lab Manual: MCT-334L Industrial AutomationDocument38 pagesLab Manual: MCT-334L Industrial AutomationAhmed ChNo ratings yet