You might also like
- Strange Constellations (Constellation) : OIS2022 - Round 4Document2 pagesStrange Constellations (Constellation) : OIS2022 - Round 4mohaNo ratings yet
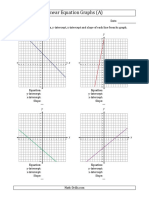
- Algebra Systems of Equations Solve by Graphing All Quadrants 001.1429194254Document2 pagesAlgebra Systems of Equations Solve by Graphing All Quadrants 001.1429194254ben2099No ratings yet
- AssignmentDocument50 pagesAssignmentSabih SiddiqiNo ratings yet
- BD S1e08Document55 pagesBD S1e08BAFSNo ratings yet
- Week 1 HomeworkDocument2 pagesWeek 1 HomeworkJeffrey YangNo ratings yet
- Wks. 2.2 - Standard Form of Quad EqDocument2 pagesWks. 2.2 - Standard Form of Quad EqSusie GreenNo ratings yet
- Finding The Equation of A Straight LineDocument1 pageFinding The Equation of A Straight Linethe tri namNo ratings yet
- Pre-Assessment in Module 1Document4 pagesPre-Assessment in Module 1Ralph Rexor Macarayan BantuganNo ratings yet
- Colorful Number Wall Mathematics PosterDocument4 pagesColorful Number Wall Mathematics PosterNURUL SYAHIRAH BINTI MOHD ZOLKIPLI KPM-GuruNo ratings yet
- D1 Linear ProgrammingDocument7 pagesD1 Linear ProgrammingDavid NallapuNo ratings yet
- TransformationsDocument9 pagesTransformationsapi-661751964No ratings yet
- 2009-03-31 Function Transformation, Part IVDocument5 pages2009-03-31 Function Transformation, Part IVsamjshahNo ratings yet
- Algebra Systems of Equations Solve by Graphing All Quadrants Slopeintercept 001Document2 pagesAlgebra Systems of Equations Solve by Graphing All Quadrants Slopeintercept 001api-448001324No ratings yet
- Tema S 1Document9 pagesTema S 1RoOby BăNo ratings yet
- Answers To Practice Book Exercises: 12 Tessellations, Transformations and LociDocument4 pagesAnswers To Practice Book Exercises: 12 Tessellations, Transformations and LociDhyaneshwaran VaitheswaranNo ratings yet
- Non-Linear 3Document4 pagesNon-Linear 3sleepyvibez204No ratings yet
- Section P.1 Section P.2 Section P.3 Section P.4Document22 pagesSection P.1 Section P.2 Section P.3 Section P.4AROSNo ratings yet
- Straight Lines: by The End of This Lesson You Will: - Plot Linear FunctionsDocument9 pagesStraight Lines: by The End of This Lesson You Will: - Plot Linear FunctionsMissMillerNo ratings yet
- Quadratic Forms Intercept FormDocument4 pagesQuadratic Forms Intercept FormdevikaNo ratings yet
- Circle Equ GraphDocument2 pagesCircle Equ GraphAashnaNo ratings yet
- CirculosDocument2 pagesCirculosluis martinezNo ratings yet
- Chapter P Preparation For CalculusDocument44 pagesChapter P Preparation For CalculusAsad MehboobNo ratings yet
- Reflections On A Coordinate PlaneDocument2 pagesReflections On A Coordinate PlaneGabriel ChicasNo ratings yet
- Reflectiom GraphingDocument2 pagesReflectiom GraphingMachelMDotAlexanderNo ratings yet
- COE4TL4 Lecture17Document13 pagesCOE4TL4 Lecture17Anonymous hDKqasfNo ratings yet
- Name: Teacher: Date: ScoreDocument2 pagesName: Teacher: Date: ScoreysidrayNo ratings yet
- Line ReviewDocument3 pagesLine ReviewsamjshahNo ratings yet
- Linear Functions Review PacketDocument9 pagesLinear Functions Review PacketMarisa Vetter0% (1)
- Grid Level1 1Document2 pagesGrid Level1 1api-256386911No ratings yet
- Review Packet #2 - Polynomials: FX X XDocument4 pagesReview Packet #2 - Polynomials: FX X XCharles DuttaNo ratings yet
- The F Test or AnovaDocument5 pagesThe F Test or AnovaCynthia Gemino BurgosNo ratings yet
- Graphing Quadratic Functions in Standard Form: Example: GraphDocument2 pagesGraphing Quadratic Functions in Standard Form: Example: GraphCherry Ann M NaboNo ratings yet
- Non-Linear Function & Application: (Chapter 4)Document36 pagesNon-Linear Function & Application: (Chapter 4)Steven GifferdNo ratings yet
