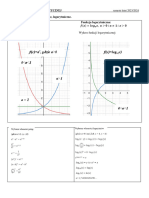
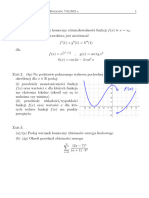
You might also like
- 2019 1 Klasowka Kl1 Funkcjewlasnosci ZP Ab Wer2Document5 pages2019 1 Klasowka Kl1 Funkcjewlasnosci ZP Ab Wer2Krzysiek Kaczmarek100% (1)
- Listaam1 z2223Document19 pagesListaam1 z2223jestemspokoziomek2No ratings yet
- Zadanie 26 I 27Document2 pagesZadanie 26 I 27Agata PrzyżyckaNo ratings yet
- Klasowki Kl2 Ulamki Algebraiczne Rownania Wymierne 3 A ZPDocument2 pagesKlasowki Kl2 Ulamki Algebraiczne Rownania Wymierne 3 A ZPOla GorskaNo ratings yet
- 02 M Wstep Cwiczenia 2Document2 pages02 M Wstep Cwiczenia 2Вадим ГорныйNo ratings yet
- Mat 1 Równania I Nierówności Kwadratowe PomocDocument5 pagesMat 1 Równania I Nierówności Kwadratowe PomocwiktaNo ratings yet
- Listy 7 I 8Document6 pagesListy 7 I 8Skibiditoiler2137No ratings yet
- Funkcje 165 84h 2022Document17 pagesFunkcje 165 84h 2022ateamyNo ratings yet
- Zadania Odpowiedzi 1Document8 pagesZadania Odpowiedzi 1aleksandradabkowska0302No ratings yet
- Riesz TheoremsDocument12 pagesRiesz TheoremsRiyas P MusthafaNo ratings yet
- c6120646e163c58dbc2fd13ec3b296feDocument1 pagec6120646e163c58dbc2fd13ec3b296feZuzanna JurskaNo ratings yet
- Wda 1 PolyDocument2 pagesWda 1 Polymichal.lompart1No ratings yet
- Inf AM Egzamin Pop 2019-20Document2 pagesInf AM Egzamin Pop 2019-20filipfilxmNo ratings yet
- Funkcja Wykladnicza Sprawdzian2Document5 pagesFunkcja Wykladnicza Sprawdzian2zz testNo ratings yet
- Funkcja Wykł-SprawdzianyDocument2 pagesFunkcja Wykł-Sprawdzianyzz testNo ratings yet
- Zestaw Przygotowawczy Do Sprawdz. Rozdział 1Document2 pagesZestaw Przygotowawczy Do Sprawdz. Rozdział 1Maciej CichońNo ratings yet
- Arkusz 3Document6 pagesArkusz 300mvmNo ratings yet
- Lin IowaDocument1 pageLin IowaAniaNo ratings yet
- Funkcja HomograficznaDocument15 pagesFunkcja HomograficznaPaulina WolskaNo ratings yet
- Ćwiczenia 12 AlDocument3 pagesĆwiczenia 12 Aldgsmcg6pthNo ratings yet
- Am 1Document12 pagesAm 1jestemspokoziomek2No ratings yet
- Lista4k5 ZadWspRozneDocument2 pagesLista4k5 ZadWspRozneAleksanderNo ratings yet
- Funkcja WymiernaDocument2 pagesFunkcja WymiernaTwoComaNo ratings yet
- Inf AM Egzamin 2019-20Document2 pagesInf AM Egzamin 2019-20filipfilxmNo ratings yet
- Wlasnosci FunkcjiDocument11 pagesWlasnosci FunkcjiDariusz PasterzNo ratings yet
- Funkcje Wymierne GR IIDocument12 pagesFunkcje Wymierne GR IIIgastempino2.plNo ratings yet
- Zadania Do Wykładu 1Document2 pagesZadania Do Wykładu 1asiaczyz88No ratings yet
- Inf ME Egzamin Pop 2019-20Document2 pagesInf ME Egzamin Pop 2019-20filipfilxmNo ratings yet