- 国际象棋中局基本战术及战术组合 (PDFDrive)Document12 pages国际象棋中局基本战术及战术组合 (PDFDrive)Kho Chin KingNo ratings yet
- Resource Coordinate GraphingDocument33 pagesResource Coordinate Graphingmlamb2011No ratings yet
- Systems Pre AssessmentDocument3 pagesSystems Pre Assessmentapi-438162770No ratings yet
- Range Variable Iteration and Multidimensional ArraysDocument2 pagesRange Variable Iteration and Multidimensional ArrayssouravNo ratings yet
- Algebra Graph Linear Slope Intercept Find Equation 001.1579267157Document2 pagesAlgebra Graph Linear Slope Intercept Find Equation 001.1579267157contactsulaiman1No ratings yet
- 5950 2019 Assignment 7 Spearman RhoDocument1 page5950 2019 Assignment 7 Spearman RhoNafis SolehNo ratings yet
- MCR3U Unit 3 Notes - FunctionsDocument20 pagesMCR3U Unit 3 Notes - FunctionsShanaz ParsanNo ratings yet
- Linear Equation in Two Variables: Lesson 5.2Document38 pagesLinear Equation in Two Variables: Lesson 5.2Marvelyn Reforma VillarNo ratings yet
- AnswersDocument6 pagesAnswerspvqyhzfgy6No ratings yet
- Stat 135 Le 1 Samplex 002Document3 pagesStat 135 Le 1 Samplex 002ludhoisaloonieNo ratings yet
- Transformations IgcseDocument89 pagesTransformations IgcseRNo ratings yet
- Developmental Mathematics 1st Edition Blitzer Test Bank 1Document88 pagesDevelopmental Mathematics 1st Edition Blitzer Test Bank 1jospeh100% (27)
- (MODUL) Penjelmaan (Form 2, 3 & 5)Document27 pages(MODUL) Penjelmaan (Form 2, 3 & 5)Hafizah67% (3)
- 8.1-8.3 Quiz ReviewDocument10 pages8.1-8.3 Quiz ReviewMark Abion ValladolidNo ratings yet
- Ala2 SSM PDFDocument96 pagesAla2 SSM PDFVishalkumar BhattNo ratings yet
- Math 1 EOC Group Practice Test 2bDocument10 pagesMath 1 EOC Group Practice Test 2bmtahNo ratings yet
- Algebra Find Slope Y-Intercept X-Intercept Equation From Graph All.1579267146Document20 pagesAlgebra Find Slope Y-Intercept X-Intercept Equation From Graph All.1579267146Hardik ViraNo ratings yet
- Pract 1 Est IngDocument1 pagePract 1 Est IngBrandon MartinezNo ratings yet
- 1 Larson SolDocument134 pages1 Larson SolMike MontoyaNo ratings yet
- Quiz Gen MathDocument1 pageQuiz Gen MathChris MineNo ratings yet
- Selected ResponceDocument3 pagesSelected Responceapi-458193889No ratings yet
- Algebra Find Y-Intercept From Graph All.1579267157Document20 pagesAlgebra Find Y-Intercept From Graph All.1579267157Hardik ViraNo ratings yet
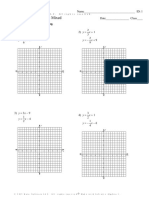
- Reivewsystems of Equations Mixed 1klhponDocument4 pagesReivewsystems of Equations Mixed 1klhponapi-327041524No ratings yet
- Year 4 Worksheet With AnswerDocument6 pagesYear 4 Worksheet With Answerpvqyhzfgy6No ratings yet
- Dilations On The Coordinate PlaneDocument2 pagesDilations On The Coordinate PlaneGabriel ChicasNo ratings yet
- KNN TheoryDocument11 pagesKNN Theorygecol gecolNo ratings yet
- Sheet7 SolDocument21 pagesSheet7 SolHerman Deulieu NoubissieNo ratings yet
- Sheet10 SolutionDocument14 pagesSheet10 SolutionHerman Deulieu NoubissieNo ratings yet
- Sheet9 SolDocument11 pagesSheet9 SolHerman Deulieu NoubissieNo ratings yet
- Sheet8 SolDocument14 pagesSheet8 SolHerman Deulieu NoubissieNo ratings yet
- Sheet6 SolutionDocument17 pagesSheet6 SolutionHerman Deulieu NoubissieNo ratings yet
- Sheet2 SolDocument9 pagesSheet2 SolHerman Deulieu NoubissieNo ratings yet
- Sheet1 SolDocument10 pagesSheet1 SolHerman Deulieu NoubissieNo ratings yet
- Course Information Booklet: FIRST SEMESTER (A.Y 2020-2021) Ged0113: The Filipino in The Contemporary WorldDocument48 pagesCourse Information Booklet: FIRST SEMESTER (A.Y 2020-2021) Ged0113: The Filipino in The Contemporary WorldcasperNo ratings yet
- Exercise 7 Mineral Oil EmulsionDocument3 pagesExercise 7 Mineral Oil EmulsionFreya AvellanoNo ratings yet
- Hospital Staff List To Be UpdatedDocument4 pagesHospital Staff List To Be UpdatedHiteshNo ratings yet
- OverthinkingDocument9 pagesOverthinkinghabibatullah nur hanifahNo ratings yet
- Engineering Maths 4 SyllabusDocument3 pagesEngineering Maths 4 SyllabusRanjan NayakNo ratings yet
- Effectiveness of Service Delivery in Panchayat - Experience From ManipurDocument12 pagesEffectiveness of Service Delivery in Panchayat - Experience From Manipurlhingneinemhaokip_38No ratings yet
- Jovanscha Qisty Adinda Fa: Personal History Career HistoryDocument1 pageJovanscha Qisty Adinda Fa: Personal History Career HistoryJovanscha QistyNo ratings yet
- Exploratory Data Analysis (EDA) - 1Document3 pagesExploratory Data Analysis (EDA) - 1Kiran Gupta100% (1)
- Analisis Kandungan Vitamin C Bahan Makanan Dan Minuman Dengan Metode IodimetriDocument9 pagesAnalisis Kandungan Vitamin C Bahan Makanan Dan Minuman Dengan Metode IodimetriABDULLAH MHS ULMNo ratings yet
- Grim Character ConceptDocument1 pageGrim Character ConceptJhansenNo ratings yet
- Lecture Notes On Climatology: Integrated Meteorological Training CourseDocument90 pagesLecture Notes On Climatology: Integrated Meteorological Training CourseDasSonam100% (1)
- CHEM1701-lab3-202341 - 202341.12623-CHEM-1701-08 - PRE-HEALTH CHEMISTRY IDocument1 pageCHEM1701-lab3-202341 - 202341.12623-CHEM-1701-08 - PRE-HEALTH CHEMISTRY IMartha ChalmenageNo ratings yet
- Radar Systems Engineering - MATLAB & SimulinkDocument2 pagesRadar Systems Engineering - MATLAB & SimulinkAdfgatLjsdcolqwdhjpNo ratings yet
- I Miss Mu Bad HabitsDocument4 pagesI Miss Mu Bad HabitsCrullClashNo ratings yet
- Equations of Order One: Differential Equations Module 2ADocument5 pagesEquations of Order One: Differential Equations Module 2AJuvilee RicoNo ratings yet
- Iv Ii Eiam - Unit I PDFDocument11 pagesIv Ii Eiam - Unit I PDFNaga SekharNo ratings yet
- Positioning Ceramic Foam Filters in Gating System For Casting Alloy FiltrationDocument8 pagesPositioning Ceramic Foam Filters in Gating System For Casting Alloy FiltrationSiddharth GuptaNo ratings yet
- Abs 0678Document11 pagesAbs 0678Jorge OrtegaNo ratings yet
- Richard Heck in MemoriamDocument24 pagesRichard Heck in MemoriamTonie Jane SabadoNo ratings yet
- IEOR 6711: Stochastic Models I Fall 2003, Professor Whitt Class Lecture Notes: Tuesday, November 18. Solutions To Problems For DiscussionDocument2 pagesIEOR 6711: Stochastic Models I Fall 2003, Professor Whitt Class Lecture Notes: Tuesday, November 18. Solutions To Problems For Discussionscanny16No ratings yet
- A Design of The Searcher Circuit: Sensing Channel Type: ProjectedDocument2 pagesA Design of The Searcher Circuit: Sensing Channel Type: ProjectedHu GyNo ratings yet
- Delegation of Authority Lecture Principles of ManagementDocument34 pagesDelegation of Authority Lecture Principles of Management2021-SC040 PRANAYSAKHARAMDHANDENo ratings yet
- 2 TLE-CSS - SOP FinalDocument4 pages2 TLE-CSS - SOP FinalMam Lorna Es GeeNo ratings yet
- Đề HSG Tiếng Anh 11 - 2021Document7 pagesĐề HSG Tiếng Anh 11 - 2021Vân Anh OnceNo ratings yet
- ZnshinesolarDocument4 pagesZnshinesolarVedant KNo ratings yet
- School MemoDocument2 pagesSchool MemoMA. KRISTINA HIPOSNo ratings yet
- Building A Learning Culture That Drives Business ForwardDocument11 pagesBuilding A Learning Culture That Drives Business ForwardPedroNo ratings yet
- Learning OrganizationDocument4 pagesLearning OrganizationAbdullah AzizNo ratings yet
- S Siva Kishore Project - BADocument5 pagesS Siva Kishore Project - BAosuri sudheer kumarNo ratings yet
- EXXXX 080 002, GGA and GTGS, Rev.4Document1 pageEXXXX 080 002, GGA and GTGS, Rev.4Mohamed HamdallahNo ratings yet