- Wiad-294343-Funkcj Log - ĆWDocument1 pageWiad-294343-Funkcj Log - ĆWzz testNo ratings yet
- Pula Ver 05a2Document17 pagesPula Ver 05a2karolinaa.trybalaNo ratings yet
- Calculus Exercises 1Document2 pagesCalculus Exercises 1MikeNo ratings yet
- Kol3 WitDocument3 pagesKol3 WitglebNo ratings yet
- Anma 13Document2 pagesAnma 13andrzejstepan10No ratings yet
- Sprawdzian - Funkcja LiniowaDocument3 pagesSprawdzian - Funkcja LiniowaKinga BazakNo ratings yet
- Jak Zdać Pierwsze Semestry Matematyki Na Studiach TechnicznychDocument13 pagesJak Zdać Pierwsze Semestry Matematyki Na Studiach TechnicznychtrixerNo ratings yet
- 4.2.miejsce Zerowe I Postać Iloczynowa Funkcji KwadratowejDocument4 pages4.2.miejsce Zerowe I Postać Iloczynowa Funkcji Kwadratowejkamilaw110604No ratings yet
- 1.2. FunkcjeDocument3 pages1.2. FunkcjekarolineNo ratings yet
- PochodneDocument6 pagesPochodnePiotr BińczykNo ratings yet
- Lista - 4 - Elementy TopologiiDocument1 pageLista - 4 - Elementy TopologiiAlicja RadajewskaNo ratings yet
- Praca Kontrolna Z Zakresu Sem3Document1 pagePraca Kontrolna Z Zakresu Sem3kasiapogodaNo ratings yet
- Funkcje MaturapdstDocument5 pagesFunkcje MaturapdstJoanna JaskółowskaNo ratings yet
- 2019 1 Klasowka kl1 Wlasnosci Funkcji ZR B Wer1Document2 pages2019 1 Klasowka kl1 Wlasnosci Funkcji ZR B Wer1arek.przyslawski7756No ratings yet
- Analiza 2Document12 pagesAnaliza 2Klaudia KalinowskaNo ratings yet
- Zestaw 1Document2 pagesZestaw 1Przemysław KomosińskiNo ratings yet
- 01 Algorytm Arytmetyka ZadaniaDocument2 pages01 Algorytm Arytmetyka ZadaniaPrzemysław KomosińskiNo ratings yet
- Logarytmy 2Document2 pagesLogarytmy 2PIOTERRNo ratings yet
- Klasowki Odpowiedzi Kl2 Ulamki Algebraiczne Rownania Wymierne Zp-1Document6 pagesKlasowki Odpowiedzi Kl2 Ulamki Algebraiczne Rownania Wymierne Zp-1Ola GorskaNo ratings yet
- Ulamki AlgebraiczneDocument15 pagesUlamki AlgebraiczneKamila WieczorekNo ratings yet
- Analiza 13tygodni MWMDocument15 pagesAnaliza 13tygodni MWMAdamsNo ratings yet
- UntitledDocument1 pageUntitledMagdalena KątnaNo ratings yet
- MSiD 4a Metody Numeryczne Wstęp Optymalizacja W KierunkuDocument39 pagesMSiD 4a Metody Numeryczne Wstęp Optymalizacja W Kierunkukornelkaw2No ratings yet
- Inf AM Egzamin 2021-22Document2 pagesInf AM Egzamin 2021-22filipfilxmNo ratings yet
- Zagadnienie Przedstawiania MetrykiDocument14 pagesZagadnienie Przedstawiania MetrykiOliwier UrbańskiNo ratings yet
- Test Funkcja WykładniczaDocument1 pageTest Funkcja Wykładniczazz testNo ratings yet
- Funkcje WymierneDocument2 pagesFunkcje WymierneBeata SurówkaNo ratings yet
- Funkcja Kwadratowa TestDocument2 pagesFunkcja Kwadratowa Testliliannakjs0% (1)